
Google Search, le moteur de recherche le plus utilisé au monde, repose sur une infrastructure complexe et des environnements de développement sur mesure. Nous vous proposons de découvrir ces systèmes aux noms parfois explicites, souvent fantaisistes, en s’appuyant sur des informations provenant de diverses sources, le leak de l’API Content Warehouse bien sûr, mais aussi les pièces à conviction des procès antitrust, des présentations publiques d’ingénieurs Google ou des témoignages d’anciens employés (CV, profils LinkedIn, blogs, forums HackerNews, etc.).
Disclaimer : Nous n’avons donc pas bénéficié d’informations d’insiders pour réaliser cet article. Ne prenez pas pour argent comptant tout ce qui est écrit ici. Nous avons sûrement fait de nombreuses approximations et interprétations de notre compréhension du fonctionnement de Google. Tout ce qui n’est pas clairement documenté et recoupé par des sources est potentiellement faux.
L’environnement de développement Google
Softwares et logiciels internes
Parmi les premiers outils que l’on s’attendait à retrouver dans le leak, on a bien sûr le version control system (VCS) maison de Google, Piper, que l’on pourrait comparer à Git. On trouve également quelques mentions de l’outil de production utilisé en interne : Blaze, rendu open source en 2015 sous le nom de Bazel – mais aucune trace du système de test, Forge. On trouve également quelques traces de l’outil de production de la team SRE (Site Reliability Engineering) : Boq et son système de nodes – voir ci-dessous un exemple d’exploitation pour les Complexe Queries Rewrite (réécriture des requêtes complexes) :

Côté langages, bien que Google soit connu pour avoir développé le Go, le C++ reste prédominant. On trouve aussi un peu de Java et, dans une moindre mesure, du Python. Les fichiers les plus couramment rencontrés ont les extensions suivantes :
- .cc et .h pour le C++
- .java pour Java
- .proto pour les Protocol Buffers (protobuf)
Les services de Google communiquent via une infrastructure d’appel de procédure à distance (RPC – Remote Procedure Call) nommée Stubby, dont il existe là aussi une version open source, gRPC.
Les données sont encodées et transférées entre les différents systèmes du moteur via des « protocol buffers » (protobuf), une techno développée par Google supposée plus efficaces que JSON : plus simples, plus petits, plus rapides et moins ambigus.
Côté softwares qui s’occupent du “management des machines”, stockage et bases de données, aucune mention de Colossus, mais on a bien des occurrences de Spanner, Bigtable, SSTable, Blobstore, Borg ou Chubby qui travaillent de pair avec Colossus. Pour rappel Colossus est un système de fichiers au niveau du cluster, successeur du Google File System (GFS).
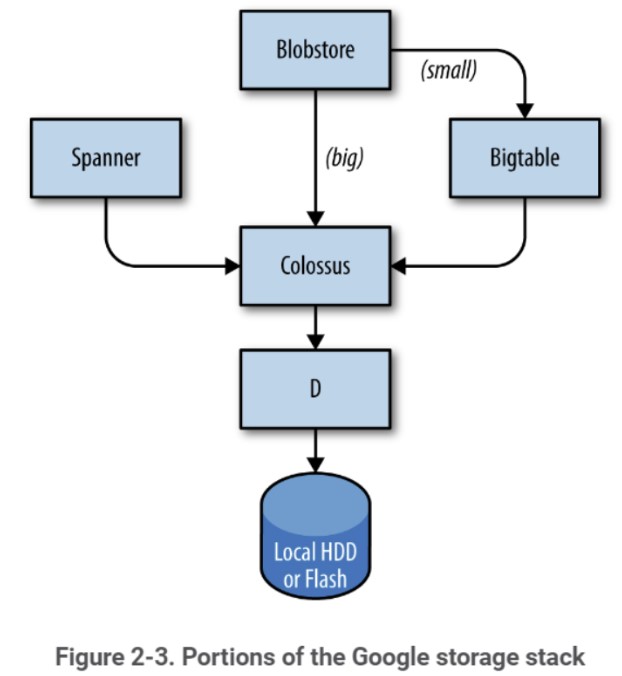
Percolator est également absent du leak (et à fortiori Caffeine). On trouve quelques mentions de MapReduced bien que Google ait annoncé l’avoir remplacé par Dataflow – avec l’aide de Flume et Millwheel que l’on ne trouve pas non plus dans l’API du Leak.
Le Monorepo Google3
Au cœur de l’environnement de développement de Google se trouve un concept clé : le monorepo, un repository qui héberge le code de la majorité des produits Google (sauf Chrome et Android qui sont gérés à part). On trouve dans ce dépôt de code source le moteur de recherche, Youtube, Map, Assistant, Lens… Son nom interne est Google3 et presque tous les ingénieurs de Google y ont accès. Cette approche, bien que non conventionnelle pour une entreprise de cette taille, présente plusieurs avantages :
- Facilité de collaboration entre équipes
- Uniformité des outils et des processus
- Possibilité de refactoriser à grande échelle
Seul un faible pourcentage du code (environ 0,1%) est isolé pour des raisons de confidentialité, principalement ce qui concerne la lutte anti-spam. La petite partie réservée à quelques équipes serait appelée HIP pour “High-value Intellectual Property”, c’est là que l’on devrait trouver par exemple le code de Nsr ou de PageRankNS.
Le nombre de références au repository est important dans le leak, et permet de mieux comprendre à la fois la structure globale du code et donne des indices sur l’appartenance de tel ou tel composant à un environnement spécifique.
Nous avons extrait et compilé du leak Google la branche qualité du monorepo google3 :

Et voici un échantillon de ce qu’on peut trouve dans les autres branches :

Les bonnes pratiques internes imposent de documenter le code dans le wiki maison accessible via les liens go/xxx que l’on retrouve également en nombre dans le leak. Malheureusement, pour pouvoir y accéder, il faut être ingénieur chez Google ^^

En 2015, le monorepo Google3 pesait déjà 86TB pour deux milliards de lignes de code, avec un graphe de dépendances extrêmement complexe. Les 25 000 ingénieurs du groupe réalisaient 40 000 commits par jour ! Si vous souhaitez creuser cette partie nous vous recommandons fortement la lecture de ce document : Why Google Stores Billions of Lines of Code in a Single Repository (PDF)
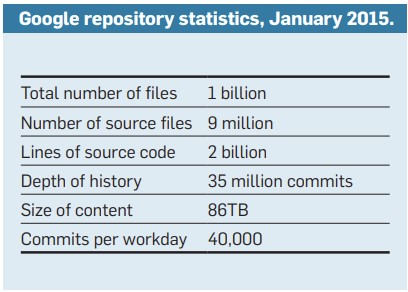
Autant dire que le leak auquel nous avons accès ne représente qu’une infime partie du code Google… Mais cela reste vraiment exclusif de voir cette petite fenêtre ouverte sur la structure de ce repository.
Intéressons-nous maintenant aux nombreux autres systèmes découverts grâce au Google leak de mai 2024 qui permettent au moteur de délivrer ses fameuses pages de résultats. Nous allons partir de la phase de crawl pour arriver à la requête utilisateur, en passant par les principaux systèmes intermédiaires.
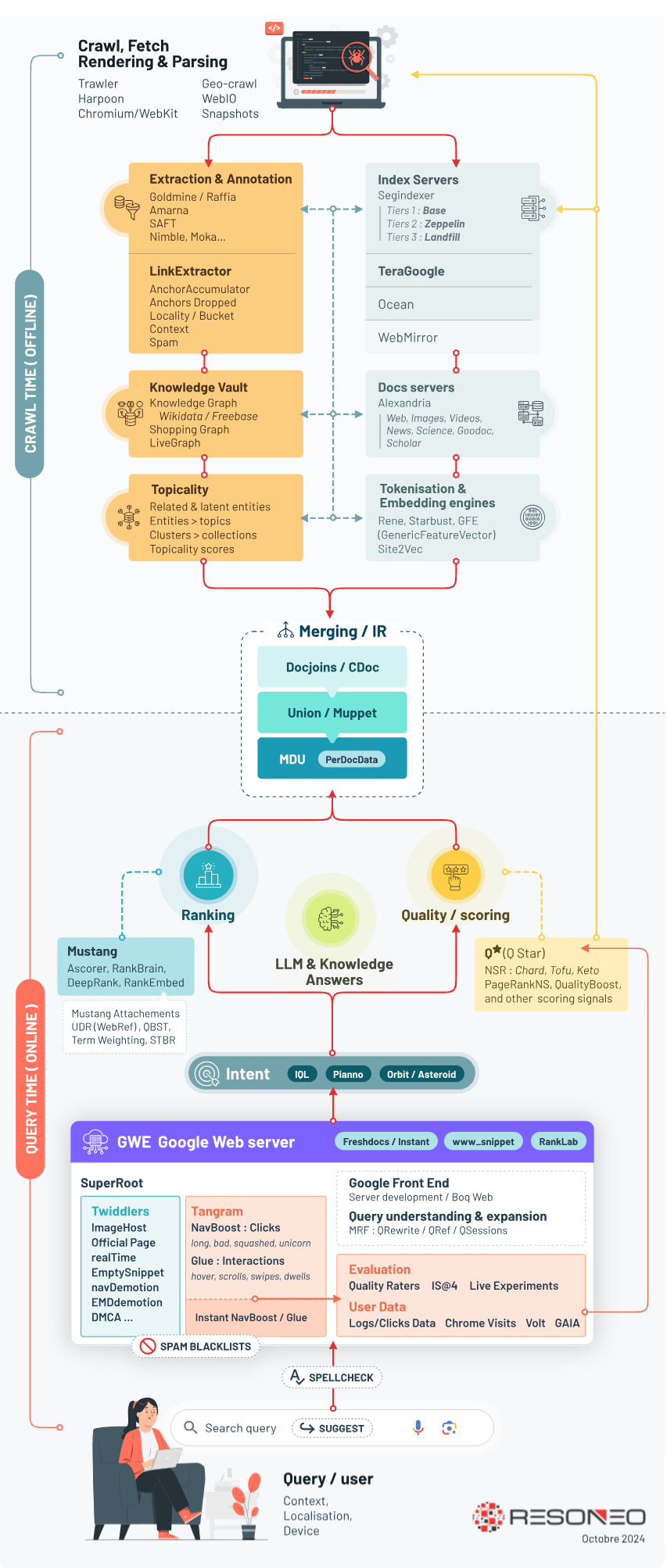
Les systèmes de Google Search en une infographie
Plusieurs propositions de schématisation de l’infrastructure de Google Search ont déjà été réalisées par des SEO, dont deux particulièrement travaillées :
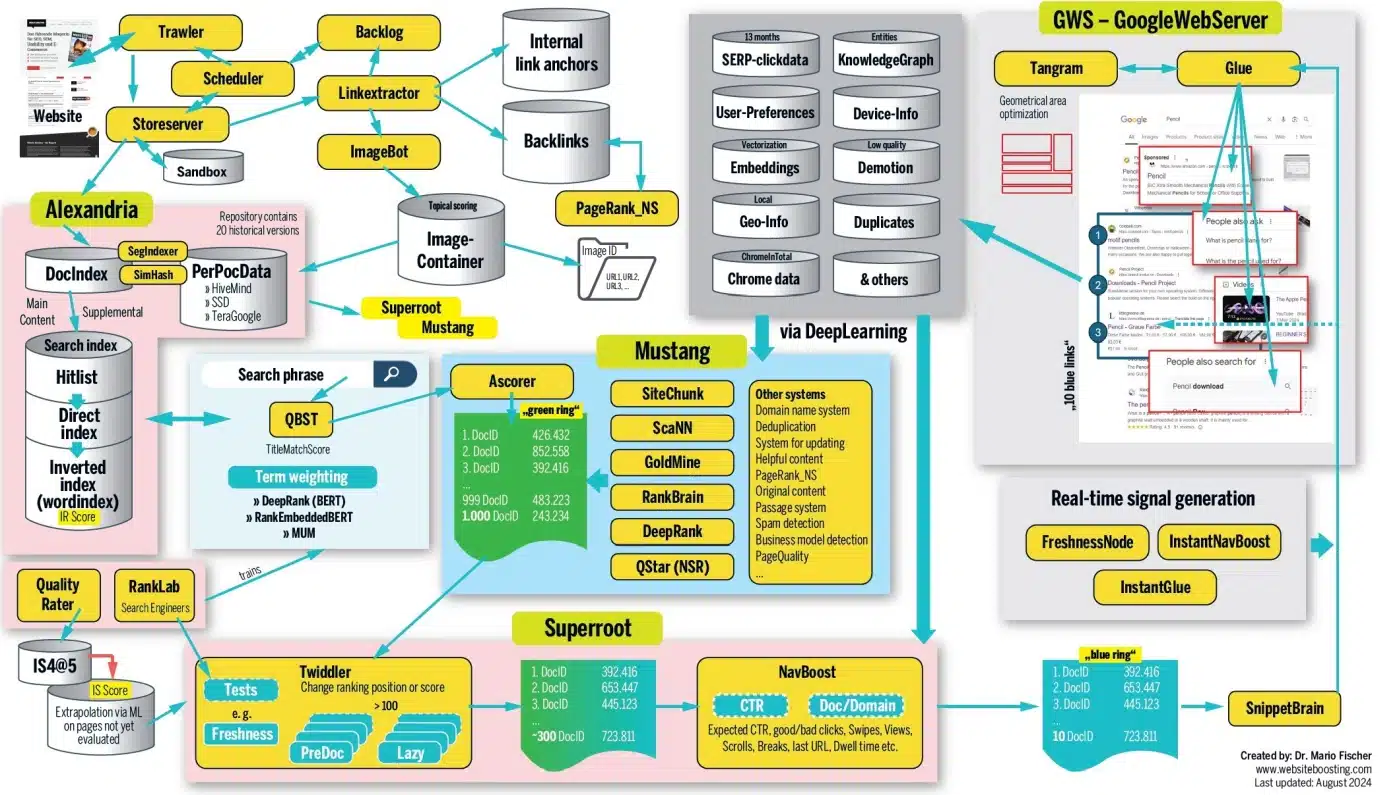
Une première publiée par Mario Fischer sur Search Engine Land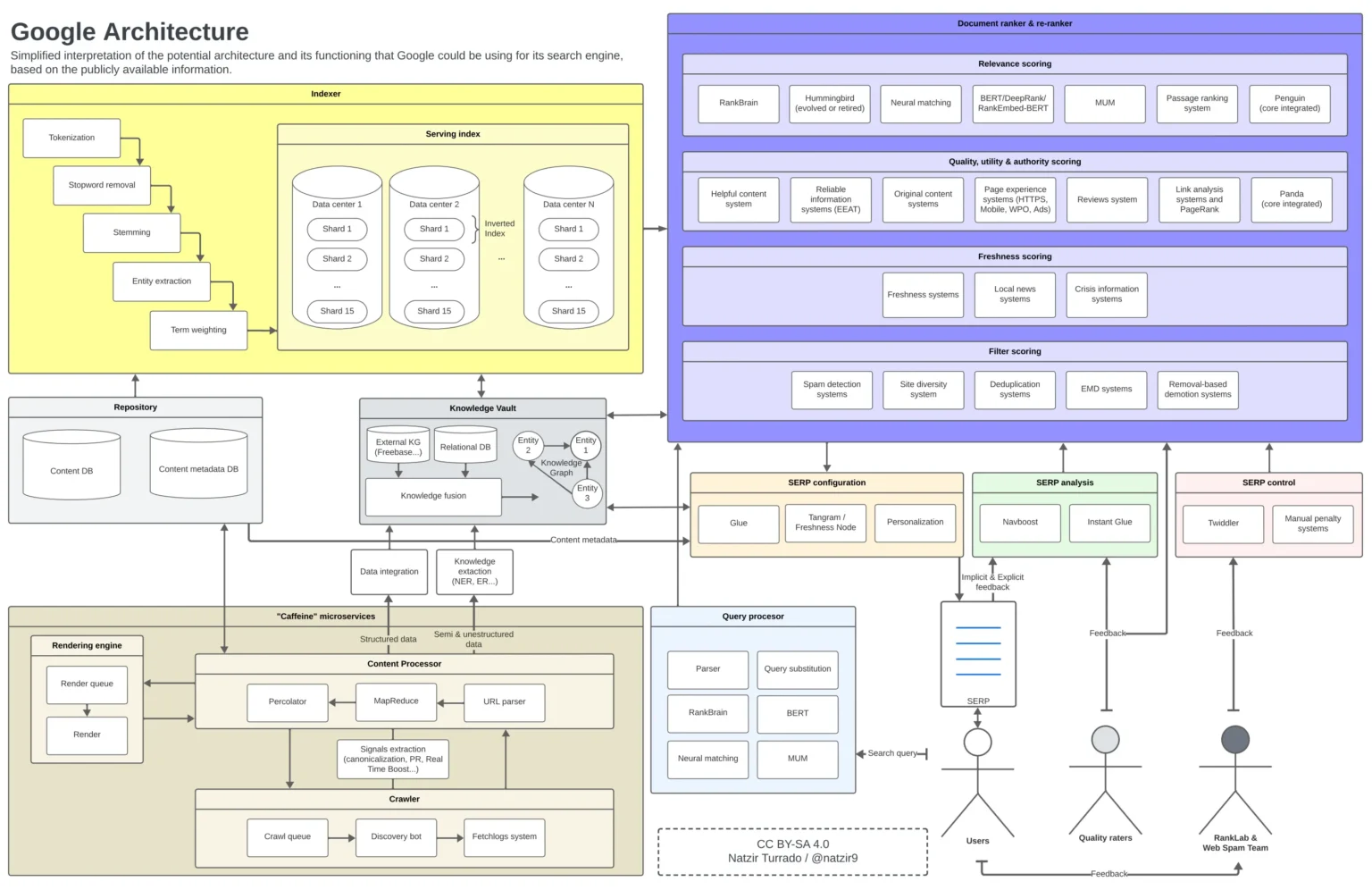
Une seconde publiée par Natzir Turrado sur son site personnel
Nous vous proposons une nouvelle représentation, cette fois organisée en deux parties :
- En partie haute : ce qui est mis en œuvre off line (crawl time) notamment tout ce qui concerne la découverte, extraction, parsing, annotation et indexation de la donnée.
- En partie basse : ce qui est activé au moment de la requête (query time), particulièrement l’interprétation de la requête, la génération de la page de résultats, et l’analyse du comportement des utilisateurs à des fins de reranking et d’entrainement.
- Entre les deux se trouvent les mecanismes de « merging / information retrieval » qui font la jonction entre d’une part les données agrégées au niveau de l’indexation et d’autre part la phase de serving déclenchée à chaque requête utilisateur.
Notez que nous avons exclu de ce schéma les dispositifs concernant Youtube, Assistant, Map, Lens, etc. pour ne garder que le Search, par soucis de simplification. Vous pouvez cliquer sur une partie du schéma afin d’acéder directement à l’explication correspondante.
Décryptage des différentes étapes
L’architecture de Google Search se décompose en plusieurs étapes principales :
- 1 – Crawl / Fetch / Parsing & Rendering
- 2 – Indexing
- 3 – Annotation / Embedding & Topicality
- 4 – Merging & Information Retrieval
- 5 – Scoring & Quality / Ranking
- 6 – Serving : re-ranking, query expansion, training data…
1 – CRAWL / FETCH / PARSING & RENDERING
Trawler est le système principal de crawling & fetching chez Google. Il est responsable de récupérer les pages web, de gérer les redirections, les en-têtes HTTP, les certificats SSL, et de respecter les règles du fichier robots.txt. En plus de cela, il collecte des statistiques détaillées pour chaque page récupérée.
Harpoon, quant à lui, sert d’interface client à Trawler et permet à d’autres services de déclencher des fetchs à la demande via Trawler, en cas de demande d’inspection d’URL via la GSC par exemple. Ces deux dispositifs portent donc très bien leur nom : trawler signifie chalutier, quant à harpoon, inutile de le traduire ^^
Une fois la page récupérée, Trawler renvoie des informations complètes sur le fetch, telles que le temps de téléchargement et le type de contenu. Après le fetch, une étape de rendering peut avoir lieu. WebKit étant tombé dans les mains d’Apple en 2013, Google exploite désormais Blink, via Chromium, pour exécuter le JavaScript, appliquer le CSS, et capturer l’état final de la page. Il génère des screenshots de la page et des métriques sur la qualité du rendu. Le schéma SnapshotTextNode nous apprend que Google va même plus loin : il fait des snapshots des différents blocs de texte d’une page, en identifiant la taille de police, la présence de liens et les séparateurs visuels dans la page.

Le système de crawl intègre également certaines particularités :
- le geo-crawl, permettant de simuler des accès locaux depuis différentes régions géographiques,
- le caching qui évite de récupérer à nouveau des contenus inchangés,
- et la gestion de la charge grâce à WebIO.
WebIO (Web Input Output) est le nouveau système de mesure et de gestion de la charge du crawl. Il est apparu en 2023 d’après les leaks. Or les récentes communications publiques de Google nous ont appris que le moteur est en phase de grands travaux afin de préserver ses ressources de crawl et d’indexation, donc il n’est pas étonnant de voir cette partie en pleine évolution.

L’ensemble du dispositif de crawl est alimenté par de nombreuses métriques et modèles qui lui permettent de décider de ne pas crawler telle ou telle page si la probabilité qu’elle soit de mauvaise qualité ou dupliquée est forte.
Une fois les pages crawlées et analysées, elles doivent être organisées efficacement pour permettre leur récupération rapide lors des recherches. C’est là qu’intervient le système d’indexation de Google.
2 – INDEXING
Dans un épisode de questions réponses en 2021 Gary Illyes nous renseignait sur l’utilisation d’un index par niveau, ou “tiers index” en anglais.

Et nous retrouvons cette information de manière plus concrète dans l’API Google:

Les trois tiers de l’index Google :
- Base : Ce niveau est le plus rapide, souvent associé à des systèmes de mémoire vive (RAM). Il contient les documents les plus fréquemment consultés, les plus pertinents, et ceux qui sont mis à jour régulièrement. Ce sont les pages les plus importantes pour l’utilisateur comme pour le moteur.
- Zeppelins : Niveau intermédiaire, généralement stocké sur des disques SSD, qui contient des pages souvent consultées mais moins souvent mises à jour que celles du niveau Base. Le nom « Zeppelin » – un ballon dirigeable de la 1ère guerre mondiale – pourrait refléter l’idée que ces pages « montent et descendent » en termes de priorité dans l’index, en fonction de leur pertinence actuelle.
- Landfill (“Décharge” en anglais) : Ce niveau contient la majorité des documents, stockés sur des disques durs (HDD) offrant un bon compromis entre coût et capacité. Les documents ici sont rarement mis à jour, souvent de moindre qualité ou moins consultés. Ce niveau se rapproche d’une « décharge », où les documents sont mis de côté, avec une faible probabilité d’être re-crawlés.
Gestion des documents dans les tiers :
Les documents peuvent passer d’un niveau à l’autre en fonction de leur qualité, leur pertinence et leur fréquence de mise à jour. Un document qui perd en popularité ou en mise à jour régulière pourrait se retrouver dans le tiers inférieur. Ainsi, un document du niveau Base peut descendre vers Zeppelins, puis Landfill, au fil du temps.
Certains systèmes d’indexation sont utilisés pour des types de documents et de contenus spécifiques. Ainsi les documents dupliqués sont stockés dans l’environnement WebMirror tandis qu’Ocean s’occupe plus particulièrement de l’indexation des livres, brevets et autres documents scientifiques.
Le rôle du scaledSelectionTierRank
Le scaledSelectionTierRank est un score normalisé de 0 à 32 767 qui détermine la position d’un document au sein d’un niveau d’index donné. Ce score représente à la fois la qualité du document et la fréquence de mise à jour/consultation dans une couche spécifique. En gros, plus un document a un score élevé, plus il sera en haut du niveau de sélection, ce qui augmente ses chances d’être servi rapidement dans les résultats de recherche. L’intérêt de maintenir un score correspondant à sa position dans l’index est de pouvoir le multiplier avec d’autres scores compilés afin de rapidement retrouver et classer une liste de résultats.
Segindexer
Segindexer est le composant chargé de la classification des documents dans les 3 niveaux d’index avant qu’ils ne soient finalement intégrés dans les bases de données. Il intègre également diverses propriétés du document parmi lesquelles le title, le nombre de tokens du document, le début du texte ou la taille moyenne de la police.
TeraGoogle
TeraGoogle est le système d’index secondaire de Google, destiné à gérer la « long tail » des documents, c’est-à-dire les documents moins fréquemment consultés mais qui représentent un volume immense de données, sans doute plus de 95% des documents connus par Google. Il a été conçu notamment par Anna Peterson et Soham Mazumdar dès 2006. Du jour au lendemain, il a permis de multiplier par 10 la capacité d’indexation, tout en étant 50 fois moins cher par recherche et par document que l’infrastructure précédente. Ce gain d’efficacité a été obtenu notamment grâce à l’utilisation de la mémoire flash, beaucoup plus flexible que la RAM traditionnelle.
L’intérêt de passer par la mémoire flash est que cela offre beaucoup plus de marge quant aux informations qu’il est possible d’exploiter pour scorer les documents au moment de la requête. Cela permet de s’appuyer sur une plus grande partie de la requête en tant que contexte. Avec un index sur disque, il faut calculer à l’avance des scores pour chaque terme et il n’est possible de les fusionner qu’à l’aide de formules arithmétiques simples.
En 2007, TeraGoogle a remporté le Google’s Founders’ Award – un prix spécial décerné aux meilleurs projets internes par les deux fondateurs de Google. Lorsque vous recherchez une information de niche, par exemple dans un article académique très pointu et ancien, c’est TeraGoogle qui est à l’œuvre ! Ci dessous vous trouverez deux profils Linkedin d’ingérieurs ayant contribué au développement de TeraGoogle et confirmant certaines informations.
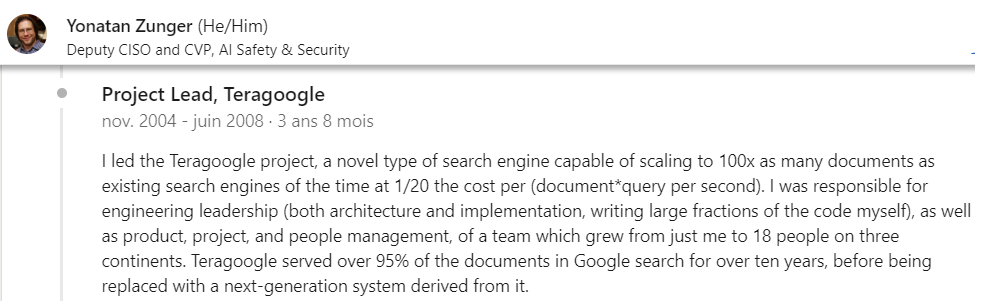
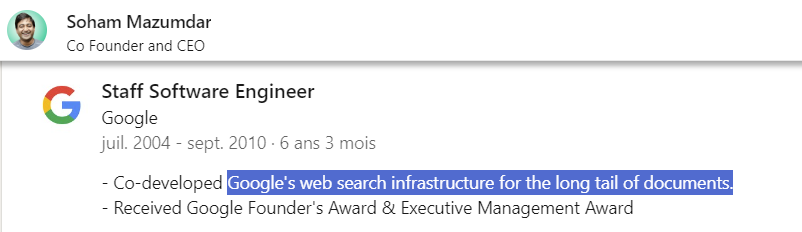
Alexandria
Alexandria est le système d’indexation principal en aval des mécanismes de crawl, fetch , parsing et stockage brut des documents. Si dans les index primaires et secondaires on trouve l’intégralité des documents crawlés, Alexandria s’apparente plutôt à un pipeline d’indexation sous la forme d’une base de données distribuée. En plus du stockage des documents et de leurs tokens, Alexandria compile diverses informations : contexte du crawl, duplication, annotations, images, ancres et liens, géolocalisation et autres métadonnées de rendu. Il se sert également des données de Composite Doc et alimente différents DocJoiners. Pour résumer, ce dispositif prépare les index à être utilisés par les phases d’IR (Information Retrieval) et de serving.
Exemple d’information qui sera extraite d’Alexandria pour alimenter les docjoins nécessaires au traitement de la requête :

Dans cet attribut, on apprend qu’Alexandria renseigne sur la source des ancres de liens : les ancres issues du Tiers1 – Base – sont de bonne qualité, contrairement à ceux qui se trouvent dans Landfill…
Au-delà de l’indexation pure, Google doit comprendre et catégoriser le contenu des pages pour fournir des résultats pertinents. C’est le rôle des systèmes d’annotation et d’embedding.
3 – ANNOTATIONS / EMBEDDING & TOPICALITY
En parallèle, chaque mot de chaque document est tokenisé et vectorisé par des moteurs d’embedding : Starbust, Rene ou GFE (Generic Feature Vector). Les algorithmes de machine learning ont besoin de ces bases de données vectorielles, de même que Gemini pour générer les AI Overviews.
Les leaks révèlent que Google ne se contente pas de vectoriser les token, phases, paragraphes ou documents, mais aussi des sites complets ou des parties de site (ils parlent de « sitechunk »). On trouve par exemple l’attribut site2vecEmbeddingEncoded au niveau des signaux Nsr mais les sitechunks servent à de multiples autres systèmes, par exemple pour l’identification des chaînes de magasin dans le KG et la recherche locale, ou pour aider SpamBrain à détecter le spam. Il est assez grisant de voir que Google – l’inventeur du fameux Word2Vec – a également développé un Site2Vec.
Ce type d’embedding permet notamment de définir la topicality d’un document / sitechunk / site. On trouve par exemple l’attribut siteFocusScore, pour définir à quel point un site est focalisé sur un topic, ou siteRadius, qui permet d’identifier à quel point pageEmbedding s’éloigne du siteEmbedding, et donc si le site semble légitime sur tel ou tel sujet. Par défaut, une nouvelle page qui n’a pas encore été évaluée par Google se voit attribuer un score correspondant à la moyenne du sitechunk auquel elle appartient.

Ce type de signaux est vraisemblablement à l’origine de la dernière annonce de Google en octobre 2024 expliquant que « Google cherche à comprendre si une section d’un site est indépendante ou nettement différente du contenu principal du site. Cela nous permet d’extraire les informations les plus utiles d’un ensemble de sites. » Une annonce qui correspond à la baisse récente de ranking des sites Fortunes et Forbes…
On trouve également dans les leaks de nombreux dispositifs d’annotation et d’extraction permettant de construire les metadata des différents documents indexés.
Ainsi, Goldmine, un des principaux pipelines d’annotation, est capable de créer des embeddings pour les passages de texte, analyser les sentiments, attribuer des scores géolocalisés, identifier des mentions d’entités ou évaluer la lisibilité d’un contenu. Il travaille souvent en parallèle de Raffia, un autre pipeline d’annotation, et de SAFT (Structured Annotation Framework and Toolkit) qui analyse et structure les documents pour enrichir la compréhension sémantique des contenus. SAFT segmente les textes en tokens, identifie les entités nommées et établit des relations entre elles pour capturer le contexte. En plus de détecter les mesures (quantités, unités) et de gérer la coréférence (liens entre mentions répétées d’une même entité), SAFT construit une représentation sémantique complète des documents, incluant liens, titres, et relations complexes. D’autres mécanismes d’annotation sont plus spécialisés tels que Amarna pour les images, Nimble pour les médias ou Moka pour les produits.
Les liens et leurs ancres passent eux aussi par différents dispositifs d’extraction et de labellisation. Ainsi les liens internes (“local”) ou externes (“nonlocal”) sont décortiqués par le LinkExtractor et AnchorAccumulator de Google.

Google communique depuis plusieurs années sur une prise en compte des liens dans l’algorithme de plus en plus faible. On comprend désormais pourquoi, la majorité des liens étant finalement rejetée (“dropped”) et donc non prise en compte pour le classement. Et même lorsqu’ils sont retenus, plusieurs limites dans le nombre d’ancres de liens (200, 1 000, 5 000 ou 10 000) sont appliquées avant que Google ne les exclue. Cela peut par exemple impacter le maillage interne avec variation d’ancres ou les backlinks sitewide.

Source : Google Leak – Model.Anchors Redundant Anchor Info

Source : Google Leak – Model.Indexing Docjoiner Anchor Statistics Redundant Anchor Info
Google compile donc de nombreux signaux concernant les liens, confirmant dans l’ensemble ce que les SEO avaient identifié de manière empirique. Les paramètres suivants semblent par exemple pris en compte :
– Les liens issus des sites de presse de qualité ;
– La taille de la police, de même que le contexte : les termes placés avant et après l’ancre ;
– Les liens transmettent du PageRank, mais uniquement les plus puissants : les liens en dessous d’un certain niveau de PageRank sont faibles ou ignorés ;
– Les liens des domaines expirés sont détectés, de même que plusieurs autres typologies de SPAM ;
– Certains document sont protégés des filtres Penguin par la qualité de leurs premiers liens :![]()
– Etc.
Au final on comprend que peu de liens peuvent faire toute la différence, à condition qu’ils soient vraiment de qualité, au sens Googlien du terme !
Une fois les pages annotées et vectorisées, Google doit rassembler et organiser toutes ces informations pour les rendre exploitables lors des recherches. C’est là qu’interviennent les mécanismes de fusion et de récupération d’information.
4 – MERGING & INFORMATION RETRIEVAL (IR)
Docjoins et Composite Docs (CDocs)
Les docjoins s’occupent de rassembler toutes les informations connues pour chaque document. Ces informations proviennent aussi bien des étapes d’indexation (Index signals), que des mécanismes de parsing, pipelines d’annotation et de labellisation, systèmes d’extraction, d’embedding ou de scoring.
DocJoins inclus de nombreuses données issues d’Alexandria mais pas seulement :
- Document identifiers
- Clustering information
- Language and region data
- Link data (inbound and outbound)
- Signaux de scoring
- Roboting informations (noindex, nofollow, …)
- Date d’expiration du contenu
- Informations sur l’URL
Les Docjoiners sont ainsi chargés de consolider l’ensemble de la donnée que Google a identifié pour chaque document. Au global, nous avons plus de 500 types de data possibles. Ces informations sont majoritairement des signaux (compilé dans Index Signal) ou des annotations. Elles gravitent autour des concepts principaux de Quality, Indexing, Repositories et Knowledge. Cela va des infos les plus insignifiantes comme la qualité du fil d’Arianne aux plus importantes à l’image de NavBoost. De nombreuses données sont des agrégats qui ont déjà compilé de multiples signaux pour être déterminées, à l’image de Nsr. Ce schéma complet – Model.Indexing Docjoiner Data Version – permet de prendre conscience de la masse d’informations dont Google dispose potentiellement pour chaque document. Il s’agit d’une liste très intéressante, car elle présage des données qui sont potentiellement réellement utilisées par Google, pas forcément pour le ranking, mais pour tous les mécanismes du moteur.
Les docjoins permettent ensuite de générer les CDocs : un Composite Document est donc la première représentation complète d’un document après son indexation. Il contient des informations détaillées et exhaustives sur le document web, incluant son contenu, ses métadonnées, et de multiples informations d’indexation. Cette représentation sert de base pour les traitements ultérieurs. Divers types de CDoc sont mentionnés : cdoc.doc, cdoc.doc_images, cdoc.doc_videos, cdoc.properties, cdoc.anchor_stats.
Les ingénieurs doivent bien connaître le corpus sur lequel ils travaillent pour concevoir les signaux pertinents pour les utilisateurs. C’est pour cela que les index ont longtemps été gérés en silos – Web, Images, Vidéos, News… – et qu’ils le sont encore pour certains. Avec la masse de signaux destinés à traiter un maximum de typologies de contenus, le risque est de faire de mauvaises interprétations. Par exemple on trouve des traces d’authorship dans les attributs mais plutôt dédiés aux sites de presse, articles scientifiques, ou feu Blog Search… mais contrairement à ce qu’on a pu lire ailleurs récemment, le leak ne confirme pas d’emphase particulière sur l’authorship pour les sites web classiques. Cela ne signifie pas qu’il n’est pas important de travailler vos pages auteurs puisqu’elles seront de toute façon scrutées par les quality raters pour évaluer votre authority et votre expertise…
MDU et PerDocData
Les MDUs représentent une version plus optimisée et traitée des données contenues dans les CDocs. Conçus pour une récupération et un traitement rapides au moment de la recherche, ils sont générés et populés en temps réel. Ils contiennent entre autres un sous-ensemble des informations du CDoc, sélectionné et formaté pour un processing rapide et efficace.
PerDocData de son côté est un container dynamique de meta données, un protobuf. Contrairement à CDoc, qui comprend à la fois le contenu et les signaux, et joue un rôle statique dans l’ensemble du pipeline d’indexation et de classement, PerDocData est temporaire, principalement axé sur les signaux et scores. Ces fichiers sont générés et utilisés à la volée lors de la requête, décodés dans Mustang avant d’être supprimés. On rencontre là aussi différents types de modèles web, images, vidéos…
Parmi les informations embarquées par PerDocData on trouve entre autres :
- Scores de spam et de qualité
- Informations sur la langue et la région
- Signaux de fraîcheur et d’âge du contenu
- Informations sur les entités et les sujets
- Données spécifiques pour les vidéos, les images, les applications mobiles, …
- Signaux pour divers classements et algorithmes de Google
Union / Muppet
Le dispositif regroupé sous l’appellation Union / Muppet fait la jointure entre les données agrégée au niveau de l’indexation et la phase de serving déclenchée à chaque requête de l’utilisateur. Cette brique du moteur semble particulièrement importante. Nous la retrouvons dans plusieurs représentations macro de l’infrastructure logicielle du moteur, notamment dans ce schéma issu de la présentation « Ranking for Research » de Novembre 2018, révélée fin 2023 lors du procès antitrust Google vs US :
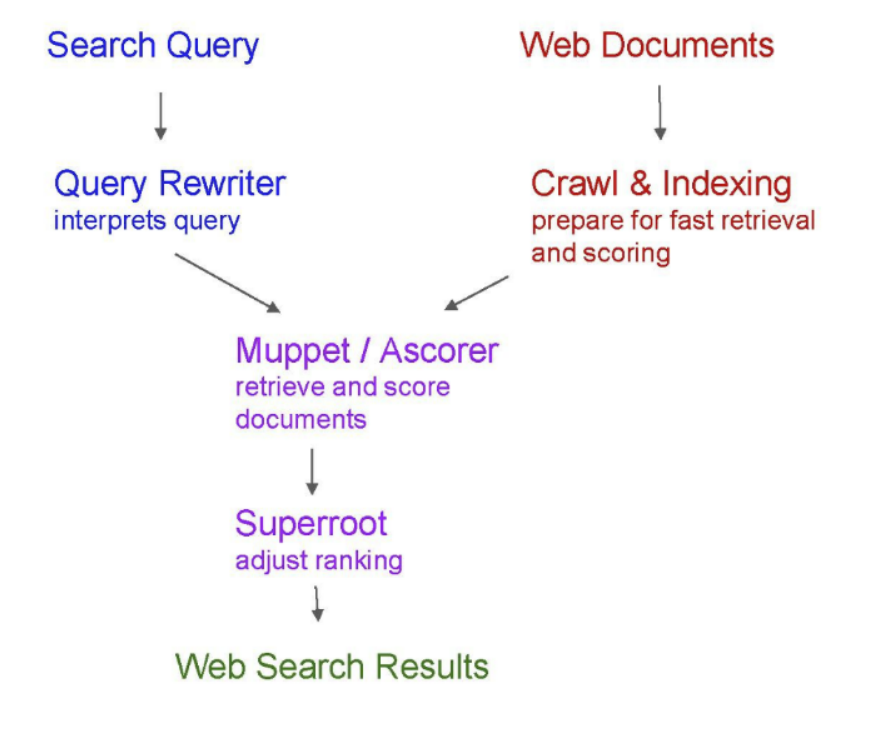
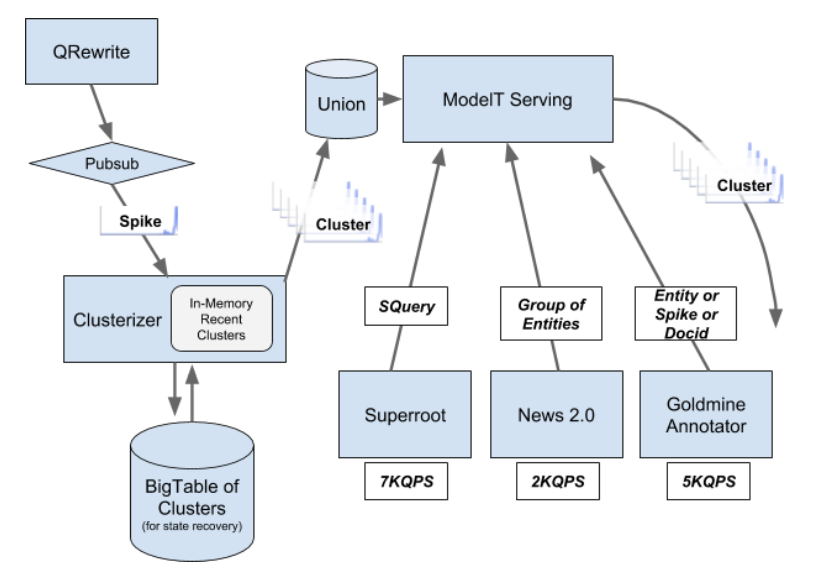
Union / Muppet apparait aussi dans ce design doc du twiddler Real Time Boost (où ModelT est une instance de Muppet) :
Encore une preuve, s’il en fallait une, que le bloc Union / Muppet est un composant clés du moteur : cette offre d’emploi – restée en ligne très peu de temps – dans laquelle Google leak tout seul le nom de ses propres systèmes internes…
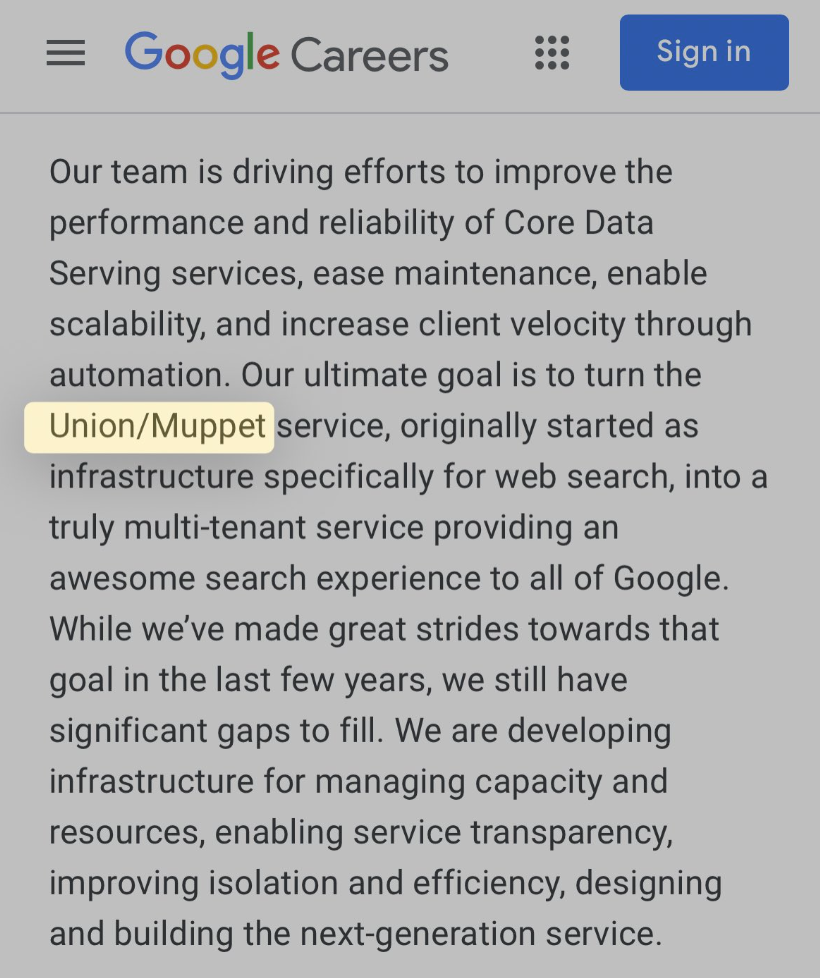
Nous n’avons que très peu d’informations disponibles sur ce dispositif, mais voici ce que nous avons pu découvrir :
- Il est géré par l’équipe CDS (Core Data Service)
- Présenté comme “une plateforme de données flexible, efficace et facile à utiliser qui protège les ensembles de données à l’échelle de Google et permet d’en extraire des informations de manière proactive”
- Développé à la base pour le Search mais Google souhaite le déployer à plus large échelle pour l’ensemble des services de l’entreprise
- Permet notamment de préparer les données d’indexation pour la phase de serving
- Comporte plusieurs instances telles que WebMain ou ModelT
- S’appuie sur Serving Document Identifier (SDI) comme clé de génération pour le serving
- Génère les snippet à afficher dans les résultats, sauf si SuperRoot le surcharge en cas de déclenchement de SnippetBrain via RankLab
Pour résumer, la brique Union / Muppet semble être un composant central qui assure la transition entre les données indexées et leur utilisation rapide lors des requêtes des utilisateurs. Il se pourrait bien qu’il joue un rôle dans la fonction de merging présentée dans ce papier : https://arxiv.org/pdf/2010.01195 Il s’agit d’une approche hybride combinant des modèles lexicaux et sémantiques basés sur des deep neural networks. L’idée principale est d’exécuter en parallèle une récupération lexicale et une récupération sémantique, puis de fusionner les deux listes de résultats pour former la liste initiale à réordonner. Il agirait ainsi au niveau du pré-ranking, c’est-à-dire de l’IR pure, juste avant le ranking opéré dans Mustang. Il reste toutefois de nombreuses zones d’ombres autour de ce composant. Si quelqu’un a des infos d’insider merci de nous contacter ^^.
Avec toutes ces données consolidées, le moteur peut maintenant évaluer et classer les pages selon leur pertinence et leur qualité. C’est l’étape cruciale du scoring et du ranking.
5 – SCORING & QUALITY / RANKING
Mustang
Pour résumer les étapes précédentes, on peut dire qu’i y a d’un côté des index générés off line (juste après le crawl), comme dans TeraGoogle ou Alexandria, stockés à l’ancienne en base de données, et de l’autre des index on line, générés à la volée au moment de la requête, “en NoSQL” comme diraient les jeunes, grâce aux protocoles buffers. C’est le cas des index Mustang ou Muppet. C’est une des particularités chez Google : une grande partie de ce qu’une entreprise normale stockerait dans une base de données traditionnelle est ici une collection de protocoles buffers sérialisés écrits dans un fichier. Mais revenons à Mustang…
S’il est surtout dédié au ranking, Mustang gère également quelques repositories comme Sentiment Snippet Annotations ou freshdocs. Cet environnement est impliqué dans le traitement des requêtes en temps réel et la génération des résultats de recherche. Il interagit avec d’autres composants du système, notamment TeraGoogle : pour illustration la structure Compressed Quality Signals sert à la fois à Mustang et TeraGoogle.
Mustang fait appel à un système d’attachements pour stocker des informations supplémentaires sur les documents, permettant d’ajouter facilement de nouvelles fonctionnalités sans modifier les structures de base. Parmi eux on trouve un “Instant Mustang” qui accueille le pipeline Freshdocs, QBST dont on a déjà parlé, RankLab ou UDR (ex WebRef), mais on y reviendra plus tard. Concernant ses fonctions de ranking, c’est là que l’on retrouve les infos issues des grands algo de machine learning : RankBrain, Deeprank, RankEmbed.

Mustang intègre également Ascorer, le dispositif qui agrège les centaines de signaux permettant de classer les résultats. On ne sait pas si Ascorer a été complètement remplacé par RankBrain et DeepRank, ou si ces derniers viennent en addition voire sont entrainés avec les mêmes signaux. Dans le CV très intéressant de Paul Haahr, on en apprend plus sur les débuts de Ascorer :

Ascorer fait donc partie des modules les plus anciens du moteur, datant de la même époque que Mustang, Superroot ou TeraGoogle. Il constitue le cœur du système de classement. Certains documents du leak nous apprennent qu’il :
- Reçoit des données de systèmes comme NSR
- Interagit avec Superroot, probablement pour fournir les scores finaux des résultats
- intervient dans des expérimentations pour tester de nouveaux composants de scoring, tel que mentionné dans Q*
- Est capable de gérer différents types de signaux et d’ajustements, entre autres les pénalités pour les mauvais backlinks

RankLab
RankLab est une plateforme de machine learning chargée de tester les différents produits Google pour les améliorer en continu. Les leaks révèlent qu’il s’agit dans le cadre du search d’un module important de Mustang, mais plus proche de Superroot, chargé de tester et optimiser en continu la pertinence des TITLE / Snippet, en exploitant une masse de données pour entraîner ses modèles.
RankLab reçoit les titres et snippets candidats, puis exploite différents signaux pour ne sélectionner que les meilleurs. Il utilise les métriques originalQueryTermCoverages, snippetQueryTermCoverage, ou titleQueryTermCoverage pour évaluer à quel point un snippet ou un titre couvre les termes de la requête initiale. Rappelons que les snippets sont “query dépendants” : à chaque {docid, query} donné les “Doc Servers” renvoient un {title, snippet} spécifique.
Le champ displaySnippet contient les features (avis, prix, thumbnail…) du snippet final proposé par Muppet. Mais il peut être surchargé par Superroot, qui sert les résultats finaux, si SnippetBrain – un composant ML de RankLab – est déclenché.

Pour résumer Mustang constitue le coeur du processus de ranking de Google, dans lequel le machine learning prend progressivement de plus en plus de place.
Le classement initial enfin établi, il reste à ajuster et servir les résultats aux utilisateurs et à exploiter leurs interactions pour améliorer le système. C’est le rôle des composants de serving et d’apprentissage.
6 – SERVING & TRAINING DATA
GWS : Google Web Server
C’est le nom du serveur front de Google retourné lorsqu’on fait un curl sur www.google.com. Ce n’est pas un mystère, GWS a même sa page Wikipedia !
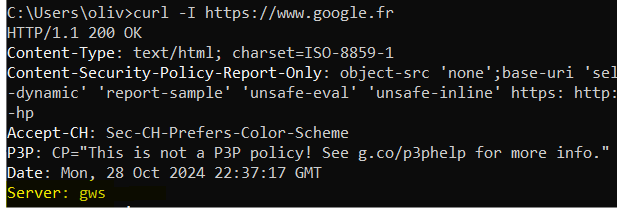
Il contient deux grands ensembles :
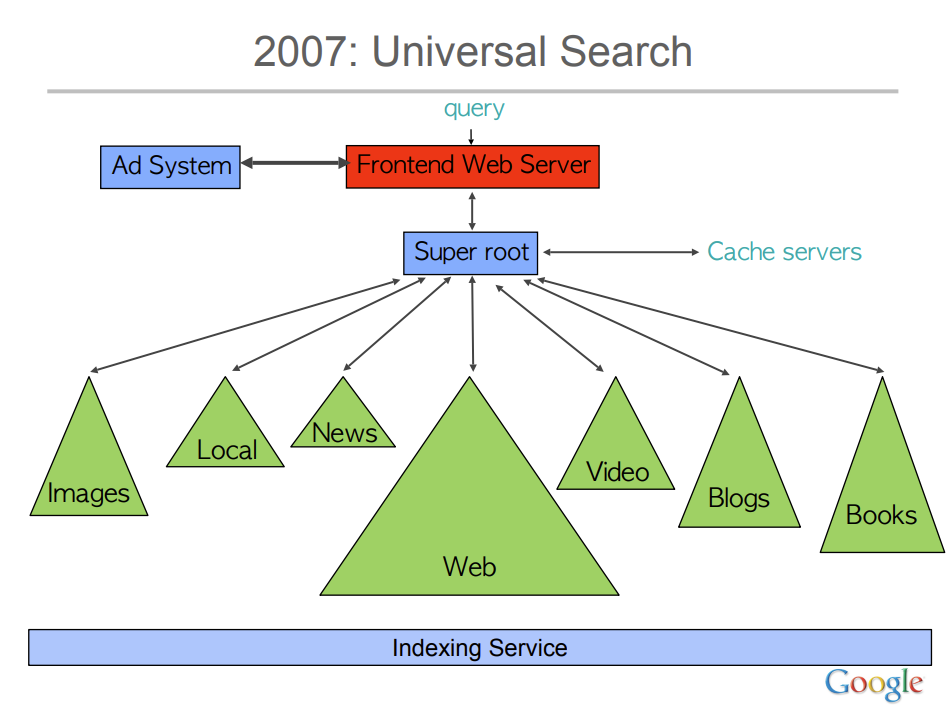
1 – Superroot
Superroot fait également partie des composants les plus anciens du moteur. On en trouve des traces dans des présentations datant de la fin des années 2010. Il est chargé de récupérer la requête de l’internaute, l’envoyer aux différents systèmes interconnectés de Google puis de retourner au front la page de résultats. C’est donc également un élément clé du moteur. L’ingénieur star de Google, Jeff Dean, l’évoque dès 2009 dans sa présentation du fonctionnement de Google : Challenges in Building Large-Scale Information Retrieval Systems (PDF, slide 64)
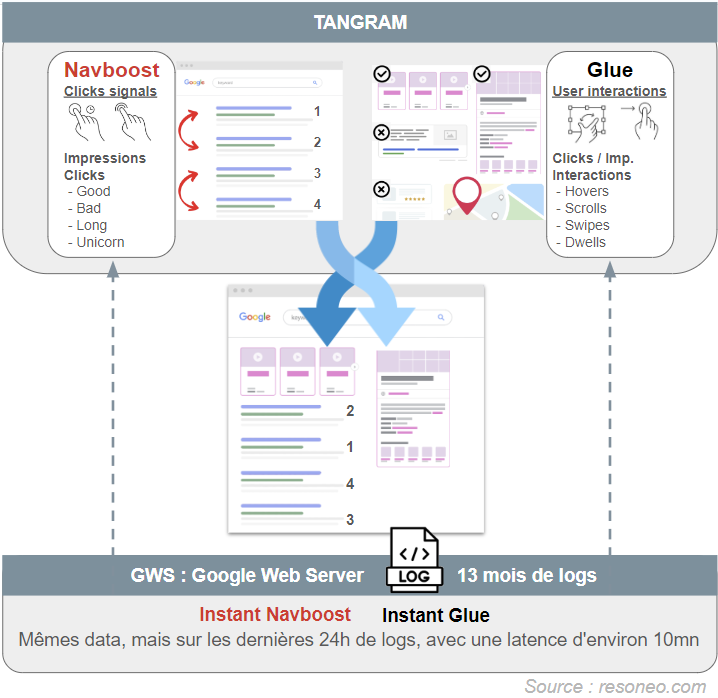
SuperRoot héberge notamment Tangram, anciennement appelé Tetris, ou Universal Packer, chargé de définir les features les plus pertinentes pour la requête, en se basant notamment sur les « click data » (Navboost et Glue) dont on a déjà parlé dans l’article précédent :
Il héberge également le framework des Twiddlers, dont on a également déjà parlé, et dont le rôle est d’ajuster les classements de la liste finale des résultats. On compte aujourd’hui vraisemblablement plus d’une centaine de twiddlers différents ayant chacun leur rôle.
2 – GFE : Google Front End
GFE est l’environnement le plus directement au contact de l’utilisateur. C’est lui qui héberge la page d’accueil de Google, et à qui l’utilisateur soumet sa requête. C’est donc à ce niveau également que se situe la correction orthographique, les suggests, et tous les mécanismes de personnalisation des résultats liés à l’historique de recherche par exemple (récoltés par GAIA).
On y trouve les modules importants de compréhension et d’expansion de requête QRewrite, QRef, QSession
Focus sur les dispositifs de Query understanding & expansion, et détection de l’intention de recherche :
Les requêtes utilisateurs sont par nature très complexes à comprendre pour un moteur de recherche. Elles sont constituées de textes très courts, ce qui nécessite de mettre en œuvre de multiples mécanismes afin de les interpréter au mieux.
C’est pourquoi on trouve dans le leak autant de dispositifs mis en place chacun pour une tâche spécifique. Tous ne sont sans doute pas ou plus utilisés à l’heure actuelle, mais cela démontre bien l’importance et la complexité de cette phase dans le cycle de recherche.
Nous vous recommandons cette vidéo de Paul Haahr qui en trois exemples démontre que chaque mécanisme de désambiguïsation ou d’analyse sémantique ou contextuelle, apporte son lot d’avantages et d’inconvénient, et qu’il sera choisi de le déployer en prod si la somme des avantages est supérieure à celle des inconvénients… L’exemple de la prise en compte des smileys qui représentaient 1 million de recherches par jour au milieu des années 2000 est à ce titre très révélateur : il aura fallu une équipe de plusieurs ingénieurs durant toute une année et une réindexation complète de toutes les pages web pour que le moteur tienne enfin compte des smileys dans les requêtes 🤓
Nous n’allons pas parcourir l’intégralité de ces mécanismes identifiés dans le leak, mais quelques-uns qui nous semblent représentatifs
la team MRF (Meaning Remodeling Framework) semble être particulièrement impliquée dans la gestion de cette étape cruciale. Elle gère notamment un certain nombre de catalogues d’intentions permettant de mieux qualifier les requêtes.
QRewrite
Le module QRewrite appelé par Superroot lorsqu’un utilisateur fait une requête porte bien son nom. Son rôle sera de réécrire cette requête de manière plus exploitable pour le moteur. Il va faire appel à deux types de processus :
- NLP : tokenisation, étiquetage grammatical – chaque token est marqué avec son rôle grammatical (nom, verbe, adjectif, etc.), analyses syntaxique – la structure grammaticale de la phrase est analysée pour comprendre les relations entre les mots.
- Sémantique : reconnaissance d’entités, détection de l’intention et prise en compte du contexte
Grâce à cela, il va être en mesure d’effectuer diverses opérations :
- Normalisation : correction des fautes d’orthographe, expansion des abréviations et standardisation des termes
- Désambiguïsation : résolution des ambiguïtés en choisissant le sens le plus probable en fonction du contexte.
- Gestion des synonymes : remplacement ou ajout des mots par leurs synonymes pour correspondre aux termes répertoriés dans le Knowledge Graph

QRewrite va activer selon les cas d’autres composants d’analyse de requêtes :
- QRef : Query Reference, identifie et résoud les entités mentionnées dans la requête et les connecte avec le noeud du graph correspondant. Il peut aussi normaliser certains termes en transformant par exemple « NYC » en « New York City » ou “Obama” en “Barack Obama”.
- QSession gère les sessions utilisateur, permettant à Google de suivre les requêtes successives pour comprendre le contexte global de la recherche.
- QBST et Term Weighting dont on a déjà parlé dans un article précédent, et qui eux font appel à des modèles de machine learning pour interpréter les requêtes
- STBR (Support Transfer Rules) : fonctionne avec un système de sources et targets attachées aux entités. Les sources sont les entités initiales mentionnées dans une requête et les targets celles vers lesquelles le support est transféré pour mieux refléter l’intention de l’utilisateur. Ainsi dans la requête « France Espagne », les sources sont les pays France et Espagne, mais les targets sont les équipes nationales de ces deux pays. Quant au sport concerné il sera déterminé selon les pics de recherche liés à l’actualité, via encore un autre système… Cette route API est très explicite et intéressante à lire, même si on sent bien que l’auteur a des difficultés de compréhension avec la langue Française…
QRewrite travaille avec différents composants pour identifier l’intention utilisateur :
IQL, WebRef (UDR) et Pianno pour détecter l’intention de recherche
WebRef (ou UDR, son remplaçant) : c’est le pendant de QRef mais côté contenus plutôt que requête. Il analyse les documents pour identifier et annoter les entités mentionnées (personnes, lieux, objets, concepts, etc.). Un score de topicalité (topicalityE2) indique la pertinence de chaque entité par rapport au document. WebRef fournit des informations sur les entités à QRef, qui s’en sert pour ajuster les requêtes, et à QRewrite pour réécrire les requêtes si nécessaire. Pour cela, Webref fait appel à deux sous ensembles : Pianno et IQL
Pianno : il s’appuye sur les entités stockées par WebRef pour générer les intentions potentielles de l’utilisateur. Pianno interprète le contexte et cherche à comprendre ce que l’utilisateur souhaite réellement obtenir comme information ou action. Les scores de confiance des intentions, calculés par Pianno, sont stockés dans piannoConfidenceScoreE2. Il semble que Pianno soit surtout utilisé pour annoter et gérer les « intents » sans arguments spécifiques, appelés unbound intents. Il s’agit donc d’un pipeline d’annotation dédié aux requêtes complexes ou ambiguës.
Sans rentrer dans le détail sachez que le leak mentionne également un pipeline de détection d’intentions focalisé sur les images : Orbit
IQL (Intent Query Language) : IQL est un langage destiné à représenter des intentions complexes dans le système. Il est souvent employé pour traiter des expressions d’intentions liées aux entités WebRef et aux requêtes utilisateurs, permettant de formaliser et d’indexer ces intentions pour une meilleure interprétation et résolution des requêtes. Il sert à encoder ces intentions de manière structurée. Les intentions détectées sont converties en expressions IQL, ce qui permet au moteur de traiter et d’interpréter efficacement l’intention de l’utilisateur. unboundIntentMid et unboundIntentScoreE2 stockent les MIDs des “intentions non liées” et leurs scores de confiance respectifs. Ces intentions représentent des actions potentielles sans arguments spécifiques (par exemple, « Acheter », « Réserver »).
Exemple : un utilisateur recherche « comment cuisiner un risotto ».
- Détection des entités :
- WebRef identifie les entités « cuisiner » et « risotto ».
- Ces entités sont encodées et leurs scores de topicalité et de confiance sont calculés.
- Génération de l’intention :
- Pianno génère une intention non liée telle que Intent:CuisineRecette.
- L’intention est associée à un score de confiance élevé.
- Encodage en IQL :
- L’intention est convertie en une expression IQL et encodée dans iqlFuncalls.
- Les métadonnées associées sont mises à jour dans les modules.
- Résultat pour l’utilisateur :
- Mustang peut utiliser ces informations pour proposer à l’utilisateur des recettes de risotto, des vidéos tutoriels ou des listes d’ingrédients.
En résumé, UDR (anciennement WebRef) sert à extraire les éléments clés d’un contenu, Pianno interprète ces éléments pour comprendre l’intention sous-jacente de l’utilisateur, et IQL formalise cette intention pour permettre aux systèmes d’y répondre de manière pertinente et efficace.
Vers toujours plus d’IA
En analysant les leaks on se rend compte que Google remplace progressivement ses systèmes par du machine learning. QBST et Termweight pour l’interprétation des requêtes, UDM pour l’analyse des documents, SnippetRank (et plus largement RankLab) pour l’optimisation permanente des pages de résultats, etc.. D’ailleurs, on apprend en octobre 2024 que Google utilise désormais l’IA pour packager ses pages de resultats, avec un premier test sur les recettes de cuisine.
Pour conclure…
Félicitations si vous avez lu cet article jusqu’au bout ! Il est un peu long mais il fallait cela pour décrypter le fonctionnement interne de Google Search, car comme le disait notre regretté Bill Slawski, on ne peut pas faire du SEO si on ne comprend pas le fonctionnement des moteurs ^^
Retrouvez les autres parties de notre série d’articles sur le Google leak de 2024 :
Part 1 – Les expérimentations au cœur de l’évolution du moteur de recherche
Part 2 – Le framework twiddler
Part 3 – Dans les coulisses du classement Google : Information Retrieval
Part 4 – Du machine learning à tous les étages
Part 5 – Clic-tature : quand l’Empire Google vous observe
Part 6 – Plongée dans les entrailles de Google Search, infrastructure et environnements Internes


{kind=link}