
Jusqu’en 2013, avec l’invention de Word2vec par Google, et le déploiement de Hummingbird, le premier vrai dispositif de query expansion, on ne trouvait dans le Search Google que des systèmes classiques d’IR, à base de statistiques et d’analyses lexicales. Le correcteur orthographique et les suggest Google étaient déjà des révolutions à l’époque, mais le moteur a réellement franchi un cap avec l’arrivée de l’embedding et des premiers algorithmes de machine learning. Depuis l’apparition de RankBrain en 2015, et surtout depuis le lancement de DeepRank, Google est devenu de plus en plus deep learning dependant.
RankBrain (2015) : Premier grand système de machine learning utilisé par Google pour le classement. Il analyse principalement les 20 à 30 premiers résultats de la liste initiale, ajustant leur classement en fonction de leur pertinence. Son utilisation est limitée à un petit ensemble de résultats en raison de son coût élevé.
Il y a peu d’informations disponibles concernant QBST (Query Based Salient Term) dans le leak, mais il semble que ce système soit rattaché à RankBrain, qu’il ne s’occupe que des uni et bi-grams et qu’il s’agisse d’un modèle pairwise : comme Navboost, il fonctionne en paires requêtes / documents. QBST avait déjà été mentionné lors du procès de 2023, où l’on apprenait qu’il était également entraîné avec les données de clicks, là encore comme Navboost. Dans le leak de 2024 nous retrouvons plusieurs mentions de QBST et des « salient terms » en général.
Les termes saillants sont les mots les plus importants d’un document ou d’une requête en tant que descripteurs. Certains de leurs attributs comme Signal Term, Virtual Term Frequency ou IDF – inverse document frequency – le même que dans TF*IDF, nous renseignent sur leurs caractéristiques, sur des signaux complémentaires (body, anchor, clics) ou sur l’accumulation de ces termes, leur fréquence / rareté dans l’ensemble des documents analysés.
DeepRank, apparu après RankBrain, pousse l’analyse un cran plus loin en intégrant BERT, pour vraiment “comprendre” le langage naturel. BERT est en réalité très présent chez Google aujourd’hui, notamment au niveau de l’IR. BERT est arrivé dans les serps autour de 2019, pour gérer les WebAnswers (positions zero) dans un premier temps, avant d’être déployé pour DeepRank et également utilisé dans RankEmbed qui s’est appelé depuis RankEmbed-BERT.
Quand BERT s’occupe du ranking, alors son petit nom interne est DeepRank. DeepRank combine cette compréhension du langage avec les données indexées par Google pour améliorer la précision du classement, bien qu’il ne remplace pas encore l’évaluation humaine.
DeepRank VS RankBrain
RankBrain est très efficace pour comprendre les besoins utilisateurs même sur la long tail. C’était longtemps un des challenges de Google : pouvoir apporter une réponse pertinente même aux 15% des recherches quotidiennes qui n’ont jamais été vues auparavant. DeepRank quant à lui est très fort pour « comprendre » réellement le langage, lui donner du sens. Car contrairement à RankBrain, DeepRank est basé sur les fameux transformers de Google, qui s’intéressent aux séquences et est ainsi auto apprenant sur la compréhension du langage. Mais c’est aussi ce qui le rend très coûteux à l’utilisation sur des données massives.
DeepRank et RankBrain étaient plutôt complémentaires au début, mais au fur et à mesure de ses salves d’entraînement et des évolutions du modèle, DeepRank, est parvenu à allier la compréhension du langage tout en intégrant de plus en plus la connaissance présente dans les index de Google. RankBrain a donc de moins en moins d’utilité au sein du moteur.
Learning-To-Rank
On ne peut pas parler des grands algos de ranking sans évoquer au moins rapidement le learning to rank (LTR). Google a publié en 2020 un brevet démontrant l’intérêt d’utiliser le framework TFR-BERT, qui inclue un modèle Learning-to-Rank par-dessus une représentation par BERT des paires query-document. Cette approche combine ainsi la puissance de représentation de BERT avec l’optimisation du classement par learning-to-rank, améliorant significativement les performances sur les tâches de classement de passages. Ce type de système est vraisemblablement aujourd’hui utilisé par Google pour aider ses modèles à identifier les signaux les plus pertinents.
MUM
Quant à MUM, dont Google a beaucoup parlé, il ne serait finalement que très peu utilisé en production. Il le serait uniquement de manière indirecte par le biais d’entraînement de modèles plus restreints et spécifiques, qui eux interviennent dans le ranking. Ce n’est pas seulement parce qu’il est coûteux en computing, mais surtout, car solliciter un modèle IA de ce type (MUM est 1000 fois plus puissant que BERT) dans le cadre d’une recherche web où la réponse doit arriver en moins d’une seconde reste à l’heure actuelle très complexe.
IA et ML : maitriser l’immaitrisable
Cela pourrait toutefois évoluer très vite. C’était une des craintes partagée par Éric Lehman, ex-ingénieur Google dans une lettre interne rendue publique lors du procès antitrust de 2023, dont il était un important témoin. Selon lui, Google, ne serait pas à l’abri de se faire dépasser très vite par Apple, Amazon, Baidu, ou n’importe quel start-up qui miserait sur les language models pour révolutionner la recherche en ligne… Notez bien que cette alerte prémonitoire eu lieu en 2019, quelques années avant l’arrivée de ChatGPT et de Perplexity…
Face à ces évolutions, Google n’a pas d’autre choix que de s’appuyer de plus en plus sur l’IA pour propulser son moteur. Le schéma ci-dessous issu d’une présentation très intéressante de Marc Najork (Scientifique chez Google Deepmind), détaille le mode de fonctionnement hybride d’un moteur de recherche moderne, alliant les systèmes classique de recherche d’information, aux techniques récentes de vector embedding et de language models (les encadrés en pointillés sont un ajout de notre part).
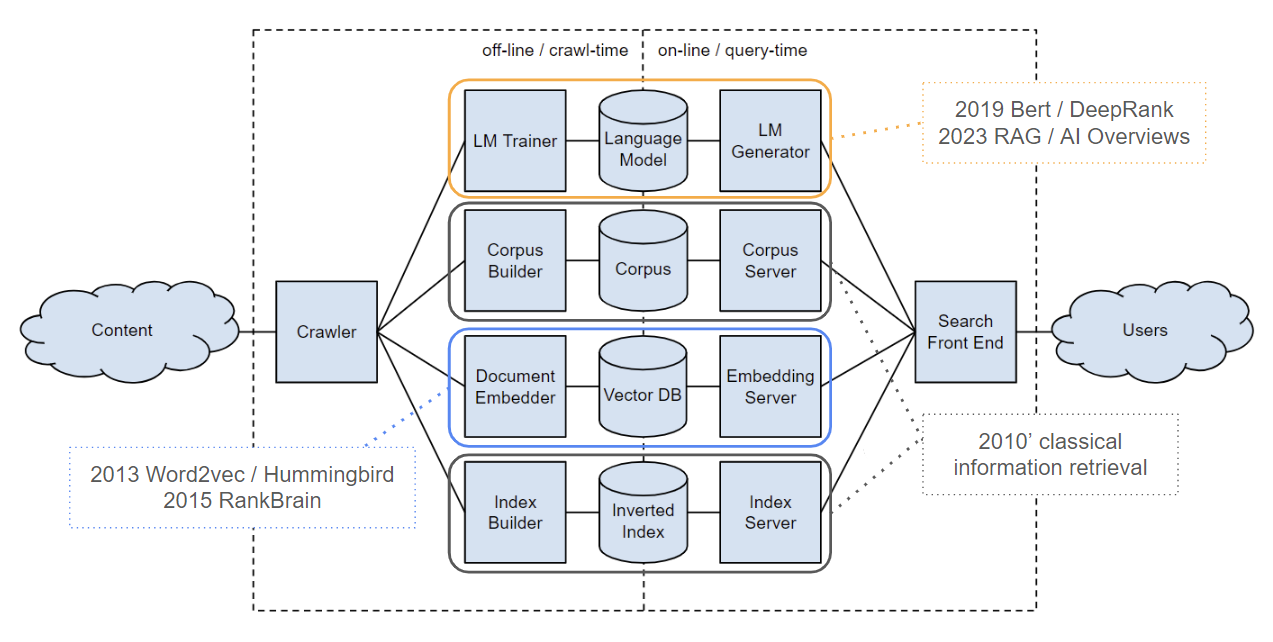
L’étude des documents du procès antitrust révèle que DeepRank prend progressivement le pas sur RankBrain et les autres algorithmes. Cependant, de l’aveu même de Pandu Nayak, malgré ses performances exceptionnelles, sa complexité en fait une « boîte noire » difficile à contrôler, ce qui incite Google à la prudence dans sa dépendance à ce modèle.

Il semble bien qu’on soit en plein dedans ^^ on l’a vu à l’œuvre récemment, avec le HCU et les dommages collatéraux causés à de nombreux sites pourtant légitimes. Google a en effet parfois du mal à maitriser les ajustements de ces modèles qui deviennent de plus en plus complexes.
Comment optimiser son SEO sur un moteur full IA ?
Vous allez nous dire que c’est bien beau d’avoir bientôt un moteur full IA qui est une black box, mais du coup, on fait quoi pour notre SEO ?
La réponse réside dans la phase préparatoire évoquée dans l’article précédent. Chaque bloc de contenu, chaque lien ou mention de votre site est minutieusement analysé par les systèmes de Google. Cette étape reste cruciale pour l’entraînement des IA. Les récentes conférences de Jeff Dean sur Gemini soulignent l’importance capitale de la qualité des données d’entraînement pour les modèles d’IA. Bien que de nombreux facteurs entrent en jeu, c’est sur la qualité du contenu, son accessibilité et l’amplification de sa visibilité que nous, en tant qu’éditeurs et professionnels du SEO, gardons la main.

Pour que Google puisse disposer de données de haute qualité, facilement exploitables par ses modèles, ça va être aux éditeurs de sites de structurer correctement leur navigation, proposer des contenus facilement exploitables par des algos sémantiques, et qui répondent à l’intention de qualité détaillée dans les 170 pages des guidelines aux quality raters… Les scores de qualité, de crawlabilité, d’extractabilités et tous les autres signaux dont on a un aperçu dans le leak font partie des données partagées aux systèmes de machine learning. Donc il y aura toujours du boulot pour les SEO 😉

Dans le prochain article, nous verrons comment les données utilisateurs sont également très importantes dans l’entraînement des algorithmes de classement de Google
Retrouvez les autres parties de notre série d’articles sur le Google leak de 2024 :
Part 1 – Les expérimentations au cœur de l’évolution du moteur de recherche
Part 2 – Le framework twiddler
Part 3 – Dans les coulisses du classement Google : Information Retrieval
Part 4 – Du machine learning à tous les étages
Part 5 – Clic-tature : quand l’Empire Google vous observe
Part 6 – Plongée dans les entrailles de Google Search, infrastructure et environnements Internes

