
On parle beaucoup de query fan out actuellement pour les moteurs de recherche conversationnels. Mais saviez-vous que le même principe d’expansion de requête est appliqué aux moteurs classiques ? Nous avons découvert un moyen d’accéder à celui de Google, révélant pour la première fois comment le moteur réécrit vos requêtes et attribue des scores à chaque URL.
Le système de query expansion dévoilé
Exemples concrets de query expansion
Prenons la requête « coffre de toit » :
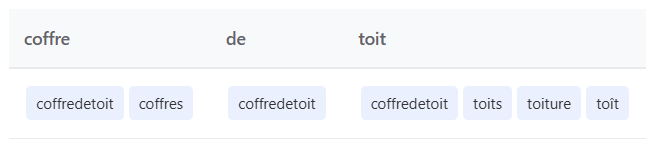
- Le système détecte le trigramme « coffredetoit »
- Expansions générées : « coffres », « toits », « toiture », « toit »
Pour « comment faire un gâteau aux pommes » :

- « commentfaire » est consolidé et étendu avec « recette de », « tuto »
- « gâteau » → « cake », « dessert », « gateau », « gateaux »
- les stop words sont systematiquement ignorés (un, aux..)
L’exemple « restaurant japonais paris » révèle la gestion géographique et un système de catégorisation très fin :
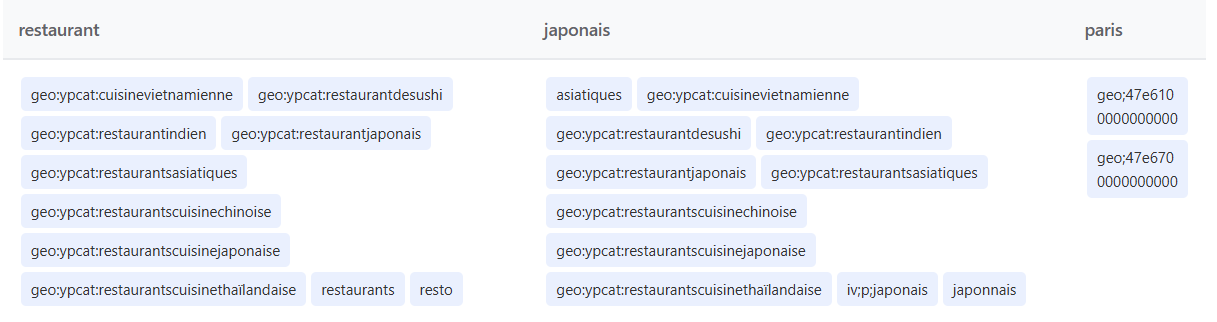
« nail salon fort lauderdale 17th street »

- Marqueurs géographiques : geo:ypcat:manicuring, geo:ypcat:nailsalon
- Codes de zones : geo;88d850000000000, geo;88d8f0000000000
- Expansion « 17th » → « ave », « avenue », « road », « st », « streets »
- Les termes marqués iv;p correspondent exactement à la requête, les autres sont élargis
« stage pilotage voiture » :
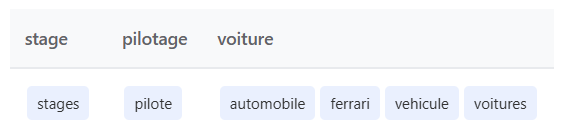
- Google considère « ferrari » comme une expansion sémantique importante
- Le système comprend l’intention derrière la requête
« activite enfant idf«

- Déclinaisons singulier/pluriel
- Interprétation de l’accronyme idf
- activiteenfant détecté comme bi-gram fréquent
« tour cyclisme en suisse »

- iv;d correspond soit au terme exact de la requête soit à un dérivé
- ‘en’ : stop word ignoré
- Les nombreuses variations permettent d’identifier ce que Google va rechercher dans le contenu pour cette requête
Les marqueurs exclusifs iv;p et iv;d
D’après nos recherches, « iv » signifie « in verbatim », indiquant la correspondance avec la requête tapée. L’analyse révèle un système rigoureux :
- iv;p : correspondance exacte stricte (100% des termes sont identiques au mot recherché)
- iv;d : dérivations linguistiques autorisées (environ 52% sont identiques, 48% sont des variations)
- Termes non marqués : TOUJOURS des expansions sémantiques ou orthographiques (0% identiques à la requête)
Google applique une logique exclusive concernant les iv;p et iv;d dans la même requête. C’est soit l’un, soit l’autre, jamais les deux simultanément. Cette exclusivité suggère que Google analyse d’abord la nature de votre requête pour choisir sa stratégie d’interprétation.
Les marqueurs géographiques et contextuels
Le système utilise plusieurs types de marqueurs spécialisés :
- geo:ypcat: : catégories type Pages Jaunes (yp = Yellow Pages) : manicuring, nailsalon, museum, restaurant…
- geo;88d… : encodages de zones géographiques précises
- ss:here : flag activé pour « autour de moi » / « near me »
Ces marqueurs permettent à Google de comprendre précisément l’intention géographique et de personnaliser les résultats en conséquence.
Notez que la localisation de l’utilisateur est également importante.

Dans cette requête réalisée depuis une IP japonaise, Google a traduit bar en japonais pour étendre la recherche à des résultats locaux non traduits.
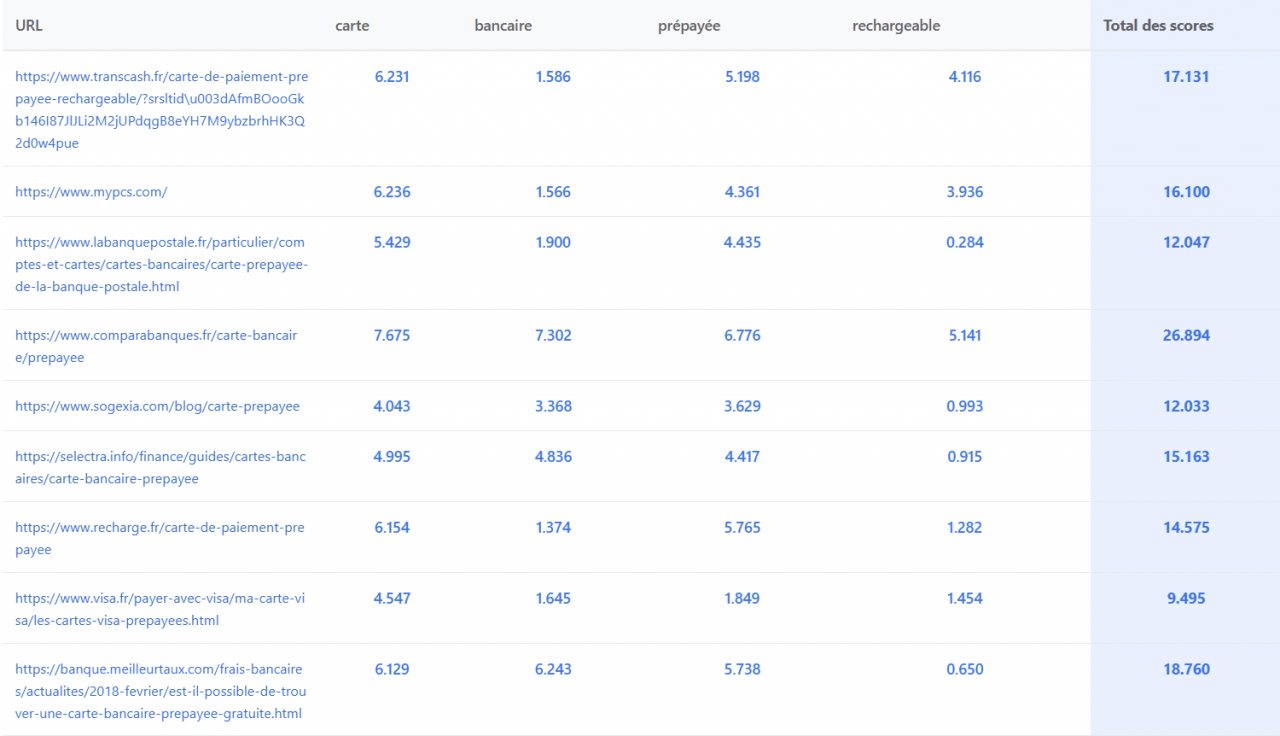
Un système de scoring par terme révélé
Un score est affecté à chaque mot de la requête pour chaque URL positionnée :
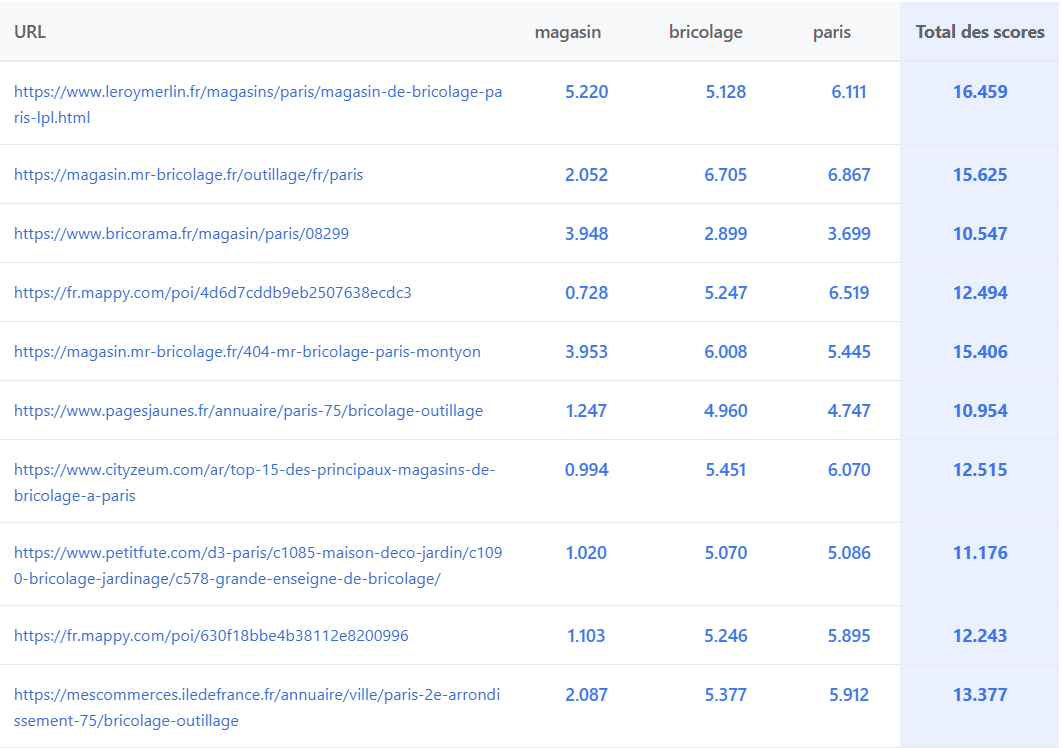
L’échelle de notation
Les scores observés varient de 0 à ~10 points par terme/URL avec des patterns très clairs :
- Stop-words (le, de, du, à…) : toujours à 0
- Termes dans le title : bonus majeur (~3.5 points en moyenne)
- Entités nommées : scores les plus élevés
- Vidéos, images, résultats news : systématiquement à 0, le score ne concerne que l’organique
- Chiffres : toujours à 0 également
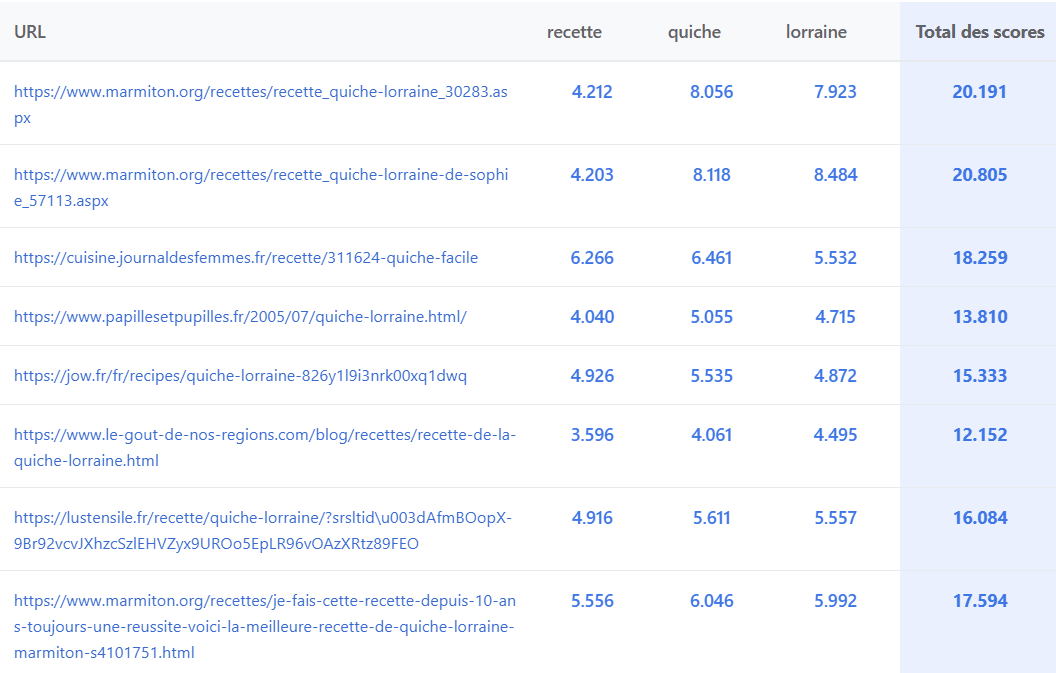
La nature pairwise du scoring
Un même mot peut avoir des scores différents pour la même URL sur deux requêtes distinctes. Cela confirme qu’il s’agit d’un score pairwise (query/doc) où le contexte de la requête influence directement la pondération.
Par exemple, le terme « bricolage » aura un score différent pour la même URL dans ces deux requêtes :


Mise en perspective avec les mécanismes Google connus
Le pipeline de traitement confirmé
L’infographie du dernier procès antitrust (Source : U.S. Department of Justice) présente l’architecture suivante :
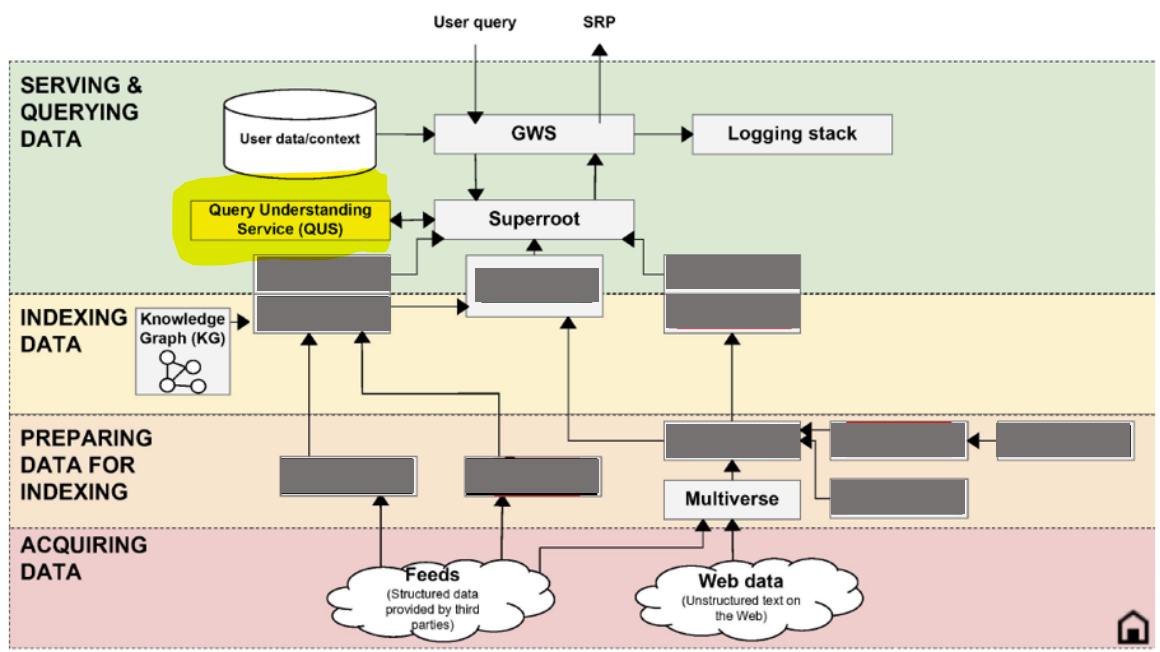
Le système d’expansion de requête que nous avons découvert est proche de QUS (Query Understanding Service), tandis que le score est un marqueur de correspondance entre les termes de la requête et leur présence dans le TITLE / Body. Mis en exergue avec les Leaks de 2024, le pipeline macro suivant semble toujours valable ^^
GWS → Superroot → Query Understanding Service (QUS) → QBST → Scorers → Rerankers
Les expérimentations live découvertes dans Google Search confirment l’utilisation active de QUS et QRewrite :
- GwsLensMultimodalUnderstandingInQusUpstreamLaunch
- QuSignalsApiGwsLaunch
- QusPreFollowM1InQResSLaunch
- HpsQusToQrewriteMigrationCoordinatedLaunch
Les « Salient Terms » dans la documentation API
La documentation QualitySalientTermsSalientTerm des Google Leaks 2024 éclaire le mécanisme de scoring :
virtualTf : fréquence corrigée accumulée depuis title, body, anchors, clics
idf : inverse document frequency (rareté du terme)
salience : importance 0-1 comme descripteurQBST (Query-Based Salient Terms) calcule la proximité requête/document en utilisant ces signaux combinés.
Notez que chaque document possède une longue liste de termes saillants, nous ne voyons ici les scores que pour ceux qui matchent avec la requête
TUIG et l’orchestration sémantique
D’autres labels exclusifs que nous avons identifiés confirment l’importance de ce service de Query Understanding
- QUERY_INTENT_DATATYPE
- QUERY_UNDERSTANDING_QUS_INPUT_OUTPUT_DATATYPE
- QUERY_UNDERSTANDING_RAW_INTERNALS_DATATYPE
- QUERY_UNDERSTANDING_TUIG_IO_DATATYPE
TUIG est le système d’annotation sémantique qui enrichit les requêtes avec des signaux contextuels, facilitant l’orchestration des annotations entre les différents composants. C’est lui qui permet la coordination entre QUS, QRewrite et les autres systèmes de compréhension.
Nous voyons également que le système de détection d’intention est très proche. Il fonctionne par verticales identifiées dans les requêtes. Le contexte est également très important (historique de la recherche, langue, localisation…) pour pouvoir générer au final la « topicality »
- TRAVEL_LOCATION_INTENT_STICKY_DATES_DATATYPE
- USER_INTENT_DATATYPE
- HOTEL_INTENT_PROFILE_DATATYPE
- GOOGLE_PAY_MERCHANT_OFFER_INTENTS_DATATYPE
- ASSISTANT_INTENT_HISTORY_DATATYPE
- CONTENTADS_USER_INTENT_PROFILE_DATATYPE
- CONTENTADS_USER_INTENT_VERTICALS_DATATYPE
- SEARCH_SHOPPING_PRODUCT_INTENT_UNIT_DATATYPE
- SHOPPING_INTENT_DETECTION_CONVERTER
- TRANSLATION_INTENT
Cela fera sans doute l’objet d’un article dédié
TL;DR
Ce que nous avons appris
Sur la query expansion :
- Variantes orthographiques et synonymes automatiquement détectés
- Marqueurs exclusifs iv;p (exact match) et iv;d (dérivations)
- Marqueurs géographiques (geo:ypcat pour les catégories, codes de zones)
- Identification des bi et trigrammes (« coffre de toit » → « coffredetoit »)
Sur le scoring :
- Chaque mot de la requête reçoit un score par URL (0 à ~10 points)
- Un même mot peut avoir des scores différents pour la même URL sur deux requêtes distinctes
- Score pairwise (query/doc) : le contexte de la requête influence la pondération
- Le score total n’est PAS représentatif du classement final
- Ces scores sont probablement calculés online (d’où leur visibilité)
- Lien probable avec les signaux QBST (Query-Based Salient Terms), la click data en moins…
- La présence du terme dans l’URL, le TITLE et le body est déterminante pour ce score
Pour conclure
Cette fenêtre sur les mécanismes internes de Google révèle une sophistication remarquable dans le traitement des requêtes.
Vos requêtes traversent de nombreux composants Google :
- QRewrite : nettoie, lemmatise, détecte l’entité-cœur, les bi-/tri-grammes…
- QUS : fusionne la sortie de QRewrite avec le contexte (langue, historique, géoloc…)
- Piano & IQL : détection de l’intention
- QBST : calibre pour chaque document la similarité « requête ↔ salient terms » (pondérée par virtual TF, IDF, salience et les click data)
- Scorer & Rerankers : Mustang, Ascorer : premier scoring brut puis Twiddlers, NavBoost, verticales : re-tri selon CTR, fraîcheur, E-E-A-T, etc.
- Nous vous invitons à relire notre article sur le Google leak de 2024 pour un rappel sur les principaux composants du moteur :
https://www.resoneo.com/google-leak-part-6-plongee-dans-les-entrailles-de-google-search-infrastructure-et-environnements-internes/
En clair, lorsqu’un mot-clé arrive enfin à l’étape de classement brut, il est déjà enrichi, filtré, parfois réécrit… et l’on dispose, pour chaque document candidat, d’un premier score purement lexical – avant que la popularité et le contexte ne réordonnent l’ensemble.
Note : Les informations présentées proviennent exclusivement de sources publiques accessibles sans contournement d’accès ni intrusion. Elles sont publiées à titre informatif..
La méthode présentée dans cet article n’est pas dévoilée – si vous la cherchez, vous trouverez, mais si vous le dites à tout le monde, Google corrigera la faille rapidement et ce serait dommage ^^
Cet article fait partie d’une publication plus large révélant différents systèmes internes à Google.
>> Retrouvez l’intégralité des articles sur le site Abondance.com

