
Dans notre précédent article sur le framework Twiddler, nous avons exploré les mécanismes de reranking en fin de chaîne de classement des résultats Google. Aujourd’hui, plongeons en amont pour comprendre ce qui se passe avant que les systèmes Google ne fournissent à Superroot une liste de quelques centaines de résultats déjà scorés à réajuster.
Au cœur de la machine : la recherche d’information
Le premier grand système de classement de Google n’en est pas vraiment un au sens strict. Il s’agit plutôt de ce qu’on appelle communément la recherche d’information, ou « information retrieval » (IR) en anglais. Chez Google, cela se traduit par un écosystème complexe de services interconnectés, certains activés en amont pour faciliter le procesus, d’autres déclenchés en parallèle lors d’une requête utilisateur pour minimiser le temps de réponse du moteur.
L’IR chez Google consiste, en simplifiant, à sélectionner une première liste de résultats correspondant à la requête de l’utilisateur. Cette liste peut initialement compter plusieurs milliers d’URLs, c’est le pré ranking, avant d’être affinée pour ne garder que quelques centaines de résultats pertinents.
La révélation du leak : le nombre de systèmes lexicaux et sémantiques
Le premier grand enseignement de ce leak Google, c’est finalement l’extraordinaire emphase qui est mise sur la compréhension et la qualification de chaque document web et leur rapprochement avec les requêtes des utilisateurs.
On peut distinguer deux grandes phases dans ce processus :
- Phase préparatoire off line :
De la découverte d’une URL à sa notation globale en termes de qualité, chaque document est minutieusement analysé. Mots, entités, phrases, images, vidéos, parties de site… Tout est extrait, tokenisé, et converti en vecteurs (embeddings) pour être envoyé dans de multiples pipelines de classification, d’annotation, de relation et de scoring.
- Phase on-line :
Déclenchée par une requête utilisateur, elle commence par l’étape d’IR pour aboutir à une large liste de résultats (plusieurs milliers). Cette liste est ensuite réduite à quelques centaines de résultats, ceux qu’on retrouve dans les SERPs grâce à la pagination. S’ensuit le reranking de cette liste réduite, pour finir par la construction de la page de résultats avec les titres, snippets, etc. Le tout en moins d’une demi-seconde.
Sur les 2600 documents du leak, une fois écartés les éléments non liés directement au Search (Maps, Assistant, AI Document Warehouse, sécurité, etc.), il ne reste plus que 1700 modules. On constate alors que l’accent est mis massivement sur le NLP, la qualité, les knowledge answers – bref, tout ce qui permet au moteur de comprendre l’intention des utilisateurs et de remonter les meilleures pages face à chaque requête.
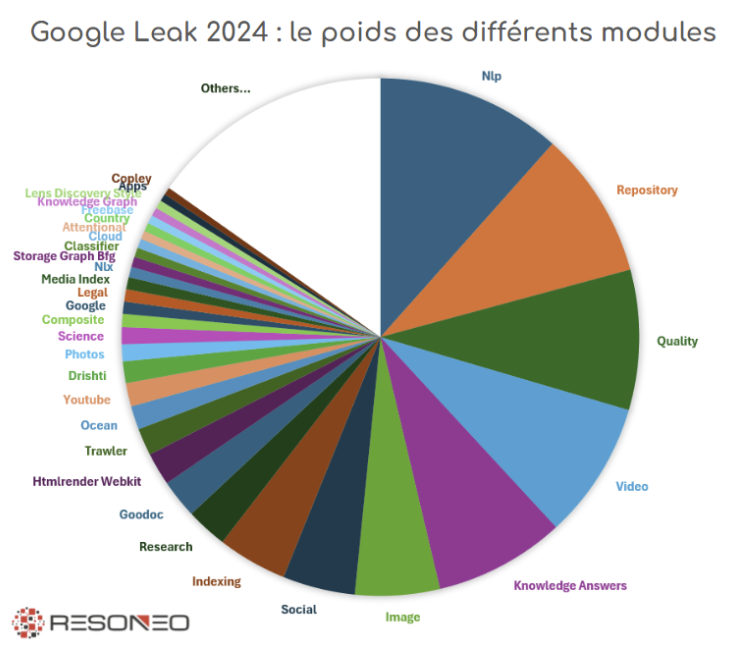
Que trouve-t-on dans les premiers blocs Nlp, Repository, Quality et Knowledge Answers ?
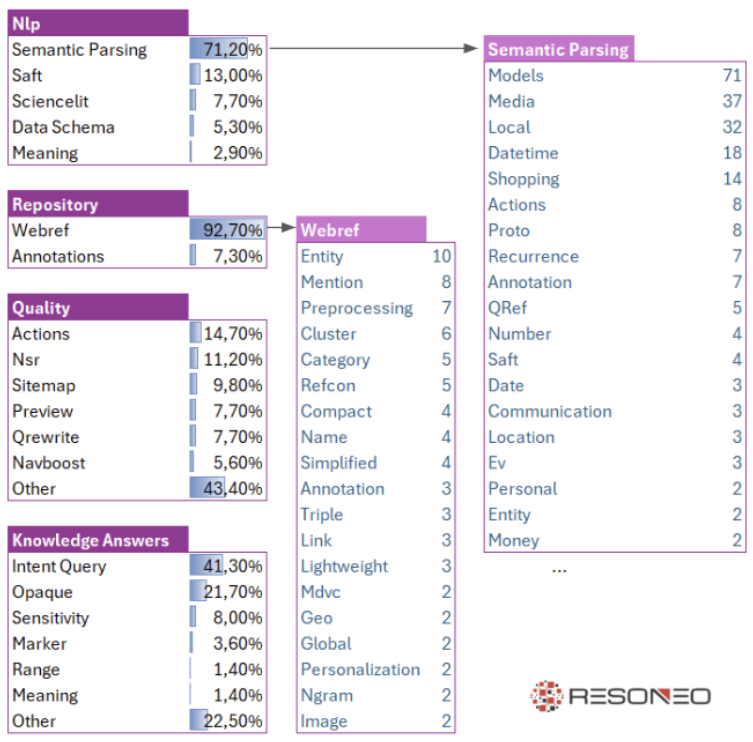
Bien sûr, nous savions déjà que le poids des efforts de Google était largement focalisé sur l’analyse des contenus, mais ce qui frappe dans ces documents, c’est l’incroyable multiplicité des systèmes lexicaux et sémantiques. Cela rappelle aux SEO que le critère numéro un pour le ranking reste le contenu et sa qualité (au sens « googlien » du terme). Gardez à l’esprit que le nombre de dispositifs chargés de qualifier chaque document est phénoménal. En voici quelques-uns :
- De nombreuses fonctions de parsing sémantique pour identifier les éléments clés d’une page : dates, informations locales, médias, produits…
- L’extraction des entités et l’alimentation du Knowledge Graph.
- Une multitude de classifiers : contenu pour adultes, spam (SpamBrain), commercial, forum, Q&A, scientifique, juridique, YMYL, qualité des images, anchor bayes classifier etc.
- SAFT (Structured Annotation Framework and Toolkit) qui gère les topics des documents, les entités, les labels, les liens, les mentions, les relations, les nœuds sémantiques…
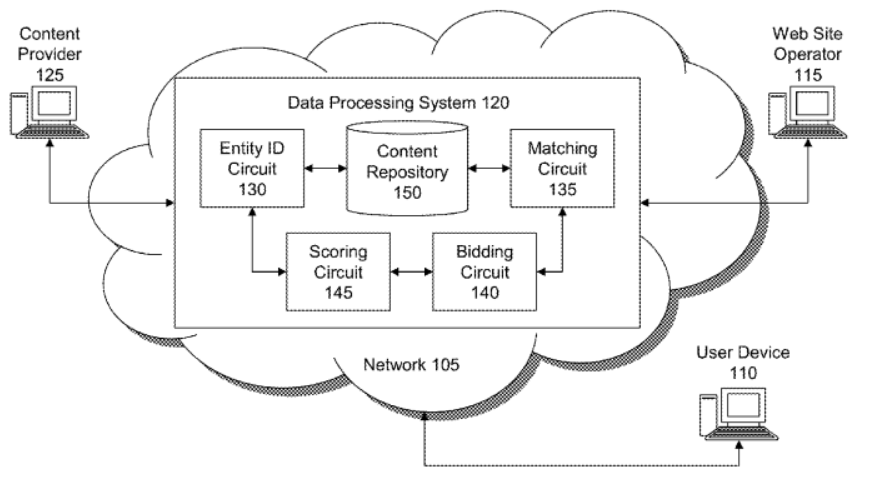
- Le repository Webref agrège toutes ces metadata élargies des documents et fonctionne de concert avec des circuits de matching, scoring, bidding comme on peut le voir dans ce brevet Google
Exemple d’attribut présent dans le leak à propos des entities et de la topicallity (concept très important au global pour Google) :
entity (type: list, default: nil) - The annotated entities, with associated confidence scores and metadata. This is the primary output of WebRef/QRef. In case of Webref output, entities are sorted by decreasing topicality score.
De nombreux moteurs de scoring et ranking
Toutes ces données extraites des documents sont agrégées et mises à disposition de dispositifs chargés de scorer chaque élément indépendamment, tout en communiquant avec les autres services. De nombreux signaux sont ainsi générés et seront utilisés par les algorithmes de ranking. Parmi eux : PQ Score (Page Quality), ReferencePageScores, SpamBrainScore, EntityNameScore, Topic score, ImageQualityScores, FreshNess, etc.
Deux algorithmes de ranking méritent une attention particulière :
- PageRank NS : Il s’agit d’un score de PageRank, calculé à l’aide de la méthode NearestSeeds. Cette méthode utilise une liste source d’URLs de confiance comme point de départ du crawl, la transmission du PageRank s’atténuant au fur et à mesure qu’on s’éloigne de cette liste. Il semblerait que le PageRank original ne soit plus utilisé depuis 2006, remplacé par ce PageRank NS.
- NSR (probablement Normalized Site Rank) : Cet algorithme, se base entre autres sur du vector embedding, on y trouve même un « site2vec ». Il fournit un score de qualité au niveau du site, d’une partie de site (chunk), ou même d’un article. Alimenté par au moins deux pipelines d’annotation internes à Google (Goldmine et Raffia), il fait appel à de mystérieux signaux aux noms culinaires : Keto, Rhubarb et Tofu, ainsi qu’à ChardScore, qui semble particulièrement important.
« chard » est une métrique utilisée par Google pour évaluer la qualité du contenu à la fois au niveau de la page et du site. Les différentes mentions de « chard » dans les attributs montrent qu’il s’agit d’un prédicteur basé sur le contenu qui est utilisé pour estimer la qualité globale et la fiabilité des pages web et des sites entiers. Les différentes variantes de prédictions « chard » (hoax, translated, YMYL,…) montrent que ce terme est utilisé pour des évaluations spécifiques de la qualité et de la fiabilité du contenu.
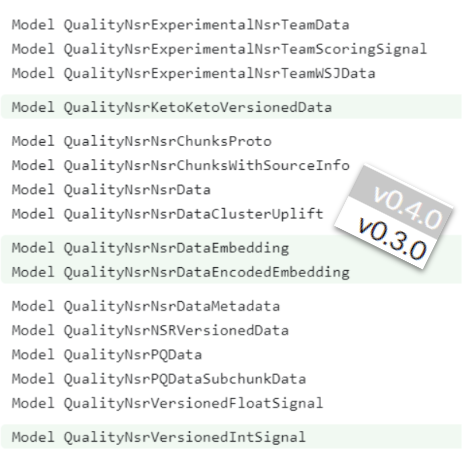
Ce n’est qu’une hypothèse, mais il se pourrait que NSR, qui agrège de nombreux signaux liés à la qualité, ne soit pas étranger au HCU (Helpful Content Update). D’autant qu’il paraît être encore en phase d’évolution : certains modules disponibles dans la V4 du leak n’apparaissent pas dans la V3 et des dates récentes (2022) sont mentionnées et correspondent à l’apparition du HCU.
Exemples de nouveaux modules qui sont présents dans la version 0.4 de la documentation du leak, mais pas dans la V0.3. En effet, les documents sont restés suffisamment longtemps en ligne pour avoir fait l’objet d’au moins une mise à jour importante (entre mars et mai 2024).
Pour conclure cette partie, on peut dire que Google n’est pas rancunier… même nos contenus les plus pourris, produits à la va-vite à grand coup de LLM rageurs passeront à travers les fourches caudines des algos sémantiques les plus puissants de la planète 😀
La qualité telle que Google la conçoit gravite entre autres autour de la notion de topicallity, qui est multidimensionnelle. Tout ce qui concerne l’embedding, les pipelines d’annotation, labellisation, extraction d’entités, n-gram, topics, les moteurs de scoring etc, constitue sans doute la partie la plus intéressante à creuser, mais également la plus complexe. D’autant que les signaux de Qualité n’impactent pas seulement le classement, mais aussi le crawl et l’indexation.
Dans un prochain article, nous verrons les grands systèmes de machine et deep learning
Retrouvez les autres parties de notre série d’articles sur le Google leak de 2024 :
Part 1 – Les expérimentations au cœur de l’évolution du moteur de recherche
Part 2 – Le framework twiddler
Part 3 – Dans les coulisses du classement Google : Information Retrieval
Part 4 – Du machine learning à tous les étages
Part 5 – Clic-tature : quand l’Empire Google vous observe
Part 6 – Plongée dans les entrailles de Google Search, infrastructure et environnements Internes

