
Google traque tout ce que vous faites dans ses pages de résultats
Et c’est une évidence déjà bien connue
- – Lorsque vous cliquez sur un résultat Google, vous passez d’abord par une URL de redirection du type google.com/url?url=http://etc. avant d’arriver sur le site correspondant au résultat. Google s’adonne à la mesure d’audience comme n’importe quel autre site. Nous sommes d’ailleurs bien contents de récupérer une partie de ces données dans la GSC…
- – Le concept de « pogo sticking » alimente les discussions entre SEOs depuis plus de deux décennies. Le fait de cliquer sur un résultat, puis de revenir rapidement à la SERP pour en choisir un autre, indique une certaine insatisfaction. Elle aussi mesurée par Google.
La nouveauté, issue du procès antitrust de 2023, c’est l’usage intensif de ces données dans les algos de Google, à commencer par Navboost et Glue. On s’en doutait déjà un peu, mais sans doute pas à ce point-là.
Le leak de mai dernier apporte quelques précisions supplémentaires, mais rien de révolutionnaire sur ce sujet. En réalité, il a surtout généré de la confusion puisque aujourd’hui beaucoup pensent que Navboost utilise des données issues de Chrome… ce qui n’est absolument pas le cas.
Dans cet article, nous allons voir quelles sont les données utilisateurs que Google exploite réellement pour affiner ses classements, et comment il pourrait s’en passer (ou pas) à l’avenir.
Les données utilisateurs issues des logs : requêtes et clics
Google exploite les interactions utilisateur – clics et requêtes – pour affiner les classements finaux et identifier les features à afficher dans les SERPS. Et d’après les témoins du procès antitrust de 2023, à commencer par l’ingénieur Éric Lehman, elles pèsent lourd dans le classement final.
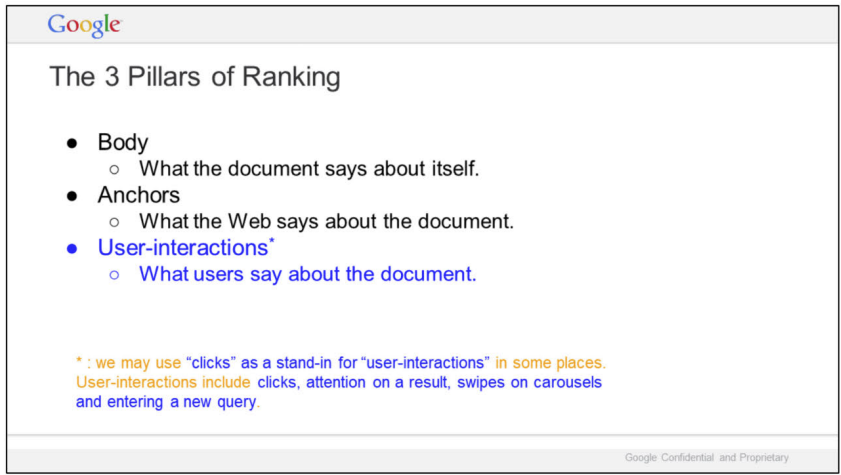
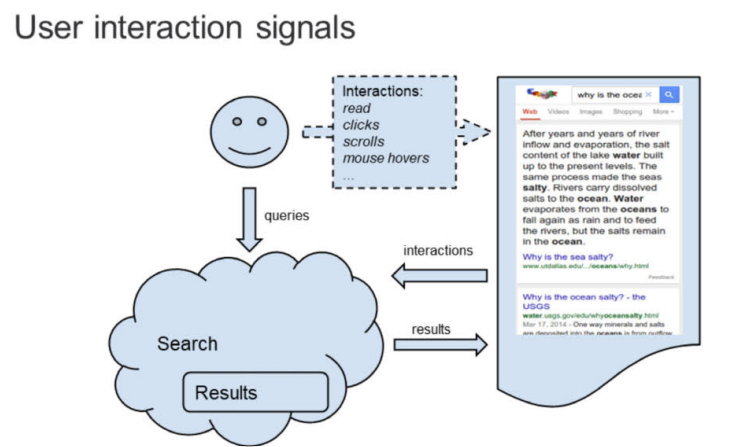
Navboost et Glue pour affiner le classement final
NavBoost est un algorithme de re-ranking qui utilise les feedbacks implicites des utilisateurs pour améliorer le classement final des résultats. Pour résumer, avec NavBoost, à l’instar des liens, chaque clic correspond à un vote d’un utilisateur vers un résultat. Cet algo existe depuis 2005 et une version pour mobile a été lancé en Q1 2014
Lorsque Google parle de données de clics, il s’agit en général d’une notion plus large, incluant les good & bad clicks, squashed, unsquashed, impression, ctr, survol des blocs issus de la recherche universelle, des KnowledgePanel ou WebAnswers…
- – good clicks : les liens sur lesquels les gens cliquent et restent un certain temps
- – bad clicks : ceux sur lesquels ils cliquent avant de revenir rapidement sur la liste de résultats
- – unsquashed : Il s’agit des clics qui ne sont pas écartés pour éviter la manipulation. C’est pour cela que Navboost ne s’active que sur une période de temps longue (13 mois) et pour un minimum de données. C’est la loi des grands nombres, il faut beaucoup de data pour que l’algorithme soit pertinent.

Quant aux Unicorn clicks, ils restent un mystère… Dans le leak, on apprend que les utilisateurs sont découpés en groupes (consommateurs, Dasher, Unicorn..). Ce n’est qu’une hypothèse mais le groupe des licornes pourrait correspondre aux utilisateurs non logués : les licornes font partie des créatures des avatars des utilisateurs anonymes sur un doc Google Drive ^^ Mais il pourrait également s’agir des power users de Google : en marketing les contenus unicorn correspondent au faible pourcentage de contenus ayant le meilleur taux d’engagement…
Tangram et Glue
Glue n’est arrivé qu’en 2014. Avec le mobile first, le déploiement de toujours plus de features visuelles dans les serps, les directs answers, KG et autres PAA, il fallait à Google un système plus puissant, capable d’analyser le comportement précis des internautes sur ses pages de résultats.
Glue comprend plusieurs composants : le système Glue lui-même, les données Glue, et les signaux Glue, chacun ayant un rôle distinct dans le processus. Google prend en compte non seulement les clics, mais aussi les survols (hovers), scroll et les changements de viewport sur mobile.

Dwells et luDwells : temps passé à examiner les résultats du Knowlegde Graph, Featured Snipped, et autres blocks de la recherche universelle
> Instant Glue
Afin d’être efficace également sur les requêtes émergentes, les « breaking News » du web, Google a également mis en place instantGlue, en parallèle des twidler Real Time Boost et Real Time Event dont nous avions parlé dans le deuxième article de cette série. Instant Glue est un pipeline en temps réel qui agrège les mêmes fractions de signaux d’interactions utilisateur que Glue, mais uniquement à partir des logs des dernières 24 heures, avec un temps de latence d’environ 10 minutes.
Dans l’infographie ci-dessous, nous avons résumé le fonctionnement de l’exploitation de ces données utilisateur pour le classement. Navboost et Glue se situent dans Tangram, au niveau de Superroot, qui héberge notamment les Twiddlers, le mécanisme de re-ranking de Google. Navboost et Glue interviennent donc après le principal dispositif de classement Ascorer (qui lui est hébergé par Mustang).
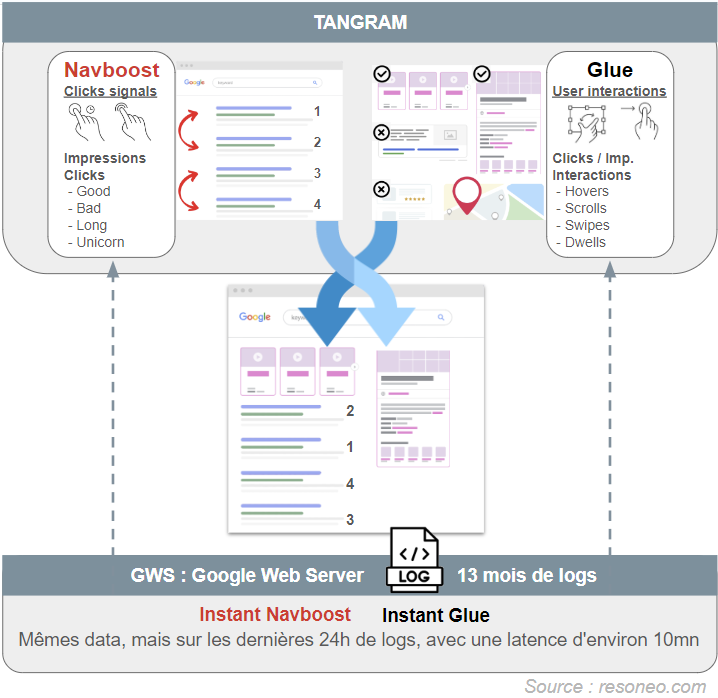
L’impact de Navboost/Glue serait très important dans le classement final, même si de nombreux autres facteurs interviennent également.
Lors de son audition Éric Lehman expliquait :
« we have access to large amounts of text, and we also had access to lots of user data… (…) we really couldn’t read documents. (…) So we played this game of read by proxy. Show the text to people, we observe their reactions and we adopt them as our own. »

“Si un document reçoit une réaction positive, nous pensons qu’il est bon. Si la réaction est négative, il est probablement mauvais. En simplifiant à l’extrême, c’est la source de la magie de Google.”
Et dans un e-mail interne il expliquait en 2019 que l’impact était tel que les autres équipes s’en plaignaient…

“(…) je suis assez sûr que NavBoost seul était / est plus positif sur les clics (et probablement même sur les mesures de précision / utilité) par lui-même que le reste du classement (d’ailleurs, les ingénieurs en dehors de l’équipe de Navboost n’étaient pas non plus contents de la puissance de Navboost, et du fait qu’il « volait des victoires »).”
Clicks data et Craps : l’exploitation des données utilisateurs à plus large échelle
Nous l’avons vu, les « données de clics » sont très largement utilisées pour le ranking. Mais elles intègrent également un système plus global nommé Craps (Click and Results Prediction System) utilisé à de multiples niveaux. Les signaux qui en découlent servent aussi bien à identifier l’intérêt de conserver une URL dans l’index qu’à mesurer l’intérêt global d’un document. Ces données sont découpées en « slices » (tranches) : device, country, lang, localisation…
Voici par exemples deux attributs intéressants :
- – clickRadius50Percent : Google calcule une zone (« radius ») à l’intérieur de laquelle le document réalise 50% de ses clics. Cela permet de définir la portée d’une page web : d’ultra locale à internationale.

- – isImportant : si certains signaux d’une URL sont faibles, mais bénéficient de « good clicks », Google sera susceptible de conserver tout de même cette URL dans ses index

Ce type d’attributs confirme ce qu’on apprenait avec le proces antitrus de 2023 : les données de clic servent en réalité à toutes les étapes du fonctionnement du moteur : crawling, indexing, query refinement ou information retrieval, pas uniquement au classement.

Pour les images, les données de clics sont d’autant plus importantes que Google a moins de texte à se mettre sous la dent…
- – imageQualityClickSignals : exemple d’attribut permettant de définir la qualité d’une image selon les signaux de clics.

La notion de CPS Personnal Data semble ici correspondre au Crown Prosecution Service chargé au UK de mener les poursuites judiciaires… Google doit parfois fournir aux procureurs ces fameuses données de clics dans le cadre d’investigations…
- – Le leak révèle aussi que Google calcule un score « Hovers to impressions » (h2i) et « Hovers to clicks », un genre de CTR adapté au comportement des utilisateurs lorsqu’ils cherchent une image. Le nombre de zoom ou de survol de l’image divisé par les clics ou les impressions permet de calculer la capacité de l’image à être attractive et inciter au clic.

- – imageExactBoost : Google labellise également les types de requêtes les plus pertinentes pour certaines images, lorsque le score de confiance est suffisamment important. Ces images sont alors boostées via le twidler imageExactBoost

- – clickMagnetScore ; utilise les « bad clicks » pour identifier les images ayant un fort pouvoir de persuasion (elles incitent à cliquer) mais qui renvoient l’utilisateur sur un résultat décevant… un détecteur de « putaclic » en quelque sorte ^^

Les données de clics servent à entrainer plusieurs grands systèmes
Google se sert également des clicks data pour entraîner ses grands algos de machine learning, et notamment RankBrain, Deeprank, RankEmbed, ou encore QBST. Seul MUM n’en a pas eu besoin à la grande surprise des ingénieurs Google…

Alors que durant une certaine période RankBrain était entrainé avec 13 mois de logs, comme NavBoost, il semble que désormais ces larges modèles aient besoin de beaucoup moins de données pour leur entrainement. En revanche, il leur faut des données fraiches (tous les 2 ou 3 mois).
Le type d’entraînement de ces algos à base de deep learning est fondé sur un système de généralisation, c’est-à-dire que les données qui aliment le modèle lui permettent d’en tirer des conclusions face à des situations où il n’a pas de données disponibles. C’est un système d’apprentissage, comme son nom l’indique. L’idée est d’identifier des patterns communs aux données de clics, permettant par exemple sur un ensemble de 1000 clics correspondants à un contexte bien particulier, de pouvoir anticiper le comportement du 1001eme clic dans le même contexte. C’est ce qui les rend efficaces même sur la long tail.
De l’autre côté, nous avons des systèmes dits de mémorisation, ceux-là conservent en mémoire l’historique des données passées, et se basent dessus pour en tirer des conclusions. Navboost et QBST sont des systèmes de mémorisation. Ils seront très efficaces dans les cas où ils ont beaucoup de données et beaucoup moins dans les autres, par exemple sur les requêtes long tail par définition peu fréquentes.
L’utilisation des données Chrome : mythe ou réalité ?
Le procès antitrust de Google a donné lieu à de nombreux débats sur l’avantage concurrentiel de Google VS Microsoft. En effet, alors que 13 mois d’historique de clics suffisaient à Google pour alimenter Navboost ou QBST, il aurait fallu 17 années de logs à Bing pour atteindre le même volume… Les débats ont également tourné autour de l’hégémonie de Chrome en tant que navigateur par défaut, des milliards versés à Apple et Samsung et tous les autres partenariats permettant au moteur d’être la porte d’entrée sur le web pour le plus grand nombre.
Google aurait-il pu cacher l’usage intensif des données de chrome dans le procès antitrust le plus important de ces 25 dernières années ? Alors même qu’ont été décortiqués dans tous les sens l’usage des données de clics Navboost, Glue etc ? Et que parmi les témoins interrogés sous serment certains ont passé des dizaines d’années chez Google ?
Les données de Chrome seraient en réalité très complexes à utiliser pour le classement des résultats. Les données de recherche / clics sont beaucoup plus pertinentes : leurs biais sont plus simples à maîtriser et le fait d’avoir les requêtes change tout. Que pourrait conclure Google en sachant uniquement qu’une page web a fait beaucoup de trafic ? Cela ne donnerait pas d’information sur sa pertinence face à une requête précise.
D’ailleurs les SEO black hat qui s’adonnent au campagnes de trafic (push & co) l’ont compris depuis longtemps : ils passent par une requête préalable, sinon cela fonctionne moins bien. Ces techniques performent à court terme car elles déclenchent instantNavboost/instantGlue, mais s’arrêtent de fonctionner dès que vous n’envoyez plus de trafic vers vos pages. Il est beaucoup plus compliqué de manipuler les résultats sur le long terme sachant que Navboost est entraîné avec 13 mois d’historique de données..
En revanche, Google utilise bien les données de Chrome, pour personnaliser les résultats en fonction de votre historique de recherche et de nombreux autres facteurs : lorsque vous êtes logués Google connaît tout de vous et vous traque de manière très précise pour personnaliser votre expérience sur ses services (Search, Ads, Map, Discover, etc.). Si vous voulez vraiment vous faire peur allez faire un tour sur le rapport MyActivity ^^
Mais Google ne semble pas traquer en dehors de leurs environnements vos mouvements de souris, formulaires remplis et autres conversions, comme nous avons pu le lire récemment. Attention donc à ne pas tirer de fausses conclusions et se lancer dans des opérations qui seraient inutiles (en tout cas pour votre SEO)…
Au delà de cette mise au point, et au regard des révélations du leak, nous pensons que les données de Chrome sont utilisées :
- – comme signal de qualité globale d’un site via Nsr, parmis des dizaines d’autres
- – pour découvrir de nouvelles urls : tous ceux qui travaillent dans le web se sont déjà retrouvés avec une version de pré-prod en ligne qu’il a fallu désindexer pour éviter le duplicate content… ou un PDF indexé on ne sait trop comment…
- – pour l’aider à sélectionner les sitelinks :
Notez que dans la doc Google les « Sitemap » correspondent à des groupes d’URL, et n’ont rien à voir avec les sitemaps xml… - – pour identifier les pics soudains de trafic sur une URLs qui ferait ainsi l’actualité, cf cette slide de présentation du twidler Realtime Boost Signal (peut impacter News et Discover notamment) :
- – et bien entendu pour les Core Web Vitals que l’on retrouve également dans le leak

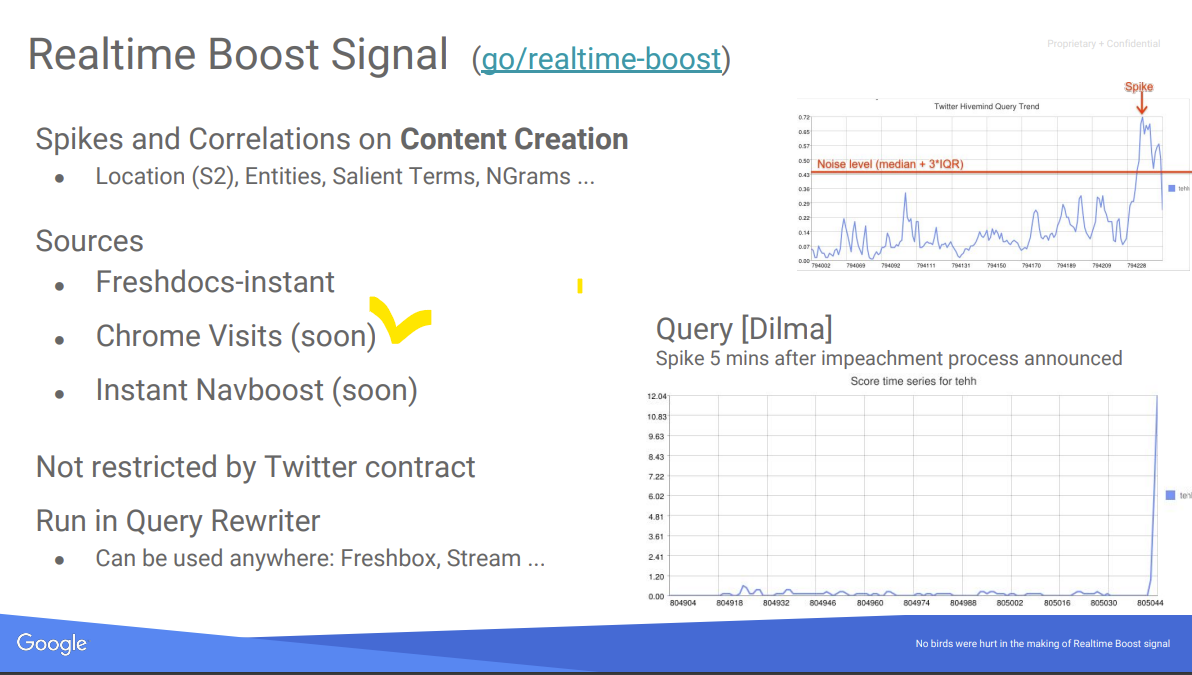
Et c’est à peu près tout. De manière générale, si Google utilisait réellement massivement les données de Chrome pour affiner ses classements, nous aurions beaucoup plus de méthodes et schémas disponibles dans la doc autour de ce sujet, ce qui n’est pas le cas.
Ce que Google aurait pu implémenter en revanche, (et qui l’est d’ailleurs peut-être) consiste à découper les clics selon les centres d’intérêt des utilisateurs. C’était déjà une application mentionnée dans le brevet fondateur de 2006. Par exemple, les utilisateurs expérimentés cliquent plus rapidement que les novices sur un résultat. Leur poids pourrait être plus important. Ou si un utilisateur fait de nombreuses recherches sur un sujet spécifique, comme le droit ou l’informatique, on peut supposer qu’il a une grande expertise dans ce domaine. Ses clics peuvent alors être surpondérés par l’algo.

Les évaluations des Quality Raters
Nous avons vu que Rankbrain, DeepRank et RankEmbed-BERT étaient entraînés avec les données de clics/queries (logs récoltés sur les pages de résultats). Mais ces 3 systèmes, ainsi que QBST, sont également fine-tunés avec les données issues des tests des Quality Raters (QR), via l’indicateur IS (“Information Satisfaction”).
Nous l’avions évoqué dans cet article, l’IS score est un indicateur clé de mesure de la qualité des résultats pour Google. Il est compilé sur la base des évaluations des 16 000 QR dans le monde. Nous n’allons pas revenir en détail dessus, la littérature foisonne sur le web à ce sujet et les guidelines sont rendues publiques par Google, mais gardez simplement en tête que les évaluations portent sur les deux principaux KPIs suivants :
- – Les Needs Met (en français “besoins satisfaits”) se concentrent sur les besoins des utilisateurs et sur l’utilité du résultat.

- – L’indicateur Page Quality quant à lui ne dépend pas de la requête, contrairement à Needs Met, et se concentre uniquement sur la qualité de la page

Le leak de mai 2024 nous apprend que les QR ne servent pas simplement à évaluer des résultats ou des pages/sites, mais aussi des entités. On y trouve en effet l’attribut “humanRatings” qui dépend du schéma Repository Webref Entity Join, lequel représente toutes les informations dont Google dispose pour chaque entité.

EWOK est le nom de la plateforme sur laquelle les évaluateurs de Google travaillent. Ils évaluent également les mentions d’entités (Single Mention Rating) :

Les évaluateurs semblent chargés d’estimer si une entité est correctement classée dans le bon topic. On trouve même un surprenant attribut booléen raterCanUnderstantTopic : l’évaluateur est capable de comprendre le topic ^^
L’IA pourrait-elle remplacer les évaluations humaines ?
Ce qui est fascinant, c’est de voir Google foncer tête baissée vers toujours plus d’IA pour remplacer ses mécanismes de classement. Certes, cela ne va pas arriver du jour au lendemain, et Google a encore besoin des précieuses données de clics. Mais qui sait ? Dans un futur pas si lointain, une IA pourrait bien évaluer seule la satisfaction utilisateur de manière efficace. Ses ingénieurs sont sûrement déjà sur le coup, et plusieurs signaux faibles viennent renforcer cette hypothèse :
- – Google a résilié début 2024 son contrat avec Appen, une des entreprises qui mettait à disposition du moteur plusieurs milliers de QR
- – Dans le même temps il est demandé aux QR de passer de plus en plus de temps sur des tâches d’évaluation des réponses générées par IA (Bard en 2023, puis Gemini & SGE)
- – Et certains attributs du leak montrent que Google tente parfois d’emuler une évaluation humaine : par exemple contentEffort…
Dans les guidelines des QR, l’effort fait partie des quatres indicateurs importants pour détermier la qualité d’un contenu, avec l’originalité, l’expertise et la fiabilité :

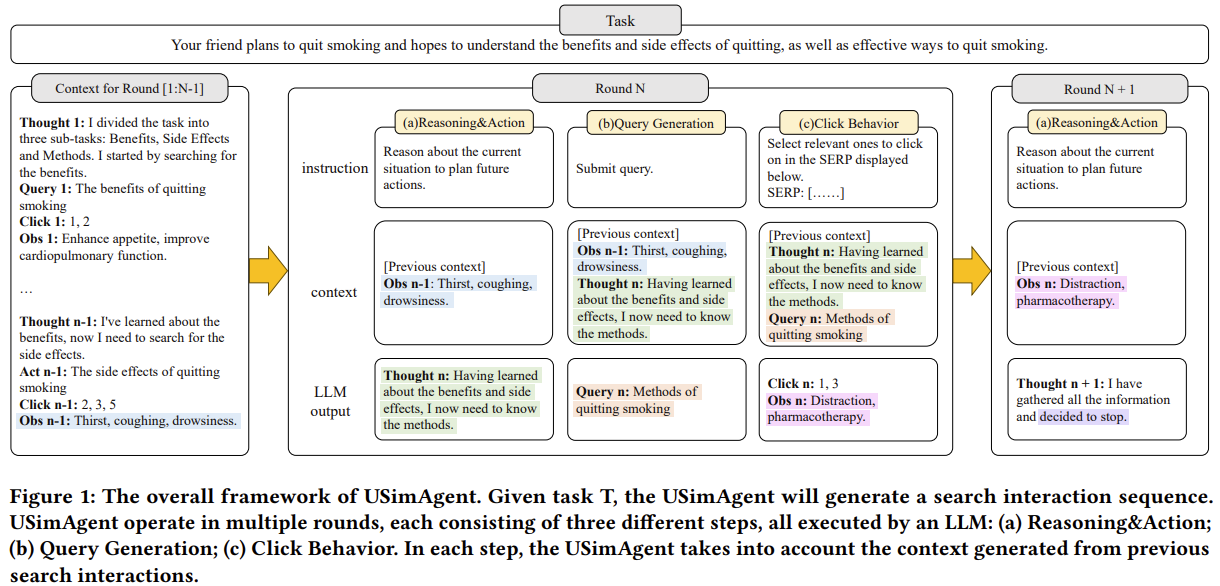
De même, de récentes études ont montré que l’IA était capable d’émuler les comportements de recherche des utilisateurs de manière très efficace. C’est la conclusion du brevet « USimAgent: Large Language Models for Simulating Search Users » : ce framework utilise les LLM pour simuler les comportements de recherche des utilisateurs, tels que les requêtes, les clics et les stops, et surpasserait les méthodes existantes en matière de génération de requêtes.
Avec les tonnes de tests passés, et l’accès à ses index colossaux, Google possède suffisamment de data pour remplacer progressivement les données de clics et les évaluateurs humains. Les SEO vont également pouvoir tirer leur épingle du jeu en exploitant ces nouvelles technologies. Vous nous voyez venir ? Qui a déjà son agent entraîné avec les 170 pages des Guidelines aux QR ? 😀
Dans un prochain article, nous nous pencherons sur l’environnement technique de Google, infra et principaux systèmes.
Retrouvez les autres parties de notre série d’articles sur le Google leak de 2024 :
Part 1 – Les expérimentations au cœur de l’évolution du moteur de recherche
Part 2 – Le framework twiddler
Part 3 – Dans les coulisses du classement Google : Information Retrieval
Part 4 – Du machine learning à tous les étages
Part 5 – Clic-tature : quand l’Empire Google vous observe
Part 6 – Plongée dans les entrailles de Google Search, infrastructure et environnements Internes

