
Prior to 2013, Google Search relied primarily on traditional IR systems based on statistical analysis and lexical processing. While innovations like spell-check and Google Suggest were groundbreaking, the paradigm shift occurred with the introduction of Word2vec and the Hummingbird deployment—the first comprehensive query expansion system. This marked Google’s transition from purely statistical methods to neural approaches.
The 2015 implementation of RankBrain, followed by DeepRank’s introduction, signaled Google’s accelerating shift toward deep learning architectures, fundamentally transforming its dependency on neural computation systems.
RankBrain (2015): Google’s first major machine learning ranking system. It primarily analyzes and re-ranks the top 20-30 results from the initial result set, optimizing their positions based on relevance metrics. Due to computational intensity, its application is constrained to this limited result subset.
QBST (Query Based Salient Term): While the leak provides limited documentation, evidence suggests this system operates as a RankBrain auxiliary component, specifically processing uni-grams and bi-grams through a pairwise model architecture. Like NavBoost, it evaluates query/document pairs and incorporates click-through data for training. The 2024 leak contains multiple references to QBST and general salient term processing, corroborating information previously revealed in the 2023 trial.
Salient terms represent the most significant lexical descriptors within documents or queries. Their attributes include Signal Term metrics, Virtual Term Frequency, and IDF (inverse document frequency)—analogous to TF*IDF components. These metrics provide insights into term characteristics, complementary signal sources (body content, anchor text, click data), and term distribution patterns, including frequency density and corpus-wide rarity across analyzed documents.
DeepRank, succeeding RankBrain, represents an evolution in search analysis through BERT integration for advanced natural language processing. BERT’s implementation across Google’s infrastructure is extensive, particularly within IR systems. Initially deployed in 2019 for WebAnswers (featured snippets), BERT’s functionality expanded to power both DeepRank and the system now designated as RankEmbed-BERT (formerly RankEmbed).
When applied specifically to ranking operations, BERT’s implementation is internally designated as DeepRank. This system combines natural language understanding capabilities with Google’s indexed data corpus to enhance ranking precision. However, it currently functions as a complement to, rather than a replacement for, human evaluation protocols.
DeepRank VS RankBrain
RankBrain demonstrates exceptional efficacy in query intent comprehension, particularly for long-tail searches. This addresses a critical Google challenge: delivering relevant results for the 15% of daily queries that are entirely novel.
DeepRank, by contrast, excels in semantic language processing and contextual understanding. Unlike RankBrain, DeepRank leverages Google’s transformer architecture, focusing on sequence analysis and exhibiting self-learning capabilities in language comprehension. However, this sophisticated processing demands substantial computational resources, limiting its application across massive datasets.
While initially operating as complementary systems, DeepRank’s evolution through iterative training cycles and model refinements has achieved an integration of advanced language comprehension with Google’s indexed knowledge base. This progressive enhancement has gradually diminished RankBrain’s operational significance within the search infrastructure.
Learning-To-Rank
Any discussion of major ranking algorithms necessitates addressing learning-to-rank (LTR) methodologies. Google’s 2020 patent publication demonstrated the efficacy of the TFR-BERT framework, which implements an LTR model atop BERT-based query-document pair representations. This architecture synthesizes BERT’s semantic modeling capabilities with LTR optimization techniques, yielding substantial performance improvements in passage ranking tasks. Evidence suggests Google currently leverages similar systems to optimize signal relevance determination across its ranking models.
MUM
Regarding MUM, despite significant public discourse from Google, its direct production implementation remains limited. The system primarily contributes through knowledge distillation into more specialized, computationally efficient models that integrate with ranking operations. This restricted deployment stems not only from computational overhead considerations but primarily from latency constraints—leveraging an AI model of this magnitude (MUM’s processing capacity exceeds BERT’s by 3 orders of magnitude) within sub-second search response requirements presents significant technical challenges in current infrastructure environments.
AI and ML: Managing System Complexity
This landscape could rapidly evolve. In an internal memorandum revealed during the 2023 antitrust trial, key witness and former Google engineer Eric Lehman expressed concerns about competitive disruption. He posited that Google’s market position could face swift challenges from established tech companies like Apple, Amazon, and Baidu, or emerging startups leveraging language models to transform search paradigms. This prescient warning, issued in 2019, predated the emergence of ChatGPT and Perplexity.
In response to this evolving search ecosystem, Google’s trajectory necessarily gravitates toward increased AI integration. The following diagram, extracted from Marc Najork’s (Google DeepMind Scientist) seminal presentation, illustrates the hybrid architecture of contemporary search engines—combining traditional information retrieval systems with modern vector embedding and language model implementations. (Note: dotted box annotations represent our analytical additions).
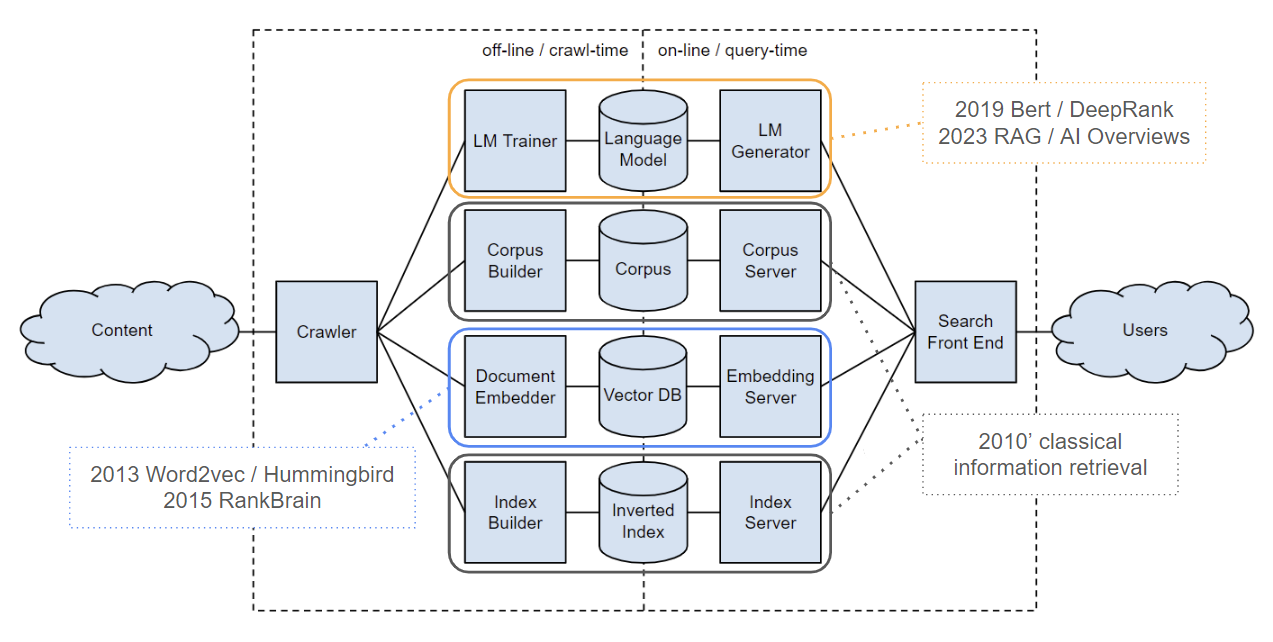
Analysis of antitrust trial documentation indicates DeepRank’s progressive displacement of RankBrain and incumbent algorithmic systems. However, as acknowledged by Pandu Nayak, despite demonstrating superior performance metrics, its architectural complexity creates interpretability challenges—effectively rendering it a ‘black box’ system. This opacity has prompted Google to maintain measured deployment protocols for the model.

It seems we’re right in the middle of it ^^ we’ve seen it in action recently, with the HCU and the collateral damage caused to many legitimate sites. Google sometimes has difficulty in mastering the adjustments to these models, which are becoming increasingly complex.
How to optimize SEO on a full AI engine?
You might tell us that it’s all very well to soon have a full AI engine that’s a black box, but what about our SEO?
The solution can be found in the preparatory phase discussed in our previous article. Google’s systems meticulously analyze every content block, link, and mention on your site. This foundational stage remains essential for AI training – a point recently emphasized by Jeff Dean in his Gemini lectures, where he stressed the paramount importance of training data quality. While multiple factors influence AI performance, we as publishers and SEO professionals maintain control over what truly matters: content quality, accessibility, and visibility optimization.

For Google to feed its models with high-quality, easily exploitable data, website publishers must fulfill several key responsibilities: implementing well-structured navigation, creating content that semantic algorithms can readily process, and meeting the quality standards detailed in the 170-page Quality Rater Guidelines. Quality scores, crawlability metrics, content extractability ratings, and other signals glimpsed in the recent leak all feed into the machine learning systems. Rest assured – this means SEO professionals will remain indispensable! 😉

In the next article, we’ll see how user data is also very important in training Google’s ranking algorithms.
Read More in Our 2024 Google Leak Analysis Series:
Part 1: The Experiment-Driven Evolution of Google Search
Part 2: Understanding the Twiddler Framework
Part 3: From Words to Meaning: Google’s Advanced Lexical and Semantic Systems
Part 4: The Neural Revolution: Machine Learning Everywhere
Part 5: Click-data, NavBoost, Glue, and Beyond: Google is watching you!
Part 6 : How Does Google Search Work? The Hidden Infrastructure Powering Your Results

