
Le 28 mai 2024, une fuite de plus de 2 500 documents internes à Google (et 14 000 attributs) a été révélée au public par Rand Fishkin et Mike King, deux professionnels bien connus de la communauté SEO.
À travers une série d’articles – dont certains seront assez techniques, RESONEO vous propose une plongée dans les coulisses de Google Search. Nous aborderons différents sujets, comme le framework twiddler, les grands modèles de classement (DeepRank, RankBrain..), les modalités d’entrainement des systèmes de ranking, un éclairage sur l’écosystème de l’infrastructure Google, avant de tenter de tirer les premiers enseignements. Ce sera également l’occasion de se repencher sur les documents des leaks précédents : celui du Project Veritas de 2019 et celui du procès antitrust qui a débuté en 2020. Mais avant de se lancer dans le vif du sujet, il est important de bien comprendre la manière dont les équipes interviennent au quotidien pour tenter d’améliorer les résultats fournis aux utilisateurs. C’est l’objet de ce premier article
Google teste en permanence
Google teste en permanence de nouveaux procédés pour améliorer la pertinence de ses résultats. Pour chaque composant du moteur, il existe une équipe dédiée, comme le révèle la documentation qui a fuité récemment.
Les équipes d’ingénieurs et analystes du moteur proposent des projets d’amélioration qui passent ensuite par un process long et complexe de validation avant d’être éventuellement mis en production si les résultats sont satisfaisants.

La vidéo ci-dessous est très instructive à cet égard, puisqu’on voit à quel point ces process de validation rythment les projets et maintiennent les équipes sous pression jusqu’à la validation finale. Le projet présenté par Google dans ce film est particulièrement important parce qu’il s’agit DeepRank. Suivez ces 10 minutes du feuilleton de la validation du projet en interne (à partir de la minute 44) :
Et ce processus de tests et validation est documenté publiquement sur les pages “How search works”. Ainsi, en 2022, Google aurait lancé :
- 894 660 search quality tests
- 148 038 tests comparatifs (“side by side”)
- 13 280 tests du trafic en situation réelle (“live traffic experiments”)
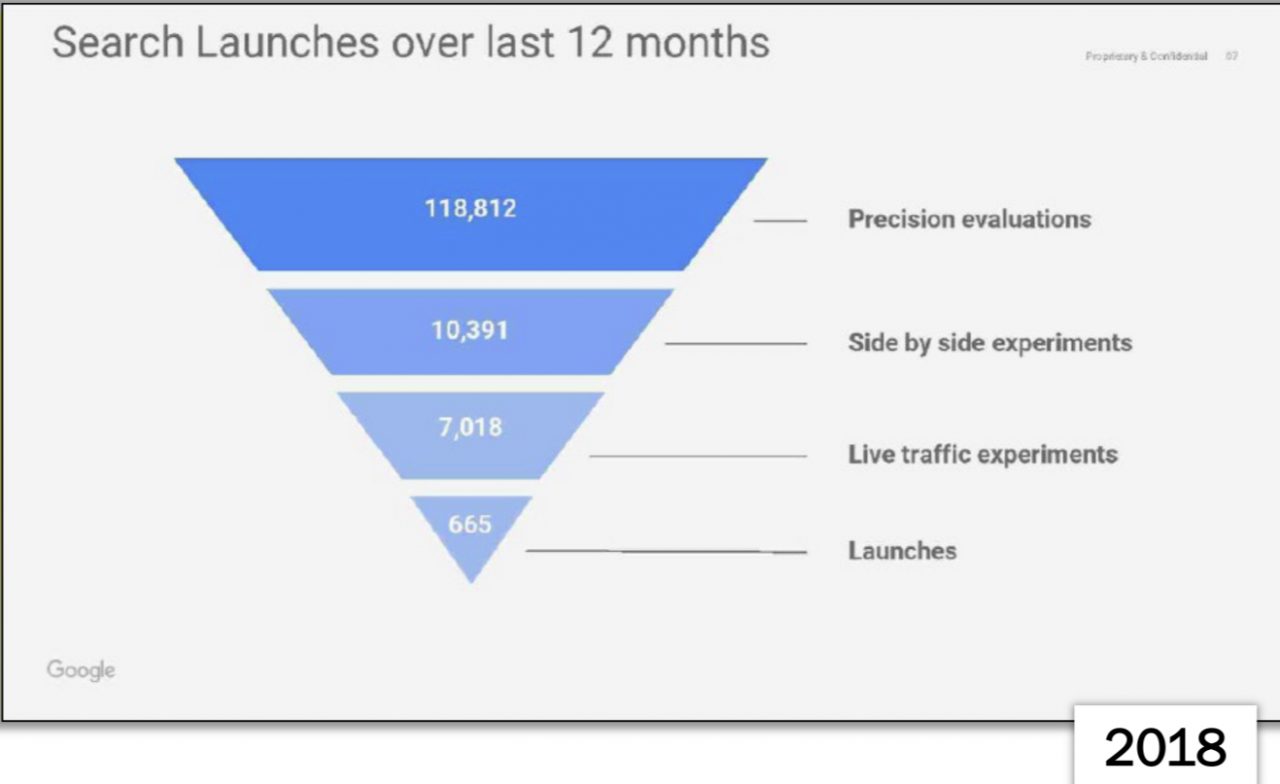
Ces tests auraient donné lieu à “seulement” 4 725 lancements. Les documents du procès anti trust de 2023 montrent que le nombre de lancements s’est largement accéléré depuis l’année 2018 qui n’en comptait “que” 665 :
Ce système de projets de modifications est ainsi au cœur de l’organisation de Google autour de l’évolution de son moteur, et met souvent les équipes à rude épreuve avec le stress généré par la perspective de voir son projet recalé… Ce qui semble être chose fréquente.
Afin d’évaluer la pertinence d’une modification, Google utilise principalement 3 méthodes :
- une méthode automatique, les “Live traffic Experiments” réalisés en production sur une partie limitée de son trafic (généralement moins de 1%).
- Deux méthodes manuelles, opérées par les “quality raters” : les search quality tests, qui consistent à évaluer indépendamment les résultats en termes de qualité, et les Side by side experiments, où les humains sont chargés de comparer un jeu de deux résultats différents sur une même requête.
Google utiliserait dans le monde 16 000 quality raters dont le résultat des tests alimente non seulement les équipes chargées des tests, ou les équipes anti spam, mais servent également de données d’entrainement aux algorithmes grâce à la remontée dans les systèmes de l’indicateur IS (« Information Statisfaction »).
Mais ces tests de qualité des résultats ne suffisent pas à approuver un projet
Les ingénieurs doivent également défendre les coûts de leur projet en termes de CPU, bande passante… Voici un exemple de slide d’une présentation destinée à défendre le déploiement d’un projet d’ajustement des résultats, où le responsable présente le stockage, la mémoire et le CPU dont il a besoin, ainsi que les validations internes.

Il ne suffit donc pas que les expérimentations (automatiques et humaines) soient positives, il faut également que le projet soit viable en termes de couts, capacité, latence, legal…
La densité de la documentation API du dernier leak en date confirme l’importance des ressources déployées par Google et son avance vis-à-vis de la concurrence. Dites-vous que tout ce à quoi vous auriez pu penser pour améliorer les résultats du moteur, un ingénieur de chez Google y a peut-être déjà pensé et potentiellement mené un test, qui est aujourd’hui en prod s’il s’est avéré concluant.
Si en revanche le projet n’a pas été validé, il y a de fortes chances qu’il reste des traces des signaux conçus pour l’occasion dans le leak. D’autant que certains projets expérimentaux peuvent avoir été conçus uniquement à des fins de tests, analyses, reporting… C’est pour cette raison notamment qu’on ne peut pas être certain que chaque méthode et schéma décrits dans cette doc API soient utilisés. Il se pourrait même qu’une part importante ne concerne que des projets non aboutis, abandonnés ou n’ayant pas passé le cap des expérimentations…
Retrouvez les autres parties de notre série d’articles sur le Google leak de 2024 :
Part 1 – Les expérimentations au cœur de l’évolution du moteur de recherche
Part 2 – Le framework twiddler
Part 3 – Dans les coulisses du classement Google : Information Retrieval
Part 4 – Du machine learning à tous les étages
Part 5 – Clic-tature : quand l’Empire Google vous observe
Part 6 – Plongée dans les entrailles de Google Search, infrastructure et environnements Internes

