
People are talking a lot about “query fan‑out” for conversational search engines these days. But did you know the same query‑expansion principle is applied to traditional search engines as well? We found a way to access Google’s own system, revealing for the first time how the engine rewrites your queries and assigns scores to each URL.
The Query Expansion System Revealed
Concrete Examples of Query Expansion
Let’s take the query « tallest building in the world » :
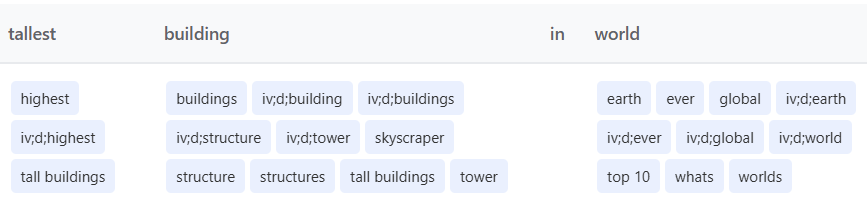
- The system detects the frequent bi-gram « tall buildings »
- Generated expansions : « skyscraper », « tower », « highest », « top 10 »,…
For « elevenlabs text to speech » :

- « text to speech » is consolidated with « tts »
- Stop words are always ignored (to, the, a..)
« nail salon fort lauderdale 17th street »

- Geographic markers:
geo:ypcat:manicuring,geo:ypcat:nailsalon - Zone codes:
geo;88d850000000000,geo;88d8f0000000000 - Expansion of “17th” → “ave,” “avenue,” “road,” “st,” “streets”
- Terms tagged iv;p match the query exactly; all others are broadened.
« skydiving in miami beach«

- note that Miami is expanded with ‘south fl’
« how to build a sandcastle » :

- Google treats “diy” as a significant semantic expansion.
- The system grasps the intent behind the query.
« best mexican restaurant in la«
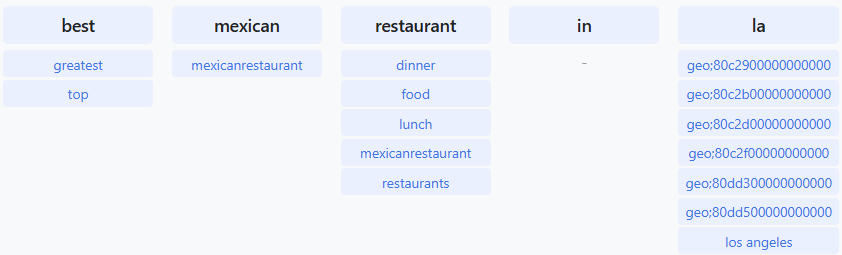
- Singular/plural inflections
- Interpretation of the acronym “la”
- “mexicanrestaurant” detected as a frequent bigram
« buy electric screwdriver »

- iv;p matches the exact query term, whereas iv;d can also match a derived form.
- The wide range of variations helps pinpoint what Google will look for in page content for that query.
Exclusive iv;p and iv;d markers
According to our research, “iv” stands for “in verbatim,” indicating a match to the exact query as typed. The analysis shows a rigorous system:
- iv;p – strict exact match (100 % of the terms are identical to the search word)
- iv;d – linguistic derivations allowed (roughly 52 % identical, 48 % variations)
- Unmarked terms – ALWAYS semantic or orthographic expansions (0 % identical to the query)
Google applies a mutually exclusive logic to iv;p and iv;d within the same query: it’s one or the other, never both at once. This exclusivity suggests that Google first assesses the nature of your query to decide its interpretation strategy.prétation.
Geographic and contextual markers
The system employs several kinds of specialized markers:
- geo:ypcat: Yellow Pages–style category codes (e.g., manicuring, nailsalon, museum, restaurant)
- geo;88d… – precise geographic zone encodings
- ss:here – a rare flag set for “around me” / “near me”
These markers enable Google to pinpoint geographic intent and tailor the results accordingly.
Keep in mind that the user’s actual location also plays a key role.
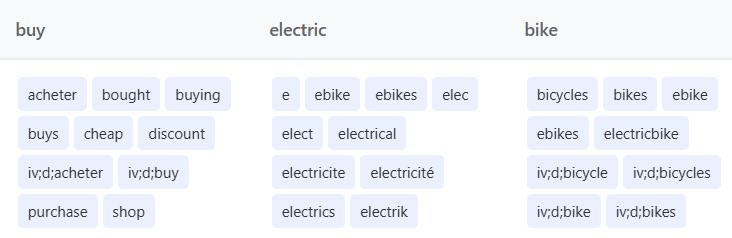
In this query, issued from a French IP address, Google translated “buy” into French (« acheter ») to broaden the search to local results that hadn’t been translated.
A Term‑Level Scoring System Revealed
Each word in the query is assigned a score for every ranked URL:
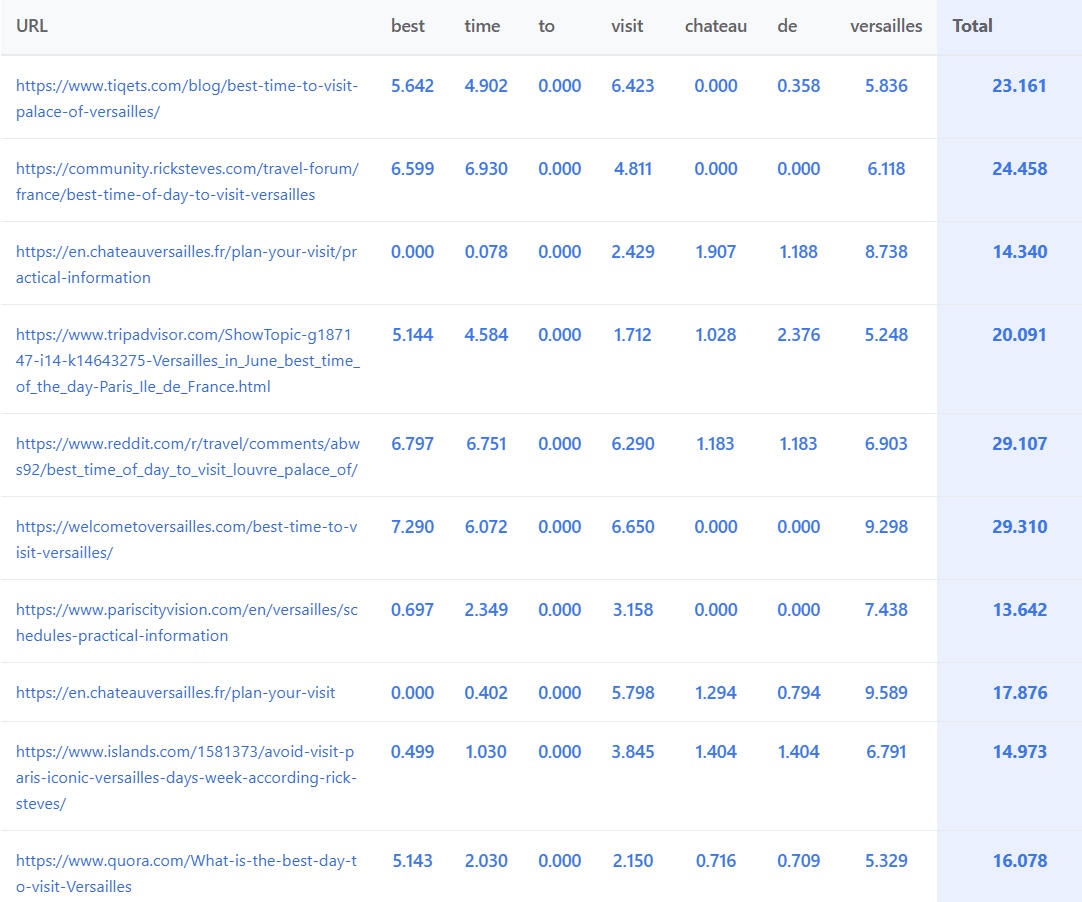
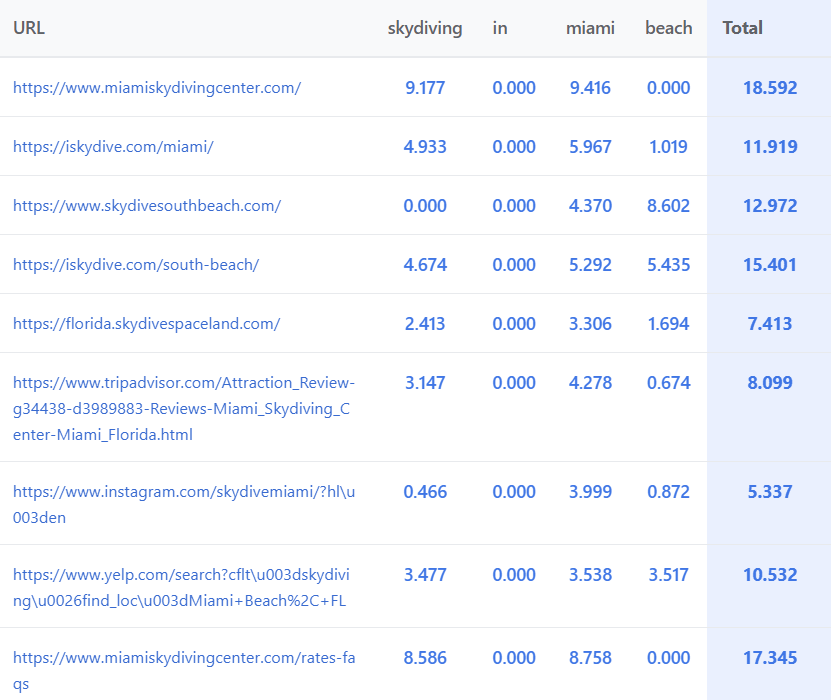
The scoring scale
Observed scores range from 0 to about 10 points per term/URL, following some very clear patterns:
- Stop words : always 0
- Terms in the title: major bonus (~3.5 points on average)
- Named entities: highest scores
- Videos, images, news results: always 0 – the score applies only to organic results
- Numbers: also always 0
The pairwise nature of the scoring
The same word can receive different scores for the same URL across two distinct queries. This confirms that the score is pairwise (query/document), with the query’s context directly influencing the weighting.
For instance, the term “seo” will have a different score for the same URL in these 3 queries:


Note that ‘define’ doesn’t appear in the page so has 0 points

Putting It in Perspective with Google’s Known Mechanisms
The Confirmed Processing Pipeline
The infographic from the latest antitrust trial (Source: U.S. Department of Justice) outlines the following architecture:
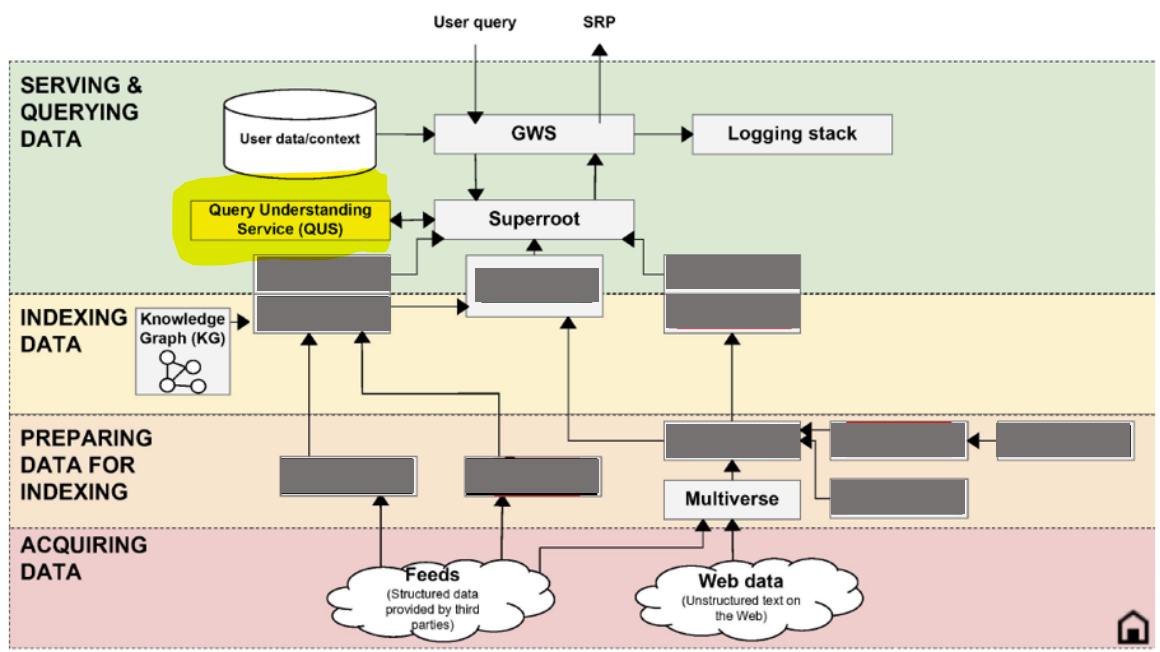
The query‑expansion system we uncovered is closely related to QUS (Query Understanding Service), while the score acts as a marker of how well query terms match their presence in the page TITLE or body. Cross‑referencing the 2024 leaks, the following high‑level pipeline still appears to hold:
GWS → Superroot → Query Understanding Service (QUS) → QBST → Scorers → Rerankers
Live experiments discovered in Google Search confirm QUS and QRewrite are actively in use:
- GwsLensMultimodalUnderstandingInQusUpstreamLaunch
- QuSignalsApiGwsLaunch
- QusPreFollowM1InQResSLaunch
- HpsQusToQrewriteMigrationCoordinatedLaunch
“Salient Terms” in the API documentation
The QualitySalientTermsSalientTerm documentation from the 2024 Google Leaks sheds light on the scoring mechanism:
- virtualTf – adjusted term frequency accumulated from title, body, anchors, and clicks
- idf – inverse document frequency (term scarcity)
- salience – 0‑to‑1 importance score as a descriptor
QBST (Query‑Based Salient Terms) computes query‑document proximity using these combined signals.
Note that every document contains a long list of salient terms; we only see scores for those that match the query.
TUIG and Semantic Orchestration
Other exclusive labels we have identified underscore the importance of this Query Understanding Service:
QUERY_INTENT_DATATYPEQUERY_UNDERSTANDING_QUS_INPUT_OUTPUT_DATATYPEQUERY_UNDERSTANDING_RAW_INTERNALS_DATATYPEQUERY_UNDERSTANDING_TUIG_IO_DATATYPE
TUIG is the semantic‑annotation system that enriches queries with contextual signals, orchestrating annotations across the different components. It is what coordinates QUS, QRewrite, and the other understanding systems.
We also see that the intent‑detection layer sits very close by. It works across verticals detected within queries, and context (search history, language, location, and more) is critical for ultimately producing the overall “topicality.”
- TRAVEL_LOCATION_INTENT_STICKY_DATES_DATATYPE
- USER_INTENT_DATATYPE
- HOTEL_INTENT_PROFILE_DATATYPE
- GOOGLE_PAY_MERCHANT_OFFER_INTENTS_DATATYPE
- ASSISTANT_INTENT_HISTORY_DATATYPE
- CONTENTADS_USER_INTENT_PROFILE_DATATYPE
- CONTENTADS_USER_INTENT_VERTICALS_DATATYPE
- SEARCH_SHOPPING_PRODUCT_INTENT_UNIT_DATATYPE
- SHOPPING_INTENT_DETECTION_CONVERTER
- TRANSLATION_INTENT
This will likely warrant a dedicated article.
TL;DR
What we learned
About query expansion:
- Automatic detection of spelling variants and synonyms
- Exclusive markers iv;p (exact match) and iv;d (derivations)
- Geographic markers (
geo:ypcatfor category codes, zone codes) - Identification of frequent bi‑ and trigrams (“nail salon” → “nailsalon”)
About scoring:
- Each word in the query receives a score per URL (0 to ≈10 points).
- The same word can get different scores for the same URL across two different queries.
- Pairwise scoring (query / document): the query’s context directly influences the weighting.
- The total score is NOT the final ranking.
- These scores are probably calculated online, which is why we could see them.
- They are likely tied to QBST signals (Query‑Based Salient Terms), but without the click data.
- Whether the term appears in the URL, TITLE, or body is crucial to its score.
To conclude
This glimpse into Google’s inner workings reveals a remarkable sophistication in how queries are processed.
Your queries pass through many components:
- QRewrite – cleans, lemmatizes, and detects the core entity and frequent bi‑/trigrams
- QUS (Query Understanding Service) – merges QRewrite’s output with context (language, history, geolocation, etc.)
- Piano & IQL – intent detection
- QBST (Query‑Based Salient Terms) – gauges query‑to‑document similarity for each candidate page (weighted by virtual TF, IDF, salience, and click data)
- Scorer & Rerankers – Mustang, Ascorer provide the initial raw scoring, then Twiddlers, NavBoost, and vertical‑specific tweaks re‑rank results based on CTR, freshness, E‑E‑A‑T, and more.
For a refresher on the main components of Google Search, see our 2024 Google leak article:
https://www.resoneo.com/google-leak-part-6-how-does-google-search-work-a-deep-dive-into-google-leaks/
In plain terms, by the time a keyword reaches the raw‑ranking stage it has already been enriched, filtered, and sometimes rewritten. Each candidate document now carries an initial, purely lexical score – before popularity signals and broader context reshuffle the deck.
Note: All information presented here comes solely from publicly accessible sources that required no access bypass or intrusion. It is published for informational purposes only.
The method described in this article remains undisclosed – but if you look hard enough, you’ll find it. Spread the word and Google will plug the hole before long, which would be unfortunate. ^^

