
Understanding Google’s ranking algorithms requires familiarity with their distinct stages and components. When a search query is submitted to Google, an initial information retrieval (IR) phase generates and scores an extensive list of matching results. These results then undergo final ranking adjustments—a process where ‘twiddlers’ serve as key optimization components.
This article examines an internal Google document detailing the functionality of twiddlers and their distinction from Ascorer, a higher-level ranking system within the engine’s hierarchy. This document emerged from the 2019 leak, which generated significant attention in the SEO community, partly due to Project Veritas’s controversial agenda. Nevertheless, among the 320 leaked files, at least five or six documents provide invaluable insights into Google’s operational mechanisms for SEO professionals.
Please note: this is a fairly technical document, which we have translated with our comments to make it easier to read.
The document begins by explaining the overall principle of the framework :
The twiddler framework is the part of Superroot (http://go/sr) responsible for re-ranking of results from a single corpus. (The other major ranking component in Superroot is the universal packer, which combines results from multiple corpora, i.e., for universal search.) // Tangram orchestrates the assembly of various result types into the final SERP, functioning like a puzzle assembly system that integrates images, videos, maps, news, and other features with the assistance of Glue and NavBoost. (Interestingly, Tangram was formerly codenamed Tetris.) Meanwhile, Superroot serves as Google’s central environment, managing query distribution across the engine’s numerous indexes and services before aggregating their responses.
A twiddler is a C++ object that makes ranking recommendations (twiddles) given a provisional search response from a single corpus. Twiddling differs from Ascorer ranking in that twiddlers act on a ranked sequence of results, rather than results in isolation. // note: the term corpus here refers to different indexes: web, images, videos…
There are two supported types of twiddler: predoc and lazy. Predoc twiddlers run on thin responses, which typically have several hundred
results that don’t contain any docinfo (snippets and other data). // note: docinfo includes data used to design the results presented to the user: snippets, breadcrumbs and other enriched data.). These twiddlers run over the full set of results returned from the backend
After all predoc twiddlers have run, the framework reorders the thin results. It then makes an RPC // note: RPC = Remote Procedure Call, a kind of API that fetches docinfo for a prefix of the results, runs lazy twiddlers on that prefix, and attempts to pack a response. This attempt can fail if, for example, lazy twiddlers filter results from the top or push them down the ranking. In that case the framework fetches more docinfo, lazy twiddles the new results, and tries packing again.
Goals and design principles
- Isolation : In contrast to Ascorer, which has relatively few but complex algorithms developed over longer periods, the twiddler framework supports hundreds of twiddlers (>65 are currently active in production in WebMixer alone),// Note: Given that this document dates from 2018, one can reasonably assume that the number of twiddlers has since expanded well beyond one hundred. each trying to optimize for certain signals. Under these conditions, letting each of these components depend on the behavior of the others would result in unmanageable complexity. Therefore, the twiddler framework conceptual model is of twiddlers in isolation (without knowledge of the others’ decisions).
- Interaction resolution : Because twiddlers run in isolation, they can only provide constraints and recommendations of how to change the ranking. The framework then reconciles these constraints.
- Provide context : The framework provides safe read-only access to the context in which results are being twiddled
- Hide the complexities of docinfo fetching and pagination : By constraining the operations that lazy twiddlers may perform, the twiddler framework prevents a broad range of pagination bugs— skipped or duplicated results across search result page boundaries. This is covered more in the SuperrootBasicIntro.
- Ease of experimentation : Because they run within Superroot it is often easier to run ranking experiments by writing a twiddler (you only need to bring up a few superroot jobs rather than building an Ascorer section or attachment, or bringing up 1,400 jobs). On the other side, if you need huge amounts of data, Ascorer is a better choice.
The document then focuses on the methods available for each twiddler:
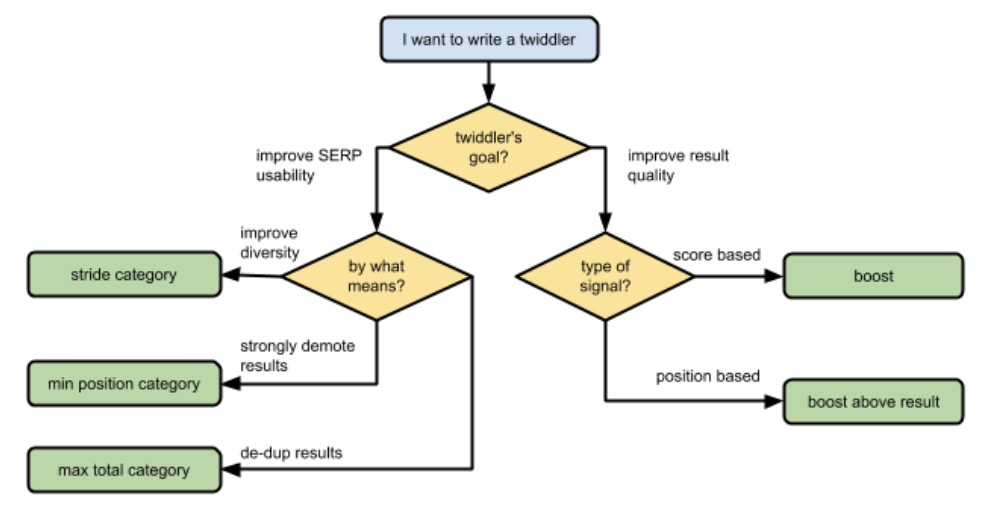
Boost and BoostAboveResult are reportedly the most commonly used APIs for ranking adjustments. Additional twiddler types include filter, max_total, and stride, which are employed to enhance result diversity, eliminate duplicates, and reduce undesirable content such as spam. The documentation recommends implementing twiddler methods and category types based on their semantic intent, rather than focusing on their operational mechanics and interactions. For instance, developers should avoid using Boost merely to demote a single result to the second page, or implementing max_position simply because they’ve identified a result as superior to the first one…
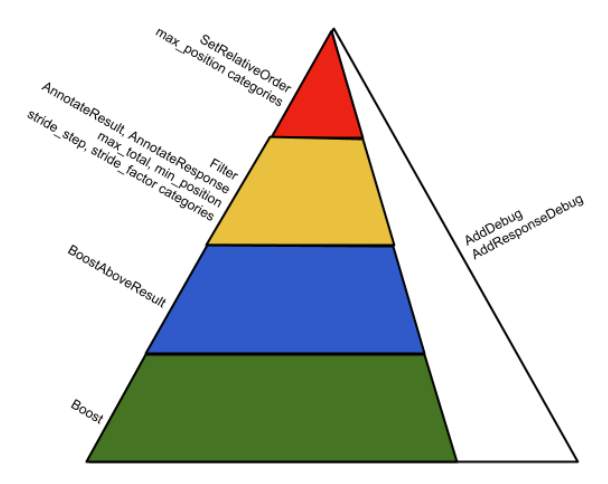
Some examples of twiddlers
The remainder of the document provides implementation examples for various available methods (primarily focusing on Images and YouTube, which aligns with the whistleblower’s area of expertise). Specifically, the following twiddlers are detailed:
- ImageHostCategorizer to prevent too many images from the same domain (“host”) from being grouped together in the same image block; this is a diversification filter.
- OfficialPageTwiddler enforces a position-one constraint for official pages when there is high confidence in the entity’s officiality signal. This mechanism ensures that authoritative entities (brands, organizations, celebrities, etc.) consistently rank first for their exact name queries..
- EmptySnippetFilter filters results without snippets
- YoutubeDuplicatesRemovalTwiddler implements SetRelativeOrder to address duplicate video uploads. The system identifies the original content and ensures it consistently ranks ahead of subsequent copies..
- YoutubeMovieTwiddler enhances the ranking of movies prioritized by a top-ranked entity in the first position..
- DMCAFilter suppresses results that have received DMCA notices and implements annotations processed by GWS (Google Web Server) to notify users about content removal specific to their query.
- Additional twiddlers utilize the Annotating method to relay information to subsequent twiddlers operating in final phases, as well as to the universal packer (Tangram) and GWS front-end servers, influencing ultimate ranking decisions and UI rendering. These include the SocialLikesAnnotator, which tags results with their accumulated +1 metrics, and the SymptomSearchTwiddler, which identifies and flags responses potentially associated with medical conditions or symptoms.
Twiddlers Identified in the 2024 Leak
The 2024 Google leak reveals numerous additional twiddlers. The majority of attributes feeding into twiddler operations appear to be defined within the following schemas::
- PerDocData, where we find many important signals and annotations concerning :
- – Spam and security: spamrank, urlPoisoningData, uacSpamScore (UAC = User Account Control), …
- – Document ranking and quality: pagerank, OriginalContentScore, hostNsr (the equivalent of PageRank but for a whole site or part of a site), …
- – Metadata and other information: webrefEntities, scienceDoctype, lastSignificantUpdate…
- – Languages and localization
- WWWDocInfo: for end-of-chain twiddlers, annotation, debugging… closer to GWS,
- Components of WWWSnippetResponse , which is primarily utilized by GWS to construct search result listings presented to users by aggregating titles, snippets, rich snippets, dates, and enumerated content. Notably, the schema still contains references to ODP (the Dmoz directory discontinued in 2017).
- WWWResultInfoSubImageDocInfo : Employed by image-focused twiddlers implementing the boost method. Notable signals include EQ* (Emotional Quality), which evaluates image emotional impact factors such as inspiration, lifestyle, and contextual relevance, and TQ* (Technical Quality), which assesses technical parameters including exposure, sharpness, and composition. This evidence strongly suggests that even highly optimized, expert-level content can achieve enhanced performance when paired with high-quality imagery, particularly those with strong emotional resonance.
Several documents in the leak appear more relevant to Ascorer’s functionality. These include CompressedQualitySignals, which contains navDemotion (the inverse counterpart to navBoost), as well as Panda, babyPanda, and ExactMatchDomainDemotion signals. Ascorer operates downstream from major ranking algorithms such as DeepRank and RankBrain, but upstream from twiddlers in the ranking pipeline. This Ascorer layer likely also incorporates Navboost and QBST processing (which will be detailed in a subsequent article).
Additional documents from the 2019 leak provide significant insights into Google’s engineering team operations. Of particular interest are documents detailing two twiddler projects designed to identify rapidly emerging queries. These documents, dating from 2018 when Google maintained a Twitter partnership for breaking news coverage, offer valuable insights into Google News operations.
Realtime Boost
Présentation
Design doc
Realtime Event
Présentation
Design doc
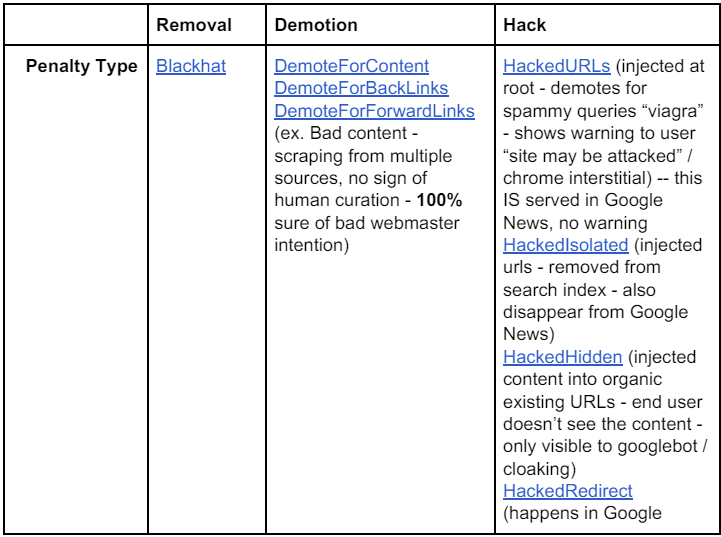
The sixth and final document of interest to SEOs in the 2019 leak, is this design doc dedicated to the fight against spam in Google News, which sheds light on the typologies of manual penalties managed by Google :
Read More in Our 2024 Google Leak Analysis Series:
Part 1: The Experiment-Driven Evolution of Google Search
Part 2: Understanding the Twiddler Framework
Part 3: From Words to Meaning: Google’s Advanced Lexical and Semantic Systems
Part 4: The Neural Revolution: Machine Learning Everywhere
Part 5: Click-data, NavBoost, Glue, and Beyond: Google is watching you!
Part 6 : How Does Google Search Work? The Hidden Infrastructure Powering Your Results

