
Google Search, the world’s most widely used search engine, relies on a complex infrastructure and custom development environments. We explore these systems, with their sometimes explicit, often colorful names, using information from a variety of sources: the Content Warehouse API leak, antitrust trial exhibits, public presentations by Google engineers, and testimonials from former employees (CVs, LinkedIn profiles, blogs, HackerNews forums, etc.).
Disclaimer: This article is based solely on publicly available information. While we strive for accuracy, our understanding of Google’s systems involves interpretation and approximation. Claims not supported by multiple documented sources should be treated as speculative. No insider information was used in the preparation of this article.
The Google development environment
Internal environments
Among the first tools revealed in the leak was Google’s in-house version control system (VCS), Piper, which is analogous to Git. The leak also contained references to Blaze, Google’s internal build tool that was later open-sourced in 2015 as Bazel, though notably absent was any mention of their testing system, Forge. Additionally, traces of Borg, the SRE (Site Reliability Engineering) team’s production system, and its node management were found—an example of which can be seen below in the Context Queries Rewrite operation:

While Google is known for developing Go, C++ remains the predominant programming language in their infrastructure. Java is also widely used, followed by Python to a lesser extent. The most commonly encountered file extensions are:
- .cc and .h for C++
- .java for Java
- .proto for Protocol Buffers (protobuf)
Google’s internal services communicate through Stubby, their proprietary remote procedure call (RPC) infrastructure, which was later adapted into the open-source gRPC framework.
Data exchange between the engine’s various systems relies on protobuf (Protocol Buffers), a Google-developed serialization format designed to outperform JSON by being simpler, more compact, faster, and less ambiguous.
Regarding software for “machine management”, storage and databases, there’s no mention of Colossus, but there are instances of Spanner, Bigtable, SSTable, Blobstore, Borg or Chubby working in tandem with Colossus. As a reminder, Colossus is a cluster-level file system, the successor to the Google File System (GFS).
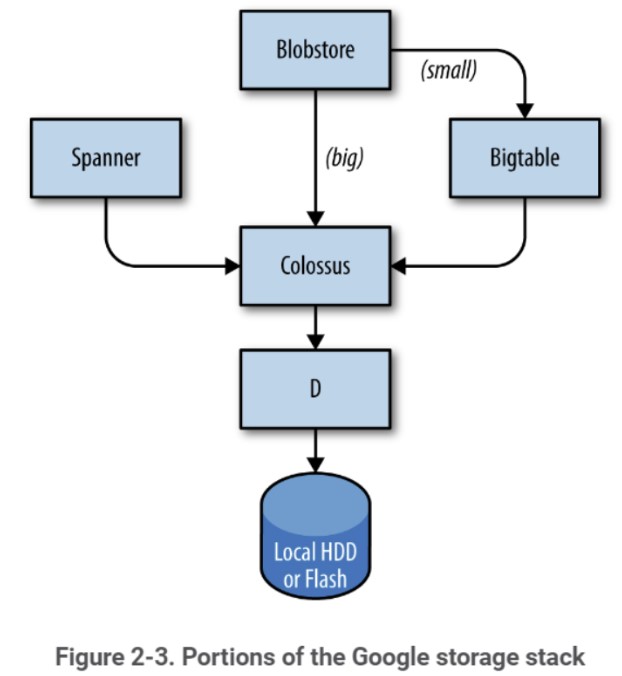
Neither Percolator nor Caffeine appear in the leak. While MapReduce is mentioned occasionally, Google has since replaced it with Dataflow (developed using Flume and Millwheel – two systems also absent from the Leak API).
Monorepo Google3
At the core of Google’s development environment is a pivotal concept: the monorepo—a single repository that houses the source code for the majority of Google’s products, except Chrome and Android, which are managed separately. This expansive repository includes code for Search, YouTube, Maps, Assistant, Lens, … and is internally known as Google3. Nearly all Google engineers have access to this shared codebase. While unconventional for a company of Google’s scale, this monolithic approach offers several distinct advantages:
- Ease of collaboration between teams
- Uniformity of tools and processes
- Large-scale refactoring possible
Only a small percentage of the code (around 0.1%) is isolated for confidentiality, primarily concerning anti-spam measures. The small part reserved for a few teams would be called HIP for “High-value Intellectual Property”, where we should find, for instance, Nsr or PageRankNS.
The number of references to the repository is significant in the leak, providing a better understanding of both the overall structure of the code and clues as to whether a particular component belongs to a specific environment.
We have extracted and compiled the quality branch of the google3 monorepo from the Google leak:

And here’s a sample of what you’ll find in other branches:

Internal best practices require that all code is documented within Google’s in-house wiki, accessible through the company’s go/ links, which appear frequently in the leak. Unfortunately, to access it, you need to be a Google engineer ^^.

By 2015, the Google3 monorepo had already reached 86 TB of data across two billion lines of code, with a highly intricate dependency graph. The group’s 25,000 engineers were releasing 40,000 commits a day! If you’d like to delve deeper into this subject, we highly recommend reading this document: Why Google Stores Billions of Lines of Code in a Single Repository (PDF)
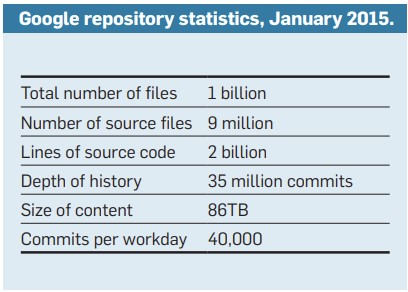
In other words, the leak we have access to represents only a tiny fraction of Google’s code… but it’s still exceptionally revealing to glimpse this small window into the structure of the repository.
Let’s now turn our attention to the many other systems discovered thanks to the Google leak of May 2024 that enable the engine to deliver its famous results pages. We’ll start with the crawl phase and work our way through the main intermediate systems to the user query.
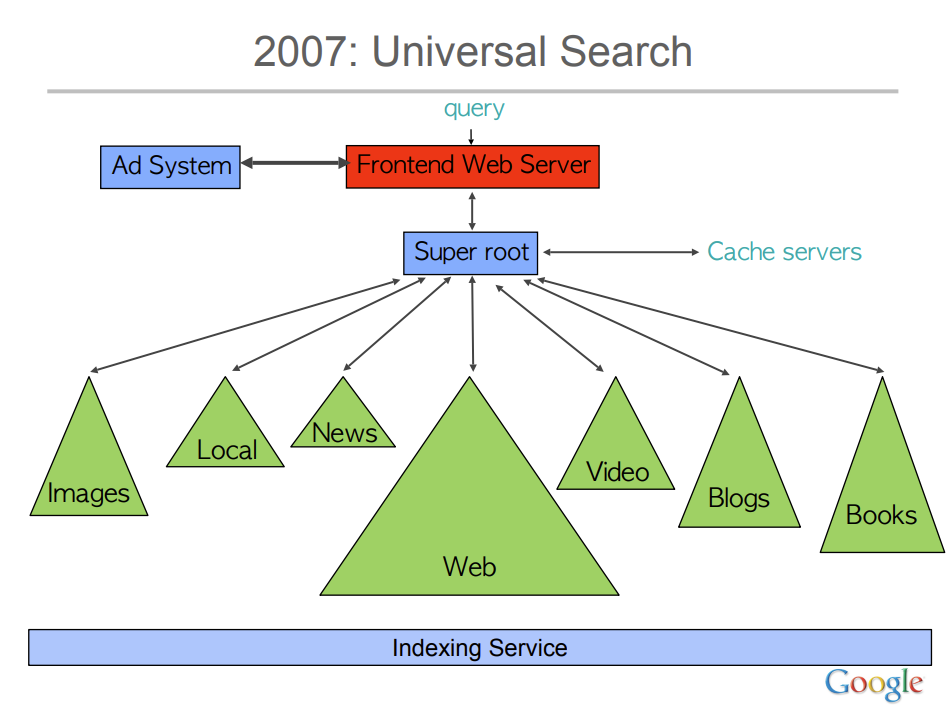
Google Search systems in an infographic
SEOs have already come up with a number of proposals for mapping Google Search’s infrastructure, two of which are particularly well thought-out:
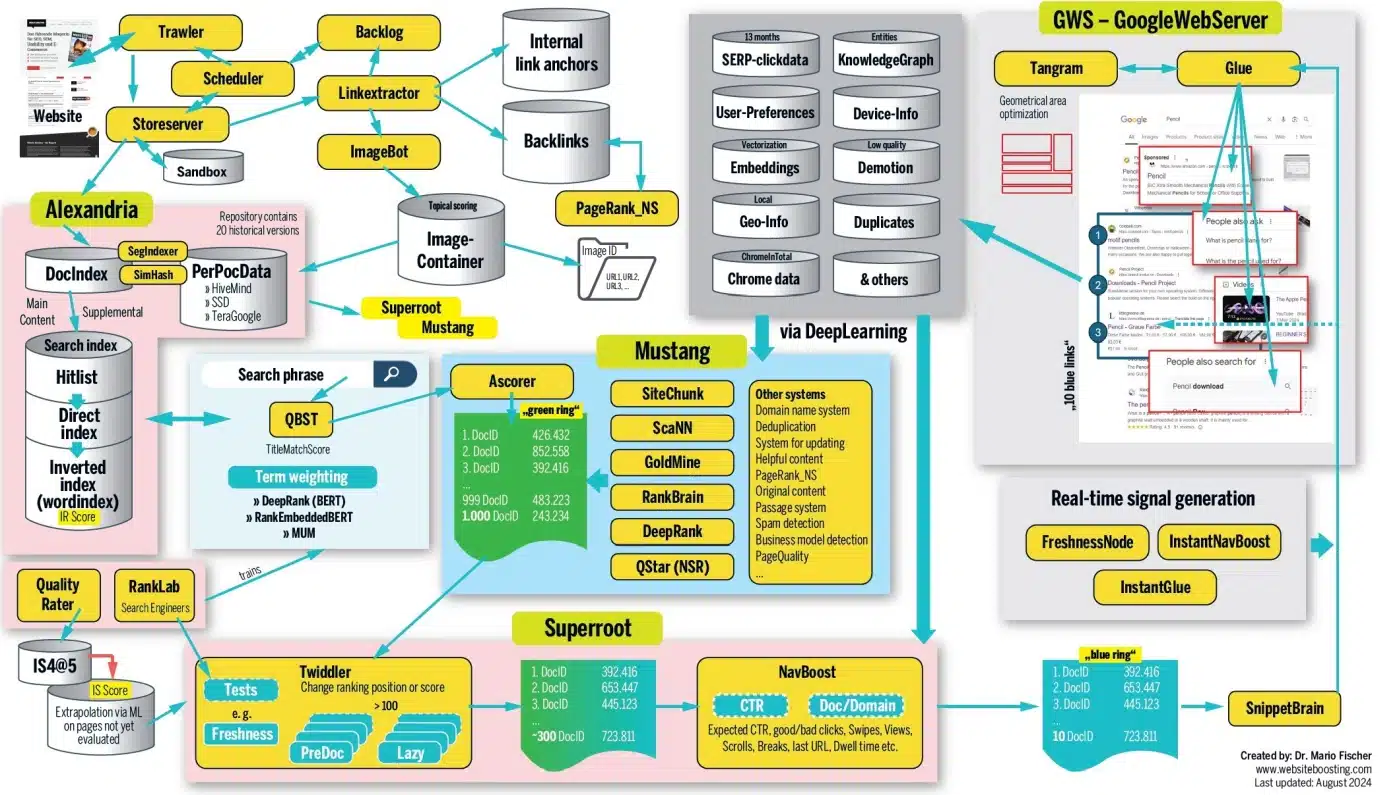
A first published by Mario Fischer on Search Engine Land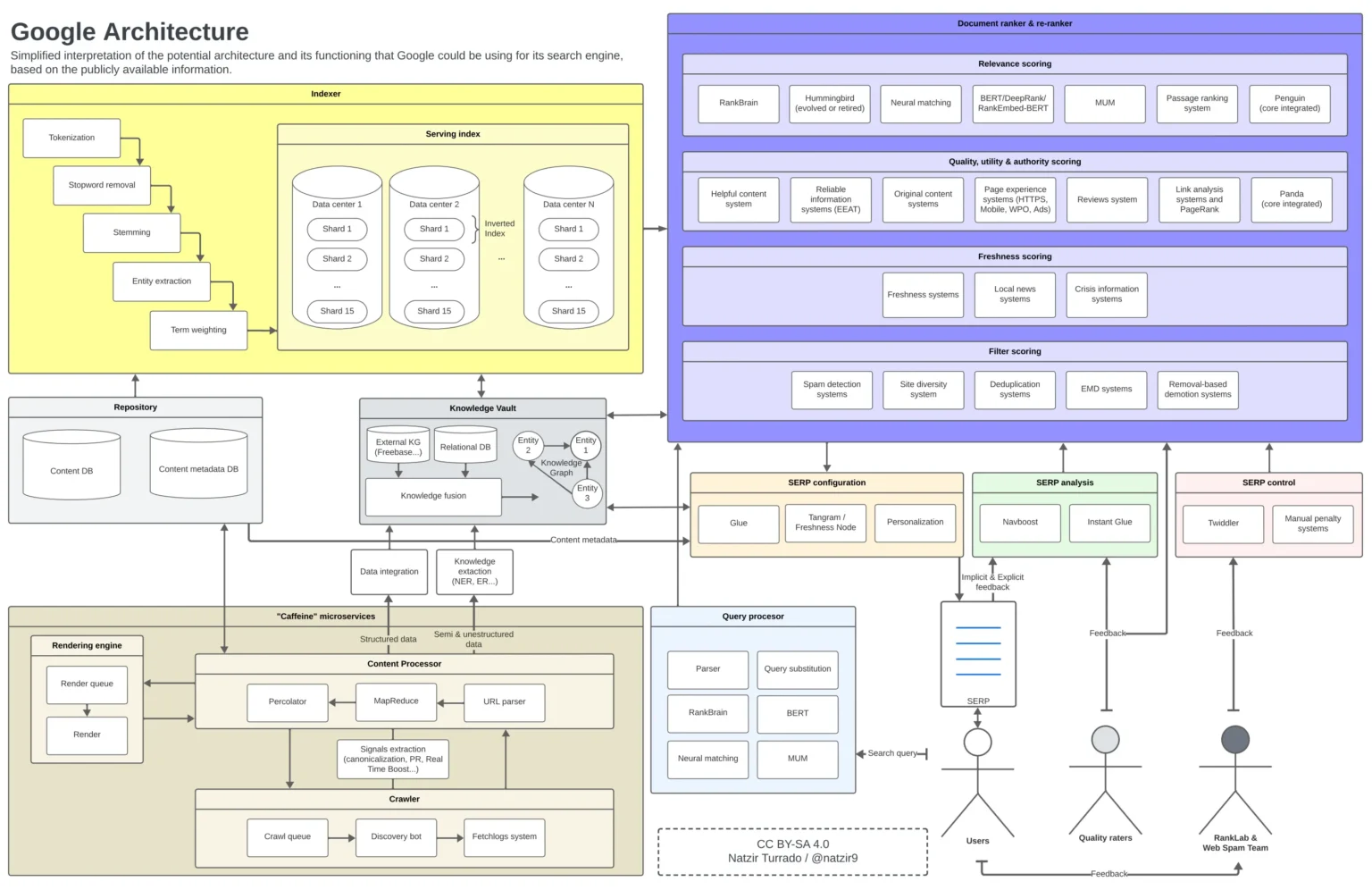
A second published by Natzir Turrado on his personal website
We propose a new representation, this time organized in two parts:
- On the top: what is implemented off-line (crawl time), in particular everything concerning data discovery, extraction, parsing, annotation and indexing.
- At the bottom: what is activated at query time, particularly query interpretation, results page generation, and user behavior analysis for reranking and training purposes.
- In between are the “merging / information retrieval” mechanisms that bridge the gap between the data aggregated at the indexing level and the serving phase triggered by each user query.
Please note that we have excluded Youtube, Assistant, Map, Lens, etc. from this diagram, keeping only Search, for simplicity’s sake.
You can click on any part of the infographic to go directly to the corresponding explanation.
The different stages
The architecture of Google Search can be divided into several main stages:
- 1 – Search / retrieval / analysis and rendering
- 2 – Indexing
- 3 – Annotation / Embedding & Topicality
- 4 – Information fusion and retrieval
- 5 – Evaluation & Quality / Grading
- 6 – Serving: re-ranking, query expansion, training data…
1 – CRAWL / FETCH / PARSING & RENDERING
Trawler is Google’s primary crawling & fetching system. It is responsible for fetching web pages, managing redirects, HTTP headers, SSL certificates and respecting robots.txt rules. In addition, it collects detailed statistics for each retrieved page.
Harpoon, on the other hand, acts as a client interface to Trawler and enables other services to trigger fetches on demand via Trawler, in the event of a URL inspection request via the GSC, for example. Both devices are aptly named ^^.
Once a page has been fetched, Trawler returns detailed information about the fetch, including download time and content type. After this, a rendering step can occur. Since WebKit became Apple-owned in 2013, Google now utilizes Blink, through Chromium, to execute JavaScript, apply CSS, and capture the page’s final state. This process includes generating page screenshots and gathering metrics on rendering quality. The SnapshotTextNode schema reveals that Google goes even further, creating snapshots of various text blocks on a page and identifying font size, links, and visual separators within the page.

The crawl system also incorporates a number of special features:
- geo-crawl, to simulate local access from different geographic regions,
- caching, which avoids the need to retrieve unchanged content,
- and load management with WebIO.
WebIO (Web Input Output) is the latest system for measuring and managing crawl load. According to leaks, it first appeared in 2023. Recent public statements from Google indicate that the search engine is undergoing a significant overhaul to conserve its crawling and indexing resources, so it’s not surprising to see this area actively evolving.

The entire crawl system is driven by numerous metrics and models, allowing it to skip crawling a page if there is a high probability that it is of low quality or duplicate content.
Once pages have been crawled and analyzed, they must be efficiently organized to enable rapid retrieval by the search engine. This is where Google’s indexing system comes into play.
2 – INDEXING
In a Q&A episode in 2021, Gary Illyes told us about the use of a tier index.

This information is reflected more concretely in the Google API:

The serving tiers of the Google index:
- Base : This is the fastest level, often associated with RAM systems. It contains the most frequently consulted, most relevant documents, and those that are regularly updated. These are the most important pages for both the user and the engine.
- Zeppelins : Intermediate level, generally stored on SSD disks, containing pages that are frequently consulted but less frequently updated than those in the Base level. The name “Zeppelin” – a World War 1 airship – may reflect the idea that these pages “move up and down” in terms of priority in the index, depending on their current relevance.
- Landfill : This level contains the majority of documents, stored on hard disks (HDDs) offering a good compromise between cost and capacity. Documents here are rarely updated, often of lower quality or less frequently consulted. This level is similar to a “landfill”, where documents are set aside, with little likelihood of being re-crawled.
Tiers document management:
Documents can be moved from one tier to another based on their quality, relevance, and update frequency. A document that loses popularity or updates less regularly might be moved to a lower tier. For example, a document at the Base level may gradually be downgraded to Zeppelins and eventually to Landfill.
Some indexing systems are used for specific types of document and content. Duplicate documents, for example, are stored in the WebMirror environment, while Ocean is specifically dedicated to indexing books, patents and other scientific documents.
The role of scaledSelectionTierRank
The scaledSelectionTierRank is a normalized score ranging from 0 to 32,767 that determines a document’s position within a specific index level. This score reflects both the document’s quality and its frequency of updates or consultations within a particular tier. Essentially, the higher a document’s score, the higher its selection level, improving its likelihood of appearing swiftly in search results. Maintaining a score aligned with its index position allows for easy multiplication with other compiled scores, enabling efficient ranking and retrieval of results.
Segindexer
Segindexer is the component responsible for categorizing documents across the three index levels before they are ultimately integrated into the databases. It also incorporates various document properties, such as title, token count, text start, and average font size.
TeraGoogle
TeraGoogle is Google’s secondary index, designed to handle the “long tail” of documents—those less frequently accessed but constituting the vast majority of Google’s data, likely over 95% of known documents. Created by Anna Peterson and Soham Mazumdar in 2006, TeraGoogle increased indexing capacity tenfold overnight, while reducing costs per search and per document by a factor of 50 compared to previous infrastructure. This efficiency gain was primarily achieved by using flash memory, which offers far greater flexibility than traditional RAM.
The advantage of using flash memory is that it allows for a much broader range of information to be utilized when scoring documents at query time, enabling more of the query to be considered as context. In contrast, a disk-based index requires term scores to be precomputed and limits their combination to basic arithmetic formulas.
In 2007, TeraGoogle was honored with Google’s Founders’ Award, a prestigious prize given by Google’s founders to outstanding in-house projects. When you search for niche information—such as in a rare, specialized academic article—it’s TeraGoogle handling the retrieval. Below are LinkedIn profiles of two engineers who contributed to TeraGoogle’s development, further corroborating some informations.
Alexandria
Alexandria is the main indexing system downstream of the document crawling, fetching, parsing and raw storage mechanisms. While the primary and secondary indexes contain all the documents crawled, Alexandria is more like an indexing pipeline as a distributed database. In addition to storing documents and their tokens, Alexandria compiles information such as crawl context, duplication, annotations, images, anchors and links, geolocation and other rendering metadata. It also makes use of Composite Doc data and feeds various DocJoiners. In essence, this system prepares the indexes for efficient use in the Information Retrieval (IR) and serving stages.
Example of information extracted from Alexandria to feed the DocJoiners:

In this attribute, we learn that Alexandria provides information on the quality of link anchors based on their source tier: anchors originating from Tiers1 – Base are considered high-quality, in contrast to those from Landfill, which are of lower quality.
Beyond pure indexing, Google must understand and categorize page content to deliver relevant results. This is the role of annotation and embedding systems.
3 – ANNOTATIONS / EMBEDDING & TOPICALITY
In parallel with indexing mechanisms, each word in every document is tokenized and vectorized by embedding engines like Starbust, Rene, or GFE (Generic Feature Vector). These vector databases are essential for machine learning algorithms and are also used by Gemini to generate AI Overviews.
The leaks reveal that Google doesn’t just vectorize tokens, phases, paragraphs or documents, but also entire sites or parts of sites (named “sitechunk”). The site2withEmbeddingEncoded attribute, for instance, appears in Nsr signals, while sitechunks are utilized across numerous other systems—for example, to identify chain stores in the Knowledge Graph and local search, or to assist SpamBrain in detecting spam. It’s exciting to see that Google – inventor of the famous Word2Vec – has also developed a Site2Vec.
This type of embedding helps determine the topical relevance of a document, sitechunk, or entire site. For example, the siteFocusScore attribute defines the extent to which a site is focused on a particular topic, while the siteRadius attribute identifies the extent to which pageEmbedding deviates from siteEmbedding, and therefore whether the site seems legitimate on a given topic. By default, a new page that has not yet been evaluated by Google is assigned a score corresponding to the average of the sitechunk to which it belongs.

This type of signal is probably behind Google’s latest announcement in October 2024 explaining that “Google aim to understand if a section of a site is independent or starkly different from the main content of the site. This helps us surface the most useful information from a range of sites.” An announcement that corresponds to the recent drop in ranking of the Fortunes and Forbes sites…
The leaks also include a number of annotation and extraction tools for building metadata for the various indexed documents.
For example, Goldmine, one of the main annotation pipelines, is capable of creating embeddings for text passages, analyzing sentiment, assigning geolocation scores, identifying entity mentions or assessing content readability. It often works in parallel with Raffia, another annotation pipeline, and SAFT (Structured Annotation Framework and Toolkit), which analyzes and structures documents to enrich the semantic understanding of content. SAFT segments texts into tokens, identifies named entities and establishes relationships between them to capture context. In addition to detecting measurements (quantities, units) and managing coreference (links between repeated mentions of the same entity), SAFT builds a complete semantic representation of documents, including links, titles, and complex relationships. Other annotation mechanisms are more specialized, such as Amarna for images, Nimble for media or Moka for products.
Links and their anchors also go through different extraction and labeling mechanisms. Internal (“local”) and external (“nonlocal”) links are analyzed by Google’s LinkExtractor and AnchorAccumulator.

For several years, Google has communicated that links are playing a diminishing role in its algorithm. We now understand why, as the majority of links are ultimately “dropped” and therefore not taken into account for ranking purposes. And even when they are retained, several limits in the number of link anchors (200, 1,000, 5,000 or 10,000) are applied before Google excludes them. This can have an impact, for example, on internal links with anchor variations or sitewide backlinks.


Google compiles numerous signals related to links, largely confirming what SEOs have observed empirically. For example, the following parameters appear to be considered:
– Links from quality press sites;
– Font size and context: terms placed before and after the anchor;
– Links transmit PageRank, but only the strongest ones: links below a certain PageRank level are weak or ignored;
– Links from expired domains are detected, as are many other types of potential SPAM;
– Some documents are protected from Penguin filters by the quality of their early anchors:![]()
– Etc.
In the end, it’s clear that a few links can make all the difference—provided they’re truly high-quality links.
Once the pages have been annotated and vectorized, Google needs to gather and organize all this information to make it usable for searches. This is where the merging and information retrieval mechanisms come into play.
4 – MERGING & INFORMATION RETRIEVAL (IR)
Docjoins and Composite Docs (CDocs)
Docjoins gather all the information known about each document. This information comes from indexing stages (index signals), parsing mechanisms, annotation and labeling pipelines, extraction, embedding and scoring systems.
DocJoins includes many Alexandria data elements, but not only:
- Document identifiers
- Clustering information
- Language and region data
- Link data (inbound and outbound)
- Scoring signals
- Roboting information (noindex, nofollow, …)
- Content expiration date
- URL information
Docjoiners are responsible for consolidating all the data Google has identified for each document. Overall, we have over 500 possible types of data. This information is mainly signals (compiled in Index Signal) or annotations. They center on the core concepts of Quality, Indexing, Repositories and Knowledge. They range from the most insignificant, such as breadcrumb quality, to the most important, such as NavBoost. Many data are aggregates that have already compiled multiple signals to be determined, like Nsr. This model – Model.Indexing Docjoiner Data Version – shows just how much information Google can compute for each document. It’s a very interesting list, as it foreshadows the data that is potentially actually used by Google, not necessarily only for ranking, but for all the engine’s mechanisms.
Docjoins are then used to generate CDocs: a Composite Document is therefore the first complete representation of a document after it has been indexed. It contains detailed and exhaustive information, including content, metadata and multiple indexing signals. This representation serves as the basis for further processing. Various types of CDoc are mentioned: cdoc.doc, cdoc.doc_images, cdoc.doc_videos, cdoc.properties, cdoc.anchor_stats.
Engineers need a thorough understanding of the corpus they work with to design signals that are meaningful to users. This is why indexes have traditionally been managed in silos—Web, Images, Videos, News, and so on—and some still are. With the multitude of signals developed to address a wide range of content types, there is always a risk of misinterpretation. For instance, traces of authorship appear in certain attributes, but these are specifically linked to press sites, scientific articles, or the now-defunct Blog Search. Contrary to recent claims, the leak does not indicate a special emphasis on authorship for standard websites. However, it remains valuable to enhance author pages, as quality raters examine them to assess authority and expertise.
MDU and PerDocData
MDUs represent a more optimized and processed version of the data contained in CDocs. Designed for rapid retrieval and processing at search time, they are generated and populated in real time. Among other things, they contain a subset of the CDoc’s information, selected and formatted for fast processing.
PerDocData is a dynamic metadata container, implemented as a protobuf. Unlike CDoc, which contains both content and signals and serves a static function in the overall indexing and ranking pipeline, PerDocData is temporary, focusing mainly on signals and scores. These files are generated and utilized on the fly during a query, decoded in Mustang, and then deleted. Different types of PerDocData are used for web pages, images, videos, and other content types.
Among the information embedded by PerDocData are :
- Spam and quality scores
- Language and regional information
- Content freshness and age signals
- Information on entities and subjects
- Specific data for videos, images, mobile applications, etc.
- Signals for various Google rankings and algorithms
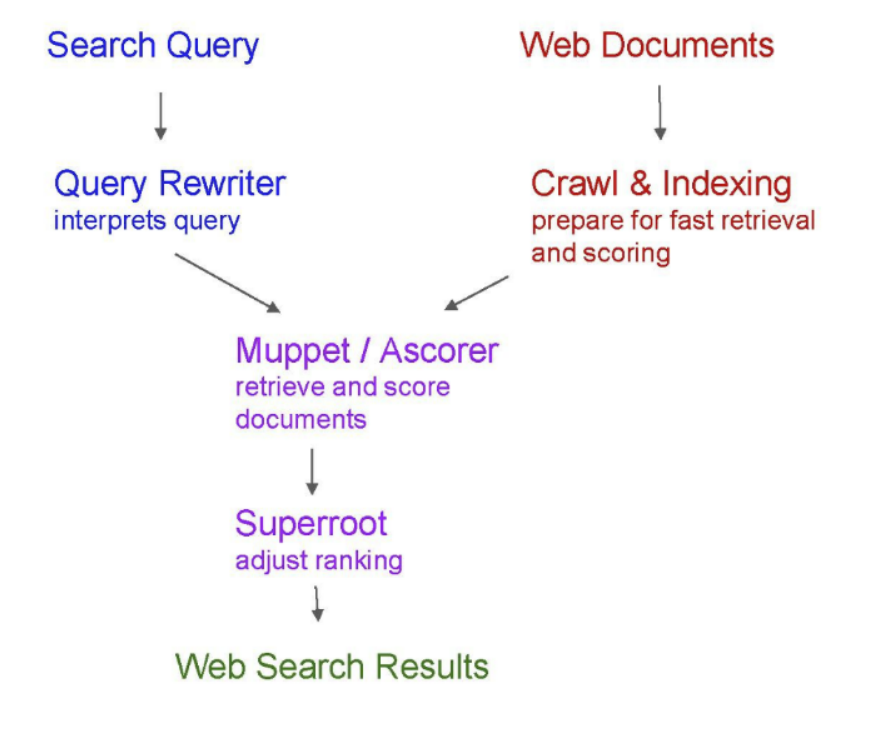
Union / Muppet
The Union/Muppet system bridges data aggregated during indexing with the serving phase triggered by user queries. This component seems to be particularly crucial, appearing prominently in several macro-level representations of Google’s software infrastructure. A notable example can be found in a diagram from the November 2018 « Ranking for Research » presentation, revealed during the late 2023 Google vs. US antitrust trial:
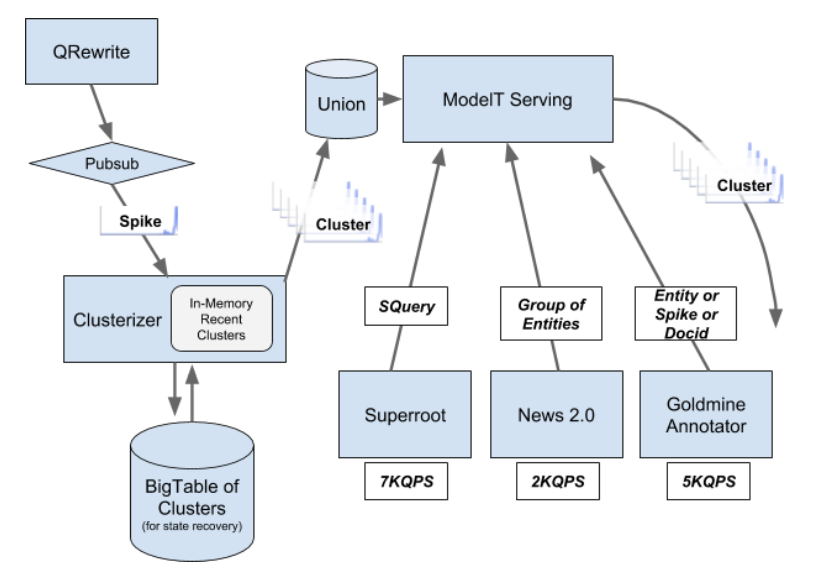
Union / Muppet also appears in this Real Time Boost twiddler design doc (where ModelT is an instance of Muppet):
Further proof, if needed, that the Union / Muppet block is a key component: this job ad – which has only been online for a short time – in which Google leaks the names of its own internal systems…
We have very little information available on this system, but here’s what we were able to find out:
- It is managed by the CDS (Core Data Service) team.
- Presented as a flexible, efficient and easy-to-use data platform that protects Google-wide datasets and proactively extracts insights from them.
- Initially developed for Search, Google intends to deploy it on a wider scale for all corporate services
- Prepares indexing data for the serving phase
- Includes several instances such as WebMain or ModelT
- relies on Serving Document Identifier (SDI) as a key for serving generation
- Generates snippets to be displayed in results, unless overloaded by SuperRoot when SnippetBrain is triggered via RankLab
To sum up, the Union / Muppet brick seems to be a central component that ensures the transition between indexed data and its rapid use in user queries. It may well play a role in the merging function presented in this paper: https: //arxiv.org/pdf/2010.01195 This is a hybrid approach that combines lexical and semantic models using deep neural networks. The core concept is to conduct lexical and semantic retrieval in parallel, then merge both result lists to form an initial list for reordering. This function would operate at the pre-ranking level—pure Information Retrieval (IR)—just before the final ranking process performed by Mustang. However, much remains unclear about this component. If anyone has insider knowledge, please reach out ^^.
With all this data consolidated, the engine can now evaluate and rank pages according to their relevance and quality. This is the crucial stage of scoring and ranking.
5 – SCORING & QUALITY / RANKING
Mustang
To summarize, Google’s indexing process splits into two types: offline indexes, generated post-crawl (like those in TeraGoogle or Alexandria) and stored in traditionnal databases, and online indexes generated dynamically at query time, in « NoSQL,” usin protocol buffers. This dynamic indexing applies to systems like Mustang and Muppet. This setup demonstrates a Google-specific approach: rather than using traditional databases, they manage data as collections of serialized protobufs written to files. But let’s get back to Mustang…
Although primarily focused on ranking, Mustang also manages several repositories, including Sentiment Snippet Annotations and freshdocs. These environments handles real-time query processing and SERP generation, while interacting with other system components like TeraGoogle. For instance, both Mustang and TeraGoogle utilize the Compressed Quality Signals structure.
Mustang employs an attachment system to store additional information on documents, making it easy to add new functionalities without modifying the basic structures. These include “Instant Mustang”, which hosts the Freshdocs pipeline, QBST (already mentioned), RankLab and UDR (formerly WebRef) —though we’ll explore these later. As for its ranking functions, this is where major machine learning algorithms operate: RankBrain, Deeprank, RankEmbed.

Mustang also incorporates Ascorer, the system that aggregates hundreds of signals for result ranking. It’s not clear whether Ascorer has been completely replaced by RankBrain and DeepRank, or whether the latter have been added to or trained on the same signals. In Paul Haahr’s interesting CV, we learn more about Ascorer’s beginnings:

Ascorer is one of the engine’s oldest modules, dating back to the same era as Mustang, Superroot and TeraGoogle. It is the heart of the ranking system. Leak documents tell us that it :
- Receives data from systems such as NSR
- Interacts with Superroot, probably to provide the final scores for the results
- Is involved in experiments to test new scoring components, as mentioned in Q*.
- Is able to handle different types of signals and adjustments, including penalties for bad backlinks

RankLab
RankLab is a machine learning platform tasked with testing various Google products for continuous improvement. The leaks reveal that in the context of search, it is an important Mustang module, but closer to Superroot, in charge of continuously testing and optimizing TITLE / Snippet relevance, exploiting a mass of data to train its models.
RankLab receives candidate titles and snippets, then exploits various signals to select the best one. It uses the metrics originalQueryTermCoverages, snippetQueryTermCoverage, or titleQueryTermCoverage to assess how well a snippet or title covers the terms of the initial query. Remember that snippets are “query dependent”: for each given {docid, query}, the Doc Servers return a specific {title, snippet}.
The displaySnippet field contains the features (notice, price, thumbnail…) of the final snippet proposed by Muppet. But it can be overridden by Superroot, which serves the final results, if SnippetBrain – a RankLab ML component – is triggered.

To sum up, Mustang stands at the core of Google’s ranking process, where machine learning plays an increasingly central role.
Once the initial ranking has been established, the next step is to adjust and serve the results to users, and to exploit their interactions to improve the system. This is the role of the serving and learning components.
6 – SERVING & TRAINING DATA
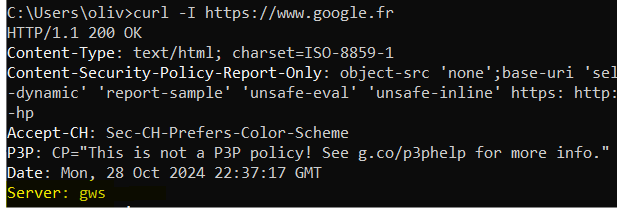
GWS : Google Web Server
This is the name of the Google front-end server returned when a curl is made on www.google.com. It’s no mystery – GWS even has its own Wikipedia page!
It contains two main sets:
1 – Superroot
Superroot ranks among the engine’s oldest components, with traces appearing in presentations from the late 2010s. It serves a crucial role: retrieving user queries, routing them through Google’s interconnected systems, and delivering results pages to the front end. This central function was highlighted by Google’s prominent engineer, Jeff Dean, in his 2009 presentation on Google’s operation: Challenges in Building Large-Scale Information Retrieval Systems (PDF, slide 64).
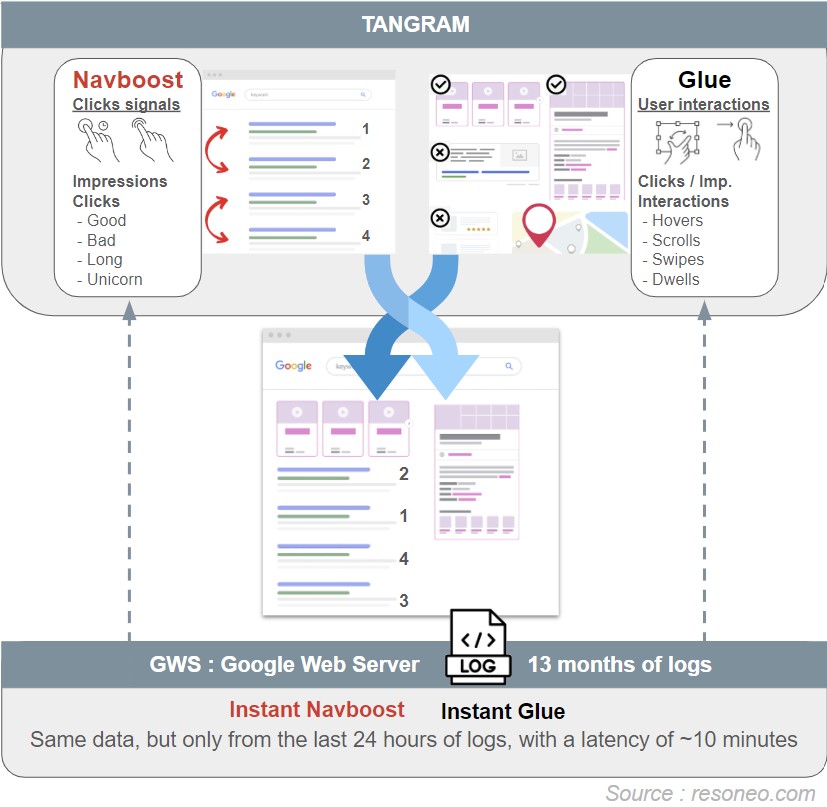
SuperRoot hosts Tangram, formerly known as Tetris, or Universal Packer, which is responsible for defining the most relevant features for the query, based in particular on click data (Navboost and Glue) already mentioned in the previous article:
It also hosts the Twiddlers framework, whose role is to adjust the rankings of the final list of results. Today, there are probably over a hundred different Twiddlers, each with their own role.
2 – GFE: Google Front End
GFE is the environment in direct contact with users. It hosts Google’s homepage and receives user queries. This is where spell checking, suggestions, and search result personalization mechanisms based on search history (data collected by GAIA) are implemented.
It contains essential query understanding and expansion modules: QRewrite, QRef, and QSession.
Focus on Query understanding & expansion, and search intent detection:
Search engines face inherent challenges in understanding user queries, which are typically brief texts requiring multiple interpretation mechanisms for optimal comprehension.
We recommend Paul Haahr’s video, where three examples demonstrate how each mechanism for disambiguation, semantics, and contextual analysis carries both benefits and drawbacks. A mechanism is deployed to production only when its advantages outweigh its disadvantages. The smiley example is particularly revealing: as it was representing 1 million daily searches in the mid-2000s, implementing smiley support required a full year of engineering work and a complete web page reindexing before the engine could properly interpret them in queries 🤓
We won’t examine all the mechanisms identified in the leak, but focus on a few representative ones
The MRF (Meaning Remodeling Framework) team plays a key role in managing this crucial stage, particularly through its maintenance of intent catalogs to better qualify queries.
QRewrite
The aptly named QRewrite module, invoked by Superroot when a user submits a query, transforms queries into a more engine-friendly format. It employs two types of processes:
- NLP: tokenization, grammatical tagging (assigning each token its grammatical role – noun, verb, adjective), and syntactic analysis (examining sentence structure to understand word relationships).
- Semantics : entity recognition, intention detection and context awareness
This enables the following operations:
- Standardization: correction of spelling mistakes, expansion of abbreviations and standardization of terms.
- Disambiguation: resolving ambiguities by choosing the most probable meaning based on context.
- Synonym management: replacing or adding words with their Knowledge Graph equivalents

QRewrite activates additional query analysis components as needed:
- QRef : Query Reference identifies entities within queries and links them to corresponding graph nodes. It performs term normalization, such as converting « NYC » to « New York City » or « Obama » to « Barack Obama »
- QSession tracks user sessions, analyzing sequential queries to understand the broader search context.
- QBST and Term Weighting, mentioned in a previous article, use machine learning models to interpret queries.
- STBR (Support Transfer Rules): operates using entities marked as sources and targets. Sources represent initial entities in a query, while targets receive relevance transfer to better match user intent. Consider the query « France Spain »: while sources are the countries themselves, targets are their national teams. The specific sport is determined through search trend analysis tied to current events via a separate system… This API route proves both explicit and informative, despite the author’s apparent difficulty with the French language…
QRewrite partners with multiple components to determine user intent:
IQL, WebRef (UDR) and Pianno to detect search intent
WebRef (or UDR, its replacement): This serves as QRef’s counterpart, operating on content rather than queries. It analyzes documents to identify and annotate entities (people, places, objects, concepts), with a topicality score (topicalityE2) indicating each entity’s relevance to the document. WebRef supplies entity information to both QRef for query adjustment and QRewrite for query modification, utilizing two subsets: Pianno and IQL.
Pianno: leverages WebRef’s stored entities to generate potential user intentions. It interprets context to understand users’ true informational or actionable goals. The calculated intention confidence scores are stored in piannoConfidenceScoreE2. Pianno primarily handles « unbound intents » – those without specific arguments – serving as an annotation pipeline for complex or ambiguous queries.
The leak also mentions Orbit, an intent detection pipeline specifically focused on images.
IQL (Intent Query Language): IQL is a language for representing complex intents in the system. It is often used to process intent expressions linked to WebRef entities and user queries, enabling these intents to be formalized and indexed for better query interpretation and resolution. It is used to encode these intentions in a structured way. Detected intents are converted into IQL expressions, enabling the engine to efficiently process and interpret the user’s intent. unboundIntentMid and unboundIntentScoreE2 store the MIDs of “unbound intents” and their respective confidence scores. These intentions represent potential actions without specific arguments (e.g. “Buy”, “Book”).
Example: a user searches for “how to cook risotto”.
- Entity detection :
- WebRef identifies the entities “cook” and “risotto”.
- These entities are encoded and their topicality and confidence scores are calculated.
- Intent generation:
- Pianno generates an unrelated intention such as Intent:CookingRecipe.
- The intention is associated with a high confidence score.
- IQL encoding:
- The intent is converted into an IQL expression and encoded in iqlFuncalls.
- The associated metadata is updated in the modules.
- Result for the user:
- Mustang leverages this information to provide users with recipes, tutorial videos, or ingredient lists.
In summary, UDR (formerly WebRef) extracts key content elements, Pianno analyzes these elements to determine user intent, and IQL structures this intent for relevant and effective system responses.
Toward More Advanced AI
The leak analysis reveals Google’s progressive shift toward machine learning systems: QBST and Termweight for query interpretation, UDM for document analysis, and SnippetRank (along with broader RankLab functions) for SERP optimization. As of October 2024, Google has begun using AI for results page packaging, starting with cooking recipes.
To conclude…
Congratulations on making it to the end! While lengthy, this deep dive into Google Search’s inner workings was essential – as the late Bill Slawski wisely noted, effective SEO requires understanding how search engines operate ^^
Read More in Our 2024 Google Leak Analysis Series:
Part 1: The Experiment-Driven Evolution of Google Search
Part 2: Understanding the Twiddler Framework
Part 3: From Words to Meaning: Google’s Advanced Lexical and Semantic Systems
Part 4: The Neural Revolution: Machine Learning Everywhere
Part 5: Click-data, NavBoost, Glue, and Beyond: Google is watching you!
Part 6 : How Does Google Search Work? The Hidden Infrastructure Powering Your Results

