
Google Records Your Every Move in Search Results
And it’s a well-known fact
- – When you click any Google search result, you don’t go straight to your destination. Instead, you’re briefly redirected through a URL that looks something like google.com/url?url=http://etc. Why? Because Google, like any other website, wants to measure its audience and track user behavior. And guess what – we actually get to see some of this juicy data in Google Search Console…
- – The « pogo-sticking » phenomenon has been extensively analyzed within SEO circles for over twenty years. This behavior pattern – where users rapidly navigate back to search results after clicking a result – serves as a clear user dissatisfaction signal. Google’s systems integrate this metric into their comprehensive user behavior analysis framework.
The 2023 antitrust trial revealed the surprising extent of user data integration in Google’s algorithms, particularly through Navboost and Glue. While the industry had anticipated this, the scale exceeded previous assumptions.
May’s leak added minor details but sparked confusion—particularly the misconception that Navboost uses Chrome data, which it absolutely does not.
Let’s examine what user signals Google actually employs in rankings, and how they might evolve in the future.
User Signals: What Google’s Log Data Captures
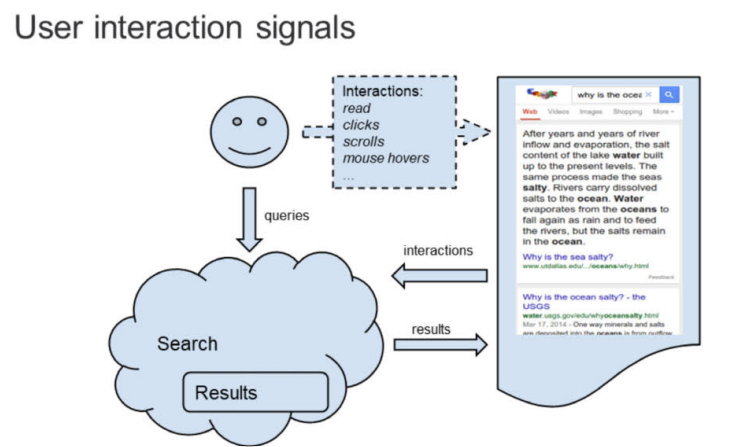
Google leverages user interaction patterns—both search queries and click behavior—to optimize result rankings and SERP feature selection. According to testimony from the 2023 antitrust trial, particularly from engineer Eric Lehman, these signals carry substantial weight in the final ranking algorithms.
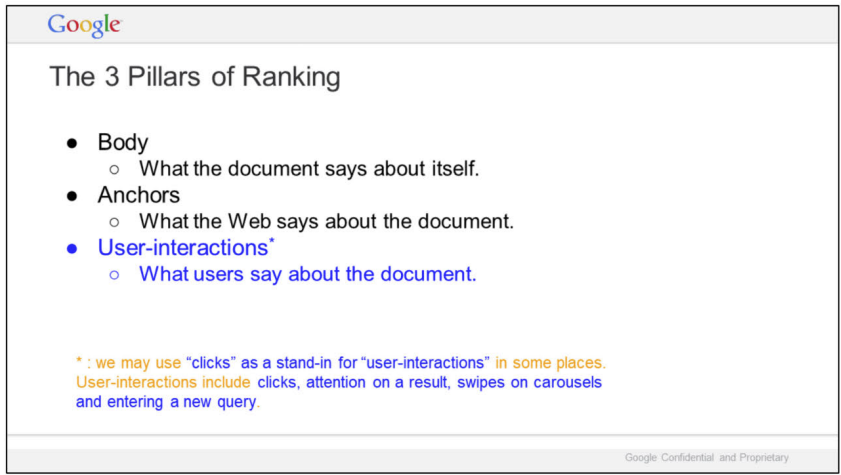
Navboost and Glue to refine final rankings
NavBoost is a re-ranking algorithm that refines search results based on implicit user feedback. The concept is straightforward: each user click acts as a vote for a particular result, similar to how links work. While this algorithm has been operating since 2005, Google expanded it to mobile platforms in Q1 2014.
When Google references click data, it encompasses a broader spectrum of user interactions: good and bad clicks, squashed and unsquashed data, impressions, click-through rates (CTR), and user engagement with Universal Search features, Knowledge Panels, and Web Answers.
- – good clicks: links that people click on and stay for a while
- – bad clicks: those that people click on and then quickly return to the results list
- – unsquashed: These clicks are specifically retained as they are deemed reliable indicators of user intent, resistant to manipulation. NavBoost’s effectiveness relies on its long-term approach, operating over a 13-month period and requiring a minimum threshold of data. This methodology follows the law of large numbers: substantial data volumes are necessary for the algorithm to produce relevant and reliable rankings.

The meaning of « Unicorn clicks » remains enigmatic. According to leaked information, users are categorized into different groups (consumers, Dasher, Unicorn…). While purely speculative, the Unicorn group might represent unlogged users – this aligns with Google Drive’s use of unicorn avatars for anonymous users. Alternatively, it could designate Google’s power users, similar to marketing terminology where « unicorn content » refers to the small percentage of content achieving exceptional engagement rates.
Tangram and Glue
Glue was only introduced in 2014, driven by Google’s need for a more sophisticated system to analyze user behavior on search results pages. This need emerged from the mobile-first approach and the proliferation of visual features in SERPs, including direct answers, Knowledge Graph elements, and other PAA.
The Glue framework consists of three main components: the Glue system itself, Glue data, and Glue signals, each serving a specific function. Beyond traditional clicks, it tracks a broader range of user interactions, including hover actions, scroll patterns, and viewport changes on mobile devices.

Dwells and luDwells: time spent examining results from Knowlegde Graph, Featured Snipped, and other universal search blocks
> Instant Glue
In addition to Glue, Google developed InstantGlue to work alongside Real Time Boost and Real Time Event twidlers (mentioned in this series’ second article). InstantGlue specifically targets emerging queries and breaking news content. This real-time pipeline collects the same user interaction signals as Glue but processes only the last 24 hours of log data, with updates occurring approximately every 10 minutes.
In Google’s ranking architecture, both NavBoost and Glue operate within Tangram at the Superroot level, where Google’s re-ranking mechanisms (Twidlers) are housed. These systems apply their modifications after the main Ascorer ranking system (which operates within Mustang) has completed its initial ranking.
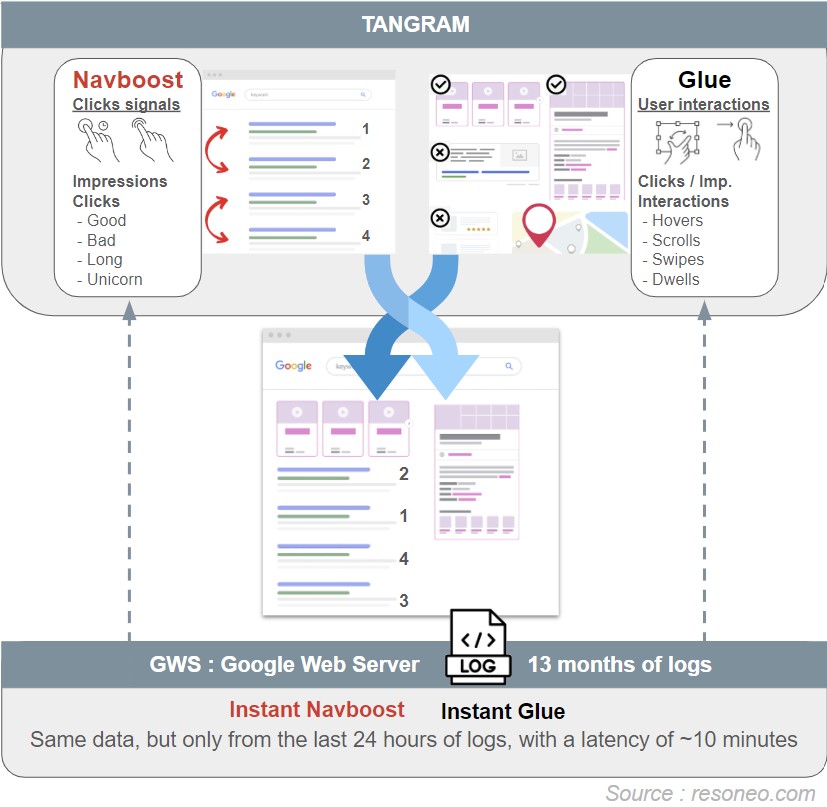
NavBoost and Glue significantly influence the final search rankings, although they operate alongside many other ranking factors. During his hearing, Eric Lehman explained:
« we have access to large amounts of text, and we also had access to lots of user data… (…) we really couldn’t read documents. (…) So we played this game of read by proxy. Show the text to people, we observe their reactions and we adopt them as our own. »

And in an internal e-mail he explained in 2019 that the impact was such that other teams were complaining…

Clicks data and Craps: exploiting user data on a larger scale
While « click data » plays a significant role in ranking, it’s also part of a system called CRAPS (Click and Results Prediction System), which operates across multiple levels. The signals generated by this system serve dual purposes: determining whether to retain URLs in the index and evaluating a document’s overall value. This data is segmented into various « slices » based on device type, country, language, and location.
For example, here are two interesting attributes
- – clickRadius50Percent: Google calculates a geographical radius within which a document receives 50% of its total clicks. This metric defines a webpage’s reach, ranging from ultra-local to international scope.

- – isImportant: Even when a URL shows weak performance across certain signals, Google tends to retain it in its indexes if it consistently receives « good clicks » from users.

This information corroborates revelations from the 2023 antitrust trial: click data’s influence extends beyond just ranking, permeating every stage of the search engine’s operation – from crawling and indexing to query refinement and information retrieval.

Click data holds even greater significance for image search, as Google has limited textual information to work with when assessing image relevance.
- – imageQualityClickSignals: example of an attribute used to define the quality of an image according to click signals.

The reference to « CPS Personal Data » appears to relate to the Crown Prosecution Service in the UK, the agency responsible for conducting legal proceedings. As part of investigations, Google may be required to provide these click data records to prosecutors..
- – The leak reveals that Google measures two specific metrics for images: « Hovers to Impressions » (h2i) and « Hovers to Clicks » ratios. These metrics function as image-specific CTR adaptations, measuring user engagement. By dividing the number of zooms or hovers by either clicks or impressions, Google calculates how effectively an image captures attention and generates clicks.

- – imageExactBoost: When images achieve a sufficiently high trust score, Google assigns them labels indicating their most relevant query types. These labeled images then receive enhanced visibility through the imageExactBoost twidler.

- – clickMagnetScore: analyzes « bad clicks » to detect images that have high click-appeal but lead to disappointing landing pages – essentially functioning as a linkbait detector ^^.

Click Data: A Training Foundation for Major Systems
Google leverages click data to train its key machine learning algorithms, including RankBrain, Deeprank, RankEmbed, and QBST. Notably, MUM was the sole exception, operating effectively without click data – a development that surprised Google’s own engineers.

While RankBrain, like NavBoost, initially required 13 months of log data for training, these large models now appear to need significantly less historical data. However, they do require regular updates with fresh data every two to three months.
These deep learning algorithms utilize a « generalization » approach to training, where the model learns to make informed decisions even in scenarios without direct data. Through pattern recognition in click data, the system can predict user behavior in similar contexts – for instance, accurately anticipating the 1001st click based on patterns identified from 1000 previous clicks in a specific context. This ability to extrapolate from learned patterns ensures the algorithms’ long-term effectiveness.
In contrast, « memorization » systems like NavBoost and QBST operate by storing and analyzing historical data patterns. These systems excel when they have access to abundant data but become less effective with limited data – particularly for long-tail queries that occur infrequently.
Chrome Data Usage: Fact or Fiction?
The Google antitrust trial sparked significant debate about Google’s competitive advantage over Microsoft. A striking example: while Google needed only 13 months of click data to power NavBoost or QBST, Bing would have required 17 years of logs to amass an equivalent volume. The discussions also highlighted Chrome’s market dominance as the default browser, Google’s billion-dollar payments to Apple and Samsung, and various partnerships that help maintain Google’s position as the primary gateway to the web.
Could Google have hidden Chrome’s data usage during the most significant antitrust trial in 25 years? This seems unlikely considering the intense scrutiny of NavBoost, Glue, and other click-data systems, along with testimony from long-serving Google employees under oath.
Pure traffic data from Chrome would provide limited insight into page relevance – knowing a page receives high traffic reveals little about its relevance to specific queries. This aligns with observations from black hat SEO: push traffic campaigns mostly succeed when incorporating initial search queries, primarily affecting instantNavBoost/instantGlue.These manipulations typically yield only short-term results, ceasing to work once artificial traffic stops. Long-term manipulation proves particularly challenging given NavBoost’s 13-month historical data requirement.
On the other hand, Google does use Chrome data, to personalize results based on your search history and many other factors: when you’re logged in Google knows everything about you and tracks you down very precisely to personalize your experience on its services (Search, Ads, Map, Discover, etc.). If you really want to scare yourself, take a look at the MyActivity report ^^
But Google doesn’t seem to track your mouse movements, completed forms and other conversions outside their own platforms, as we read recently. It’s important to avoid misconceptions that could lead to implementing strategies with no actual benefit (at least for your SEO)…
After this clarification, and based on the leaked information, Chrome data appears to be utilized in the following ways:
- as a signal of overall site quality via Nsr, among dozens of others
- to discover new urls: anyone working in the web industry has found themselves with an online pre-prod version that had to be de-indexed to avoid duplicate content… or a PDF indexed in some other way…
- – to help it select sitelinks:
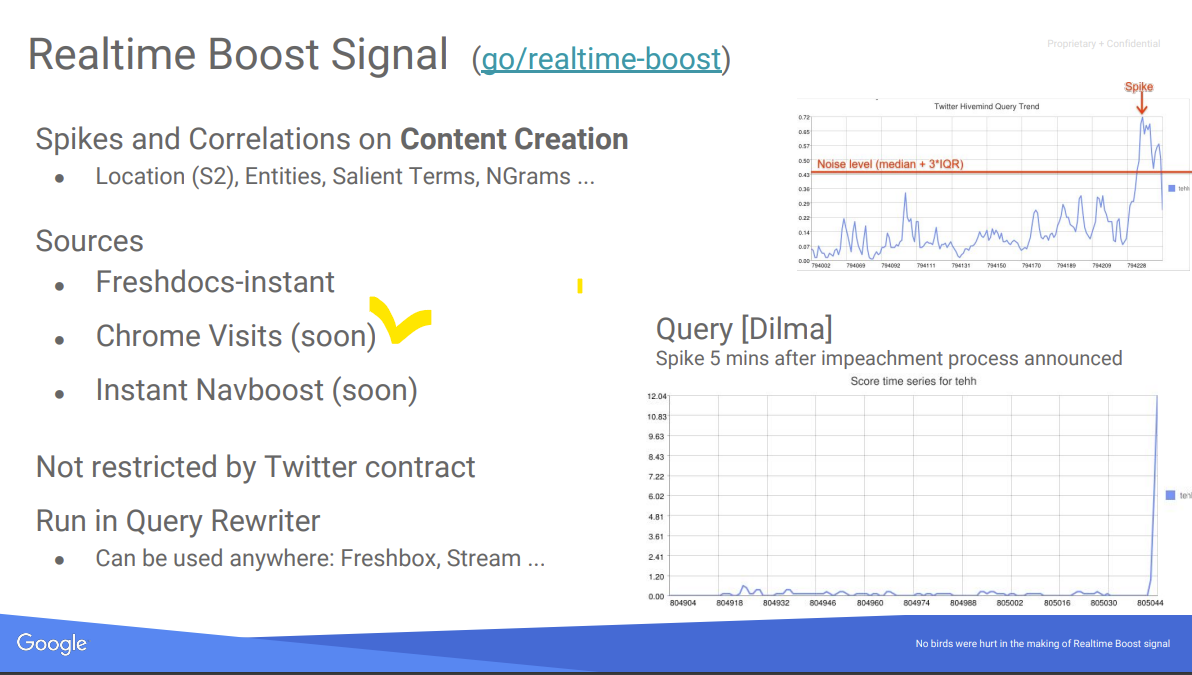
Note that in the Google doc “Sitemap” refers to groups of URLs, and has nothing to do with xml sitemaps… - – to identify spikes in traffic on a URL that would make the news, as d prescribed on tesentation of the Realtime Boost Signal twidler (can impact News and Discover in particular, but also boost temporarly your ranking in classic SERPs):
- – and of course for Core Web Vitals, which are also featured in the leak (see Volt)

And that’s about it. If Google were extensively using Chrome data to refine its search rankings, the leak would likely contain far more models and attributes detailing these processes – which it doesn’t.
But Google could have implemented – and may already use – a system that weights clicks based on user profiles, a concept originally mentioned in their 2006 founding patent. For instance, experienced users typically select results more quickly than novices, potentially earning their clicks greater algorithmic weight. Similarly, users who frequently research specific topics like law or IT may be considered domain experts, and their clicks might receive higher weighting in those fields.

Quality Raters evaluations
While RankBrain, DeepRank, and RankEmbed-BERT are trained using click and query data from search results pages, these systems – along with QBST – undergo additional fine-tuning using Quality Raters (QR) test data, specifically through the Information Satisfaction (IS) indicator.
As mentioned in this article, the IS score serves as a crucial metric for evaluating Google’s search quality, drawing from assessments by 16,000 Quality Raters worldwide. Though we won’t delve into the full details here – as extensive documentation and Google’s public guidelines already cover this – it’s important to note that these evaluations focus on two main KPIs:
- – Needs Met focuses on the needs of users and the usefulness of the result.

- – The Page Quality indicator is not query-dependent, unlike Needs Met, and focuses solely on page quality.

The leak tells us that QRs are not just used to evaluate results or pages/sites, but also entities. It includes the “humanRatings” attribute, which depends on the Repository Webref Entity Join model, which represents all the information Google knows for each entity.

EWOK is the name of the platform on which Google’s evaluators work. They also evaluate entity mentions (Single Mention Rating):

Quality Raters appear to be tasked with verifying whether entities are correctly categorized within their respective topics. There’s even a surprising Boolean attribute raterCanUnderstantTopic: the evaluator is able to understand the topic ^^
Can AI Replace Human Quality Raters?
It’s intriguing to observe Google’s aggressive pivot toward AI-powered ranking mechanisms. While this transformation won’t happen immediately, and Google still relies heavily on valuable click data, the future might be closer than we think. An AI system capable of independently evaluating user satisfaction could emerge in the near future. Google’s engineers are likely already developing such systems, and several early indicators support this possibility:
- – At the beginning of 2024, Google terminated its contract with Appen, one of the companies that provided several thousand QRs.
- – At the same time, QRs are being asked to spend more and more time on tasks involving the evaluation of AI-generated responses (Bard in 2023, then Gemini & SGE).
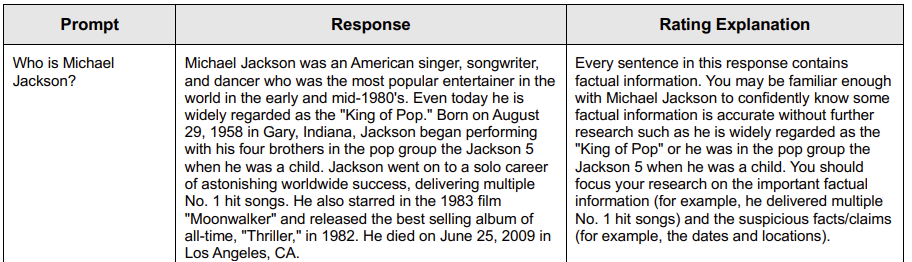
- – And some of the leak’s attributes show that Google sometimes tries to emulate a human evaluation: for example contentEffort…
In the QR guidelines, effort is one of the four important KPIs of content quality, along with originality, skill and accuracy:

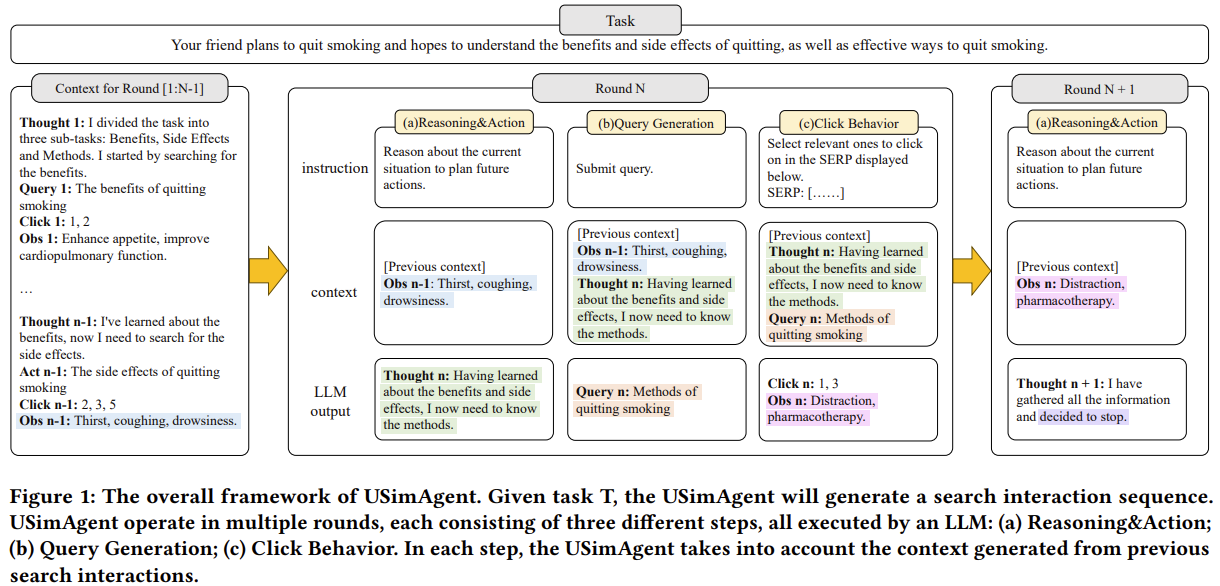
Recent research, particularly the patent « USimAgent: Large Language Models for Simulating Search Users, » demonstrates AI’s growing capability to accurately replicate user search behaviors. This framework leverages LLMs to simulate various user interactions – including queries, clicks, and stops – and reportedly achieves better performance than existing query generation methods.
Given Google’s vast repository of historical tests and massive indexes, they have sufficient data to gradually phase out dependence on click data and human evaluators. SEO professionals will likely find ways to leverage these new technologies too. Can you see where this is heading? Have you already trained your AI SEO agent on those 170-page Quality Rater Guidelines? 🙂
In our next article, we’ll explore Google’s technical infrastructure and core systems…
Read More in Our 2024 Google Leak Analysis Series:
Part 1: The Experiment-Driven Evolution of Google Search
Part 2: Understanding the Twiddler Framework
Part 3: From Words to Meaning: Google’s Advanced Lexical and Semantic Systems
Part 4: The Neural Revolution: Machine Learning Everywhere
Part 5: Click-data, NavBoost, Glue, and Beyond: Google is watching you!
Part 6 : How Does Google Search Work? The Hidden Infrastructure Powering Your Results

