
Pour comprendre le fonctionnement des algorithmes de classement de Google, il est essentiel de connaître les différentes étapes et composants impliqués. Lorsque vous faites une requête sur Google, une première phase d’information retrieval (IR) et de scoring permet d’extraire une liste longue de résultats qui matchent avec la requête. Ensuite, le classement de ces résultats subit des ajustements finaux, un processus dans lequel les « twiddlers » jouent un rôle crucial.
Nous vous présentons ici un document interne à Google qui explique le fonctionnement des twiddlers, et leur différence avec Ascorer, un système de classement qui se situe au niveau supérieur dans les étapes de ranking du moteur. Ce document est issu du leak de 2019, qui avait fait assez peu parler de lui dans le monde du SEO à l’époque, peut-être parce que les motivations du Project Veritas étaient controversées. Toutefois, parmi les 320 fichiers qui ont fuité, il y en a au moins 5 ou 6 qui valent leur pesant d’or pour les SEO qui s’intéressent au fonctionnement de Google.
Attention : il s’agit d’un document assez technique que nous avons traduit avec nos commentaires pour en clarifier la lecture.
Le document commence par expliquer le principe global du framework :
Le framework twiddler est la partie de Superroot responsable du reclassement des résultats provenant d’un seul corpus. (L’autre composante majeure du classement dans Superroot est l’universal packer, qui combine les résultats de plusieurs corpus, c’est-à-dire pour la recherche universelle). // note : l’auteur évoque ici Tangram, chargé d’assembler comme un puzzle, avec l’aide de Glue et de NavBoost, les différents types de résultats qui constitueront la SERP finale avec toutes les features : images, vidéos, map, news.. (d’ailleurs l’ancien nom de code de Tangram était Tetris…). Quant à Superroot, il s’agit du nom interne d’un environnement central pour Google, chargé de distribuer les requêtes aux nombreux index et services du moteur puis d’agréger les réponses.
Un twiddler est un objet C++ qui émet des recommandations de ranking (twiddles) à partir d’une réponse de recherche provisoire provenant d’un corpus unique. Le twiddling diffère du classement Ascorer dans la mesure où les twiddlers agissent sur une séquence de résultats déjà classés, plutôt que sur des résultats isolés. // note : le terme corpus ici correspond à différents index : web, images, vidéos…
Il existe deux types de twiddlers : les “predoc” et les “lazy”. Les twiddlers predoc s’exécutent sur des réponses « fines » // note : « thin responses » en anglais, une simple liste d’URLs à priori, qui comportent généralement plusieurs centaines de résultats ne contenant pas de docinfo (snippets et autres données // note : docinfo correspond entre autre aux données permettant de concevoir les résultats présentés à l’utilisateur : snippets, breadcrumbs et autres données enrichies). Ces twiddlers s’exécutent sur l’ensemble des résultats renvoyés par le backend.
Après l’exécution de tous les twiddlers predoc, le framework réorganise les résultats « fins ». Il crée ensuite une RPC //Note : RPC = Remote Procedure Call, un style d’API qui récupère les informations de docinfo pour « préfixer » les résultats, exécute les twiddlers lazy sur ces préfixes et tente d’empaqueter une réponse. Cette tentative peut échouer par la suite si, par exemple, les twiddlers lazy filtrent les résultats du haut ou en poussent d’autres vers le bas du classement. Dans ce cas, le framework récupère à nouveau les docinfo, trie les nouveaux résultats, et essaie à nouveau d’empaqueter une réponse complète.
Objectifs et principes de conception des twiddlers :
- Isolation : Contrairement à Ascorer, qui dispose d’un nombre relativement restreint d’algorithmes complexes développés sur de longues périodes, le framework twiddler prend en charge des centaines de twiddlers (plus de 65 sont actuellement actifs en production dans le seul WebMixer //Note : le document date de 2018, on peut imaginer qu’il existe aujourd’hui plus d’une centaine de twiddlers), chacun essayant d’optimiser certains signaux. Dans ces conditions, laisser chacun de ces composants dépendre du comportement des autres entraînerait une complexité ingérable. C’est pourquoi le modèle conceptuel du framework twiddler est celui de twiddlers isolés (sans connaissance des décisions des autres).
- Interaction resolution : Parce qu’ils fonctionnent de manière isolée, les twiddlers ne peuvent fournir que des contraintes et des recommandations sur la manière de modifier le classement. Le framework réconcilie ensuite ces contraintes.
- Fournir le contexte : Le framework fournit un accès sécurisé en lecture seule au contexte dans lequel les résultats sont ajustés..
- Eviter la complexité de fetcher les docinfo et de gérer la pagination : en limitant les opérations que les lazy twiddlers peuvent effectuer, le framework permet d’éviter un large éventail de bugs de pagination – des résultats ignorés ou dupliqués à travers les limites de pagination de résultats de la recherche.
- Facilités d’expérimentations : Parce qu’ils s’exécutent dans Superroot, il est souvent plus facile de lancer des expérimentations de ranking en codant un twiddler (il suffit alors de lancer quelques tâches Superroot plutôt que de construire une nouvelle section Ascorer ou un attachement, ou de lancer 1 400 jobs). D’un autre côté, s’il y a besoin de grandes quantités de données, Ascorer est un meilleur choix.
Le document s’attarde ensuite sur les méthodes disponibles pour chaque twiddler :
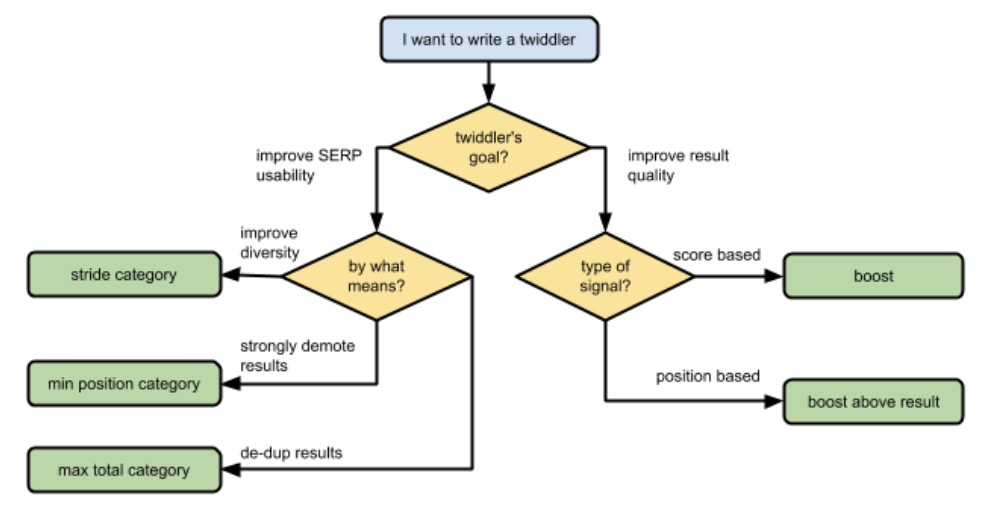
Boost et BoostAboveResult seraient les API les plus courantes et les plus utilisées dans les travaux de classement. Mais il existe d’autres types de twiddlers tels que les filter, max_total et stride, utilisés pour accroître la diversité, supprimer les doublons, réduire les résultats indésirables tels que le spam.. L’auteur recommande d’utiliser les méthodes et les types de catégories de twiddler dans l’optique d’exprimer une intention sémantique, plutôt que de se concentrer sur les détails opérationnels de ce qu’ils font et sur la façon dont ils interagissent. Par exemple, ne pas prévoir d’utiliser Boost pour rétrograder un simple résultat à la deuxième page, ou max_position simplement parce qu’on aurait déterminé qu’un résultat est meilleur que le premier…
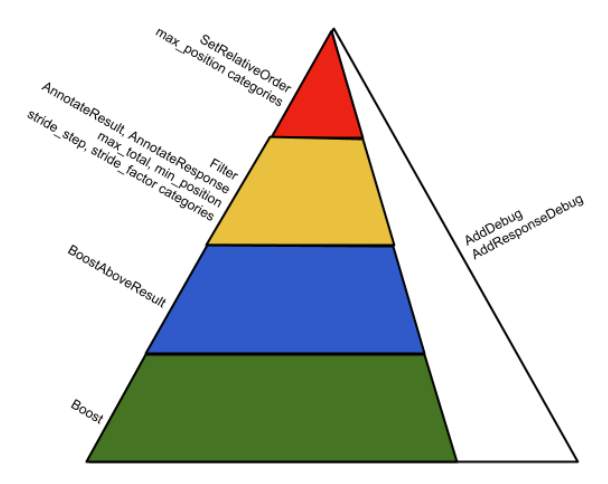
Quelques exemples de twiddlers
Le reste du document donne des exemples d’utilisation des différentes méthodes disponibles (surtout orientées Images et Youtube, ce qui est logique puisque le lanceur d’alerte à l’origine de la fuite travaillait sur ces corpus). On y trouve notamment la mention des twiddlers suivants :
- ImageHostCategorizer pour éviter que trop d’images d’un même domaine (“host”) soient regroupées dans un même bloc images, c’est un filtre de diversification
- OfficialPageTwiddler applique une contrainte de position 1 à la page officielle relative à une requête lorsqu’il existe une confiance très élevée dans son signal d’officialité. C’est ce qui fait qu’une entité forte (marque, organisation, célébrité…) est toujours première sur son nom.
- EmptySnippetFilter filtre les résultats qui n’ont pas de snippets
- YoutubeDuplicatesRemovalTwiddler utilise SetRelativeOrder pour contrer le problème de ceux qui uploadent de multiples copies de la même vidéo.. Il essaye d’identifier la vidéo originale, et de faire en sorte que ce soit elle qui soit toujours devant ses copies.
- YoutubeMovieTwiddler augmente les résultats des films qu’une entité en tête de classement place à la 1ère position
- DMCAFilter masque les résultats pour lesquels Google a reçu une notice DMCA, et ajoute des annotations qui seront utilisés par GWS (Google Web Serveur) pour prévenir les internautes qu’un lien a été supprimé sur cette requête
- D’autres twiddlers utilisent la methode Annotating dont le rôle est de transmettre des infos aux autres twiddlers, qui interviennent durant les dernières phases, à l’universal packer (Tangram) ou aux serveurs frontaux de GWS, pour influencer les dernières décisions de ranking ou d’UI. Parmi eux on notera SocialLikesAnnotator qui labelise les résultats avec le nombre de +1 qu’ils ont reçus, ou SymptomSearchTwiddler qui flag la réponse comme pouvant concerner des états de santé ou des symptomes.
Les twiddlers identifiables dans le leak de 2024
Dans le leak Google de 2024, on découvre de nombreux autres twiddlers. Il semble que la majorité des attributs qui alimentent les twiddlers se trouve dans les schémas suivants :
- PerDocData, où l’on retrouve de nombreux signaux et annotations importants concernant :
– Le spam et la sécurité : spamrank, urlPoisoningData, uacSpamScore (UAC = User Account Control), …
– Classement et qualité du document : pagerank, OriginalContentScore, hostNsr (l’équivalent du PageRank mais pour un site entier ou une partie de site), …
– Metadata et autres infos : webrefEntities, scienceDoctype, lastSignificantUpdate…
– Langues et Localisation - WWWDocInfo : pour les twiddlers de fin de chaîne, annotation, debug… donc plus proches de GWS,
- Certains éléments de WWWSnippetResponse qui semble surtout utilisé par GWS pour construire ses listes de résultats présentés aux internautes en agrégeant les title, snippet, rich snippet, date, listes… Notez qu’on y retrouve des traces de l’ODP (annuaire Dmoz abandonné en 2017 !)
- WWWResultInfoSubImageDocInfo : utilisé par les twiddlers focalisés sur les images, et qui passent par la méthode boost. On y notera le EQ*, un signal permettant de capturer la qualité émotionnelle d’une image (par exemple, l’inspiration, le style de vie, le contexte, etc.), ou le TQ*, permettant de capturer la qualité technique d’une image (par exemple, l’exposition, la netteté, la composition, etc.). De là à en déduire que même avec le plus expert et performant des contenus, celui ci sera toujours plus efficace si vous l’agrémentez d’une image (même inspirationnelle) et de bonne qualité, il n’y a qu’un pas !
D’un autre côté, certains documents du leak semblent être plus appropriés pour être interrogés par Ascorer. Par exemple CompressedQualitySignals, dans lequel on trouve entre autres un navDemotion, le pendant de navBoost mais dans l’autre sens ^^ Mais également Panda, babyPanda, ExatcMatchDomainDemotion, etc. Ascorer se trouve plus en amont des twiddlers dans le système de ranking, mais en aval des gros algos de classement comme DeepRank, RankBrain etc. C’est sans doute au niveau du processus Ascorer que se situent également Navboost et QBST (nous y reviendrons dans un autre article).
D’autres documents du leak de 2019 sont très révélateurs de la manière dont les équipes d’ingénieurs de Google travaillent. Il y a notamment les documents concernant deux projets de twiddlers chargés de détecter les requêtes qui émergent très rapidement. Ils datent de 2018, à l’époque Google avait un deal avec Twitter pour justement couvrir ces requêtes type breaking news. Ils renseignent notamment sur le fonctionnement de Google News.
Realtime Boost
Présentation
Design doc
Realtime Event
Présentation
Design doc
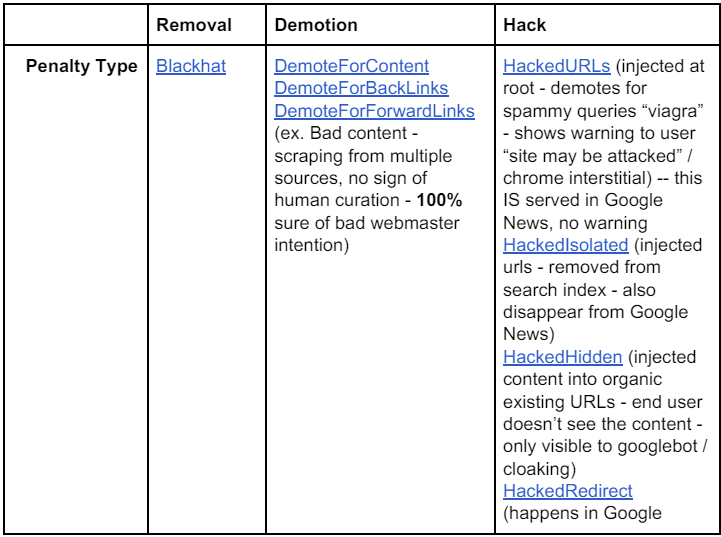
Le sixième et dernier document intéressant pour les SEO dans le leak de 2019, est ce design doc dédié à la lutte anti spam dans Google News, qui éclaire sur les typologies de pénalités manuelles gérées par Google :
Retrouvez les autres parties de notre série d’articles sur le Google leak de 2024 :
Part 1 – Les expérimentations au cœur de l’évolution du moteur de recherche
Part 2 – Le framework twiddler
Part 3 – Dans les coulisses du classement Google : Information Retrieval
Part 4 – Du machine learning à tous les étages
Part 5 – Clic-tature : quand l’Empire Google vous observe
Part 6 – Plongée dans les entrailles de Google Search, infrastructure et environnements Internes

