
On May 28, 2024, a leak of over 2600 internal Google documents (and 14,000 attributes) was revealed to the public by Rand Fishkin and Mike King, two well-known professionals in the SEO community. The leak was first discovered by SEO experts Erfan Azimi and Dan Petrovic.
Through a series of articles – some of them quite technical – RESONEO takes you behind the scenes of Google Search. We’ll be covering topics such as the twiddler framework, the major ranking models (DeepRank, RankBrain…), how ranking systems are trained, a look at the Google infrastructure ecosystem, before attempting to draw the first lessons. This will also be an opportunity to look back at documents from previous leaks: the Project Veritas leaks from 2019 and the antitrust trial that began in 2020. However, before delving into these complex aspects, it’s essential to understand how teams work daily to optimize user search results – the focus of this first article.
Google is constantly testing
Google continuously tests new approaches to enhance its search result relevance. As revealed in recently leaked documentation, each engine component has its own dedicated team.
Engineering and analytics teams propose search engine improvements that undergo a rigorous validation process before potentially being deployed to production, pending satisfactory results.
The following video provides valuable insights into how these validation processes shape projects and maintain constant pressure on teams until final approval. The Google project featured in this video is particularly significant as it showcases DeepRank. Watch this 10-minute segment of the internal validation process (starting at 44:00):
And this testing and validation process is publicly documented on the “How search works” pages. By 2022, Google will have launched :
- 894 660 search quality tests
- 148 038 side by side tests
- 13 280 live traffic experiments
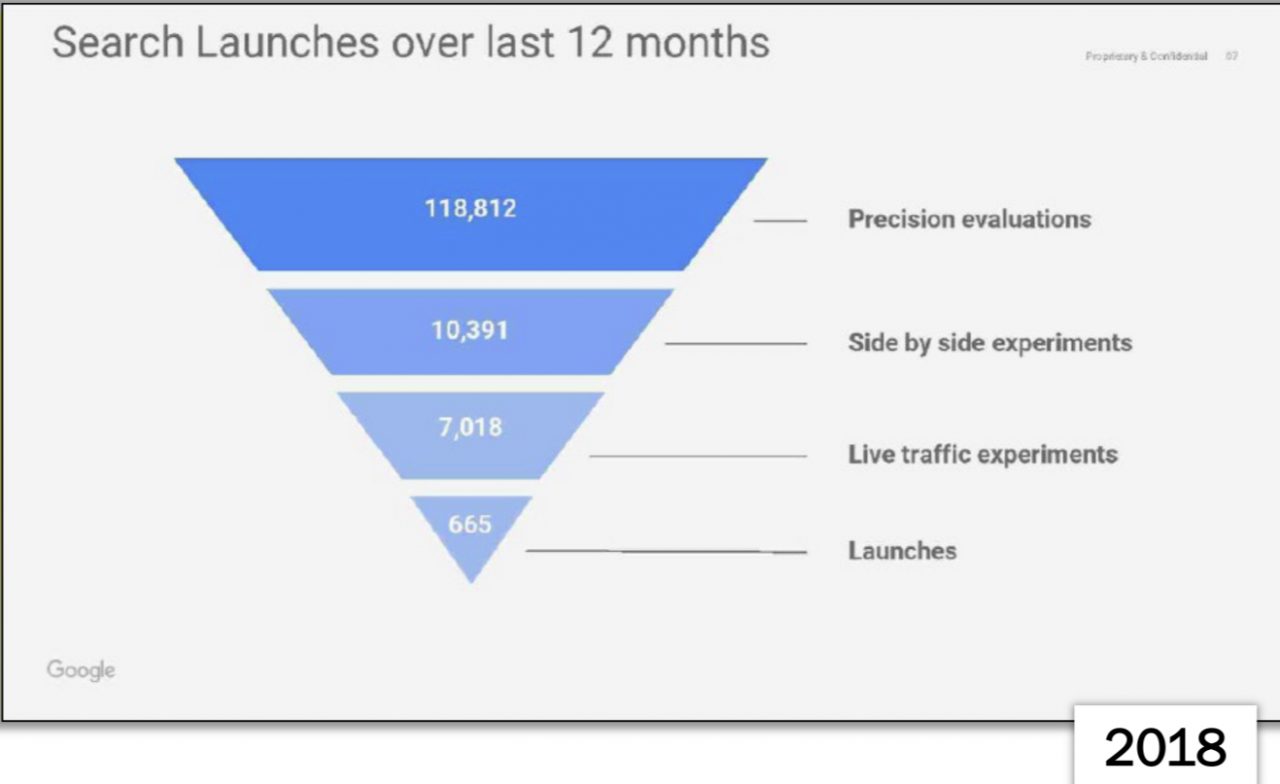
These tests would have resulted in “only” 4,725 launches. Documents from the 2023 anti-trust trial show that the number of launches has accelerated significantly since 2018, when there were “only” 665:
This modification project system lies at the core of Google’s search engine evolution strategy, often challenging teams with the stress of potential project rejection – which appears to be a common occurrence.
Google utilizes three main methods to assess the effectiveness of modifications:
- One automatic method, “Live traffic Experiments”, carried out in production on a limited proportion of traffic (generally less than 1%).
- Two manual methods, operated by “quality raters”: search quality tests, which consist in independently evaluating results in terms of quality, and side-by-side experiments, where humans are tasked with comparing a set of two different results on the same query.
Google is said to use 16,000 quality raters worldwide. Their evaluation results not only inform testing and anti-spam teams but also serve as training data for algorithms by feeding the Information Satisfaction (IS) indicator back into the systems.
Project approval at Google extends beyond quality metrics.
Engineers must demonstrate resource efficiency, detailing CPU, bandwidth, and storage requirements. This slide, from a results optimization project proposal, illustrates how managers justify deployments through both technical requirements and internal validation metrics.

Success in Google’s experimental pipeline demands more than positive test results—projects must demonstrate viability across cost, capacity, latency, and legal parameters.
The extensive API documentation in the latest leak confirms the scale of resources deployed by Google and its competitive advantage. Consider this: any improvement you might have imagined for the engine’s performance has likely already been conceived by a Google engineer, tested, and potentially implemented into production if proven successful.
If, on the other hand, the project has not been approved, there’s a good chance that traces of signals designed for this purpose will remain in the leak. This is especially true since some experimental projects may have been designed solely for testing, analysis, and reporting purposes. That’s why we cannot be certain that every method and scheme described in this API documentation is actually in use. A significant proportion of them might relate to projects that were either incomplete, abandoned, or never progressed beyond the experimental stage.
Read More in Our 2024 Google Leak Analysis Series:
Part 1: The Experiment-Driven Evolution of Google Search
Part 2: Understanding the Twiddler Framework
Part 3: From Words to Meaning: Google’s Advanced Lexical and Semantic Systems
Part 4: The Neural Revolution: Machine Learning Everywhere
Part 5: Click-data, NavBoost, Glue, and Beyond: Google is watching you!
Part 6 : How Does Google Search Work? The Hidden Infrastructure Powering Your Results

