
HTTP/2 est un nouveau protocole qui a vu le jour en 2015. Il représente un tournant important dans la gestion des requêtes entre le serveur et le navigateur.
En septembre 2020, Google a annoncé qu’à partir de novembre de la même année, Googlebot commencerait à crawler des sites en HTTP/2.
Selon Google, “[…] ce changement rendra le crawling plus efficace en termes d’utilisation des ressources du serveur. Avec h2, Googlebot est capable d’ouvrir une seule connexion TCP au serveur et de transférer efficacement plusieurs fichiers depuis celui-ci en parallèle, au lieu de nécessiter plusieurs connexions. Moins il y a de connexions ouvertes, moins le serveur et Googlebot ont de ressources à dépenser pour le crawling.”
Qu’est-ce que le protocole HTTP ?
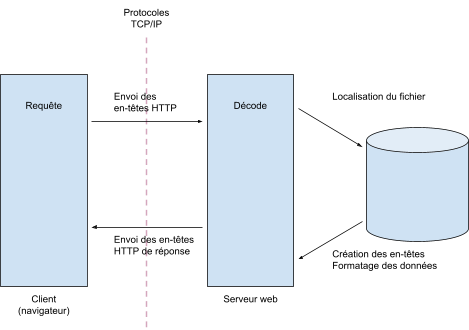
Avant d’entrer dans le détail du protocole HTTP/2, l’ancienne version HTTP ou HyperText Transfer Protocol permet de transférer des fichiers (notamment au format HTML) grâce à une URL qui n’est autre que l’adresse permettant de faire le lien entre le serveur et le navigateur (le client).
En pratique, c’est grâce à ce protocole, que le navigateur peut afficher le contenu d’une page web : d’abord il transfère l’hypertexte du site et ensuite il le transforme en contenu intelligible pour l’utilisateur : textes, images, vidéos…
Avec le HTTP/1, la communication entre le navigateur et le serveur se faisait en plusieurs étapes et pouvait rendre le téléchargement d’une page plutôt long, d’autant plus que le poids des informations contenues sur les pages a considérablement augmenté depuis la mise en place de ce protocole en 1991.
Pour comprendre ce qui change avec le protocole HTTP/2, il faut avoir en tête que les protocoles contiennent trois grandes parties :
- L’en-tête (qui donne entre autres des informations sur les adresses source et de destination ainsi que la taille et le type de la charge utile)
- La charge utile (l’information réelle transmise grâce au protocole)
- Le pied de page (qui contrôle l’acheminement des demandes client-serveur et qu’il n’y a pas d’erreur).
Plus d’informations sur le protocole HTTP sur Comment ça marche.
La différence entre protocole HTTP et protocole HTTP/2
L’ancien protocole HTTP étant largement utilisé depuis les années 1990 (début de la démocratisation d’Internet), nos usages et besoins grandissant, un nouveau protocole a été mis au point afin de traiter un plus grand nombre de données simultanément : le protocole HTTP/2. A noter que d’autres versions intermédiaires ont vu le jour entre la première version HTTP/1 et HTTP/2 en 2015.
En effet, la technologie et les usages ont largement évolués ces 20 dernières années :
- Les images et vidéos sont devenues bien plus lourdes,
- L’usage du JavaScript a explosé,
- L’implémentation de feuilles de style (CSS) et les en-têtes HTTP (dont nous avons parlé plus haut) sont devenues de plus en plus importantes.
Pour en savoir plus à ce sujet, nous vous conseillons un excellent article de Kinsta.
Le besoin est donc de réduire considérablement le temps de traitement des requêtes du navigateur. Ainsi les avantages du nouveau protocole HTTP/2 sont multiples car :
- Le multiplexage (capacité à faire plusieurs requêtes en même temps sans qu’elles ne se bloquent) a permis un transfert de données bien plus rapide quand le HTTP/1 n’autorisait qu’une requête à la fois.
- Il n’y a plus qu’une seule connexion TCP (protocole de contrôle de transmissions) pour gérer la transmission de plusieurs flux de données.
- Le HTTP/2 compresse les en-têtes pour gagner en vitesse de chargement des pages.
- L’utilisation du “server push” réduit encore les temps de latence en envoyant en amont de l’analyse par le navigateur les ressources référencées d’une même page.
Grâce à toutes ces améliorations, la web performance d’un site s’en trouve donc naturellement améliorée. De plus, cela permet de réduire les coûts d’exploitation et d’investissement des ressources réseau.
Les avantages du crawl de Google en HTTP/2 sur les sites qui le permettent
En principe, le crawl en HTTP/2 par Google devrait le rendre “plus efficace en termes d’utilisation des ressources du serveur » grâce à l’ouverture d’une seule connexion TCP au serveur. En plus d’obtenir de meilleures performances pour le crawl, cela devrait également permettre à terme de réduire les coûts en énergie que l’on sait particulièrement massive pour le moteur de recherche.
Google précise aussi que pour ceux qui le souhaitent, il est possible de refuser un crawl en HTTP/2. Il suffit de demander au serveur de répondre avec un “code d’état HTTP 421” quand Googlebot passe en h2.
Sur le papier, on comprend que ce process devrait vite se généraliser et permettre plus de rapidité au crawl et plus de découvertes de pages, et donc d’indexation. Pour l’instant, pas d’impact SEO en vue, l’objectif prioritaire pour Google étant plutôt de réduire les coûts de ressources.
Conclusion
Mais alors que nous venons à peine de vous parler du protocole HTTP/2 – qui par ailleurs n’est pas encore utilisé partout, et que Google vient seulement de se mettre à la page – le protocole HTTP/3 est déjà en route !
Compte-tenu de l’évolution très rapide de ces protocoles, n’hésitez pas à nous contacter pour vous accompagner dans la mise en place de vos stratégies SEO ou pour vous former aux dernières techniques de référencement.

