
In our previous article on the Twiddler framework, we explored reranking mechanisms at Google’s final result ranking stage. Now, let’s examine the upstream processes to understand how Google’s systems generate and pre-score hundreds of results before submitting them to Superroot for adjustment.
The Engine Core: Information Retrieval Systems
Google’s primary ranking system isn’t strictly a ranking system per se. Instead, it operates as an information retrieval (IR) system, implemented through a complex ecosystem of interconnected services. Some of these services are pre-activated to facilitate processing, while others execute in parallel during user queries to optimize response times.
In simplified terms, Google’s IR functionality selects an initial result set matching the user’s query. This process begins with pre-ranking, potentially generating thousands of candidate URLs, before refinement narrows the selection to several hundred high-relevance results.
Key leak discovery: the number of lexical and semantic systems
The primary insight emerging from this Google leak reveals the extensive sophistication of systems dedicated to document comprehension, qualification, and query matching.
This process can be divided into two main phases:
- Offline Preprocessing Phase
- Document processing begins at URL discovery and extends through comprehensive quality assessment. The system methodically analyzes all components: words, entities, phrases, multimedia elements, and site structures. Each element undergoes extraction, tokenization, and vectorization (embeddings) before being processed through multiple pipelines for classification, annotation, relationship mapping, and scoring.
- Real-time Processing Phase (online)
- Initiated by user queries, this phase begins with IR operations, generating an extensive candidate set (thousands of results). This set undergoes progressive refinement to several hundred results, which populate paginated SERPs. The refined set then undergoes reranking, followed by SERP construction including titles, snippets, and rich elements—all executed in under 500 milliseconds.
f the 2,600 leaked documents, after excluding non-Search components (Maps, Assistant, AI Document Warehouse, security protocols, etc.), 1,750 models remain. This distribution demonstrates Google’s substantial investment in NLP, quality assessment, and knowledge-based response systems—core technologies enabling query intent comprehension and optimal page retrieval for each search query.
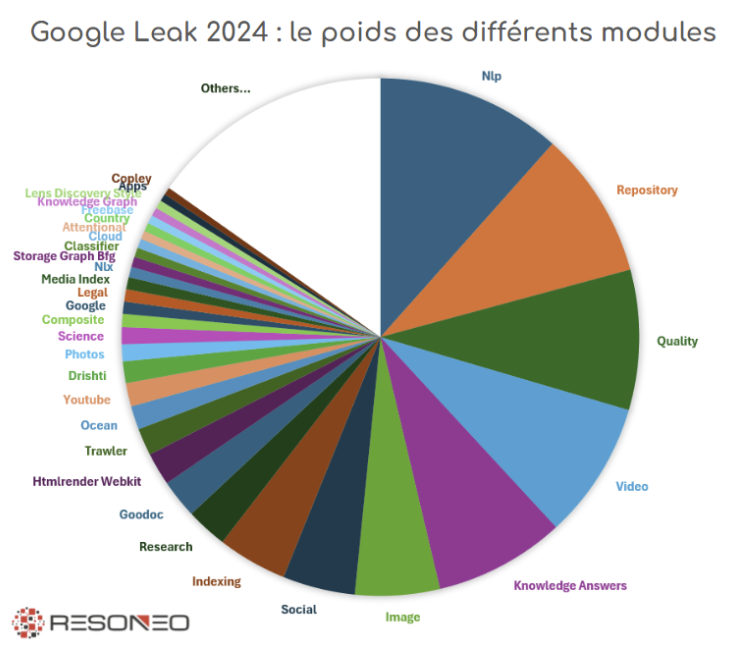
What’s in the first Nlp, Repository, Quality and Knowledge Answers blocks?
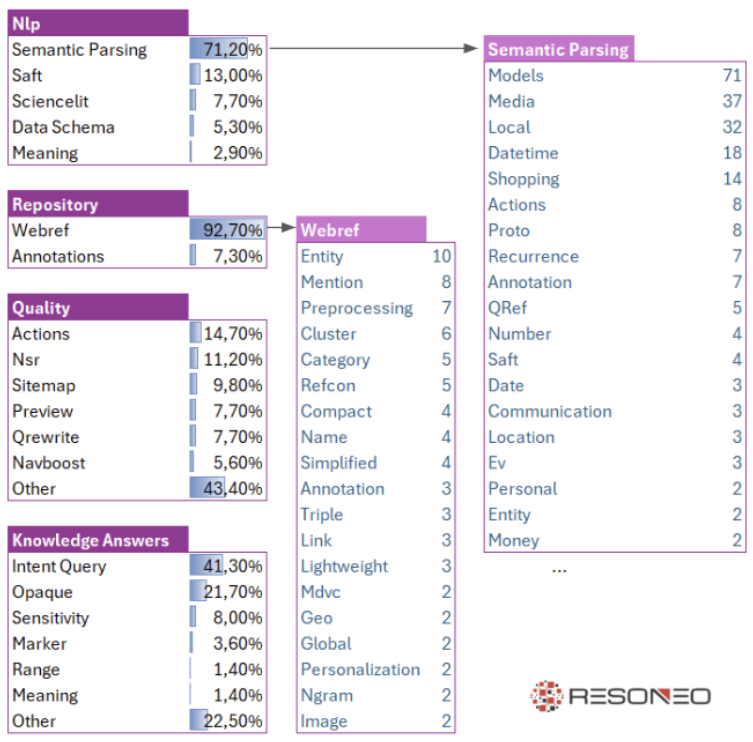
While Google’s emphasis on content analysis was previously established, these documents reveal an unprecedented scale of lexical and semantic processing systems. This reinforces to SEO professionals that content quality—as interpreted by Google’s algorithms—remains the primary ranking determinant. The scope of systems dedicated to document qualification is remarkable. Here is a subset of these systems:
- Numerous semantic parsing functions to identify the key elements of a page: dates, local information, media, products…
- Extract entities and feed them into the Knowledge Graph.
- A multitude of classifiers: adult content, spam (SpamBrain), commercial, forum, Q&A, scientific, legal, YMYL, image quality, anchor bayes classifier etc.
- SAFT (Structured Annotation Framework and Toolkit), which manages document topics, entities, labels, links, mentions, relations, semantic nodes, etc.
- Webref aggregates all these extended document metadata and works in concert with matching, scoring and bidding engines, as shown in this Google patent.
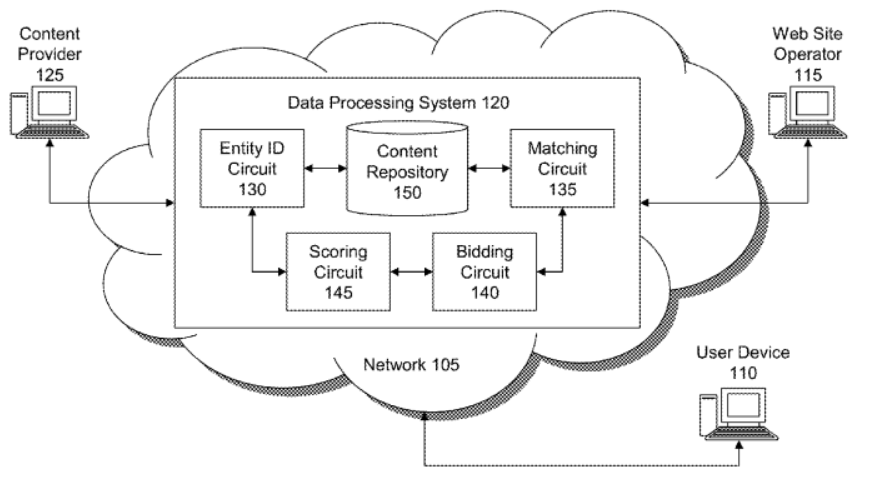
An illustrative attribute from the leak demonstrating entity relationships and topicality (a core concept in Google’s systems):
entity (type: list, default: nil) - The annotated entities, with associated confidence scores and metadata. This is the primary output of WebRef/QRef. In case of Webref output, entities are sorted by decreasing topicality score.
Numerous scoring and ranking engines
The extracted document data is aggregated and exposed to scoring systems that operate independently while maintaining inter-service communication. This process generates multiple ranking signals utilized by algorithmic systems, including: PQ Score (Page Quality), ReferencePageScores, SpamBrainScore, EntityNameScore, Topic score, ImageQualityScores, FreshNess, etc.
Two ranking algorithms deserve particular attention :
- PageRankNS: It’s a PageRank score computed using the NearestSeeds (NS) methodology. The system initiates crawling from a curated list of trusted URLs, with PageRank authority diminishing proportionally to the distance from these seed URLs. Evidence suggests that traditional PageRank was deprecated in 2006, superseded by this NS PageRank implementation.
- NSR (probably Normalized Site Rank): This algorithm leverages vector embedding technology, notably incorporating a ‘site2vec’ implementation. It generates quality scores at multiple granularities: site-wide, chunk-level, and article-specific assessments. The system integrates data from at least two proprietary Google annotation pipelines (Goldmine and Raffia), utilizing distinctive signal categories with culinary-themed identifiers: Keto, Rhubarb, and Tofu, alongside the apparently significant ChardScore metric
Chard’ represents a Google metric for evaluating content quality at both page and site levels. Multiple attribute references to ‘chard’ indicate its role as a content-based predictor for assessing overall quality and reliability of web pages and domains. The diverse ‘chard’ prediction variants (hoax, translated, YMYL, etc.) demonstrate its application in specialized content quality and reliability assessments.
While speculative, evidence suggests NSR’s aggregation of quality signals may correlate with HCU (Helpful Content Update) implementation. This hypothesis is supported by observable evolution: certain modules present in V4 of the leak are absent in V3, with timestamps from 2022 coinciding with HCU’s introduction.
Examples of new modules introduced in documentation version 0.4, not present in version 0.3. Notably, the documents remained accessible long enough to undergo at least one significant revision cycle (between March and May 2024).
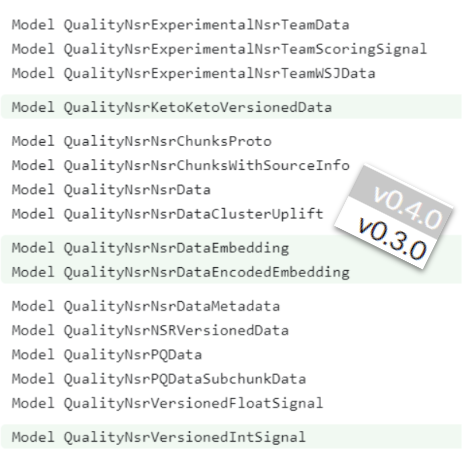
It’s worth noting that Google’s systems process all content systematically—including hastily generated LLM content—through its sophisticated semantic analysis infrastructure.
Google’s interpretation of quality is fundamentally tied to multidimensional topicality assessment. The ecosystem of embedding systems, annotation pipelines, labeling mechanisms, entity extraction, n-gram analysis, topic modeling, and scoring engines represents the most significant—yet complex—area for analysis. The impact of quality signals extends beyond ranking to influence both crawling and indexing processes.
The next article will examine Google’s core machine learning and deep learning architectures.
Read More in Our 2024 Google Leak Analysis Series:
Part 1: The Experiment-Driven Evolution of Google Search
Part 2: Understanding the Twiddler Framework
Part 3: From Words to Meaning: Google’s Advanced Lexical and Semantic Systems
Part 4: The Neural Revolution: Machine Learning Everywhere
Part 5: Click-data, NavBoost, Glue, and Beyond: Google is watching you!
Part 6 : How Does Google Search Work? The Hidden Infrastructure Powering Your Results

