
Nous avons eu le privilège d’assister aux conférences du 3ème jour QueDuWeb, le 10 juin 2016. Vous pouvez d’ailleurs retrouver le résumé complet et les slides des 3 jours sur notre blog.
Détail qui a son importance, il faut savoir que 2 conférences étaient prévues au même moment au sein de la salle JFK et la salle Lexington entraînant un choix cornélien tout au long de la journée. En voici notre retour :
- 1. Détecter et nettoyer le contenu générique lors de scraps
- 2. De 0 à 1,5 millions de visiteurs/mois ? Les coulisses d’un projet gagnant
- 3. Pernod Ricard et le challenge du Social Media Management dans un groupe
- 4. Analysez vos données en SEO avec R et Kibana
- 5. Le cocon sémantique
- 6. Analyse de données automatisée et optimisation de site
- 7. La publicité sans tracking
Voici le programme de la 3ème journée avec les conférences auxquelles nous avons assistées:
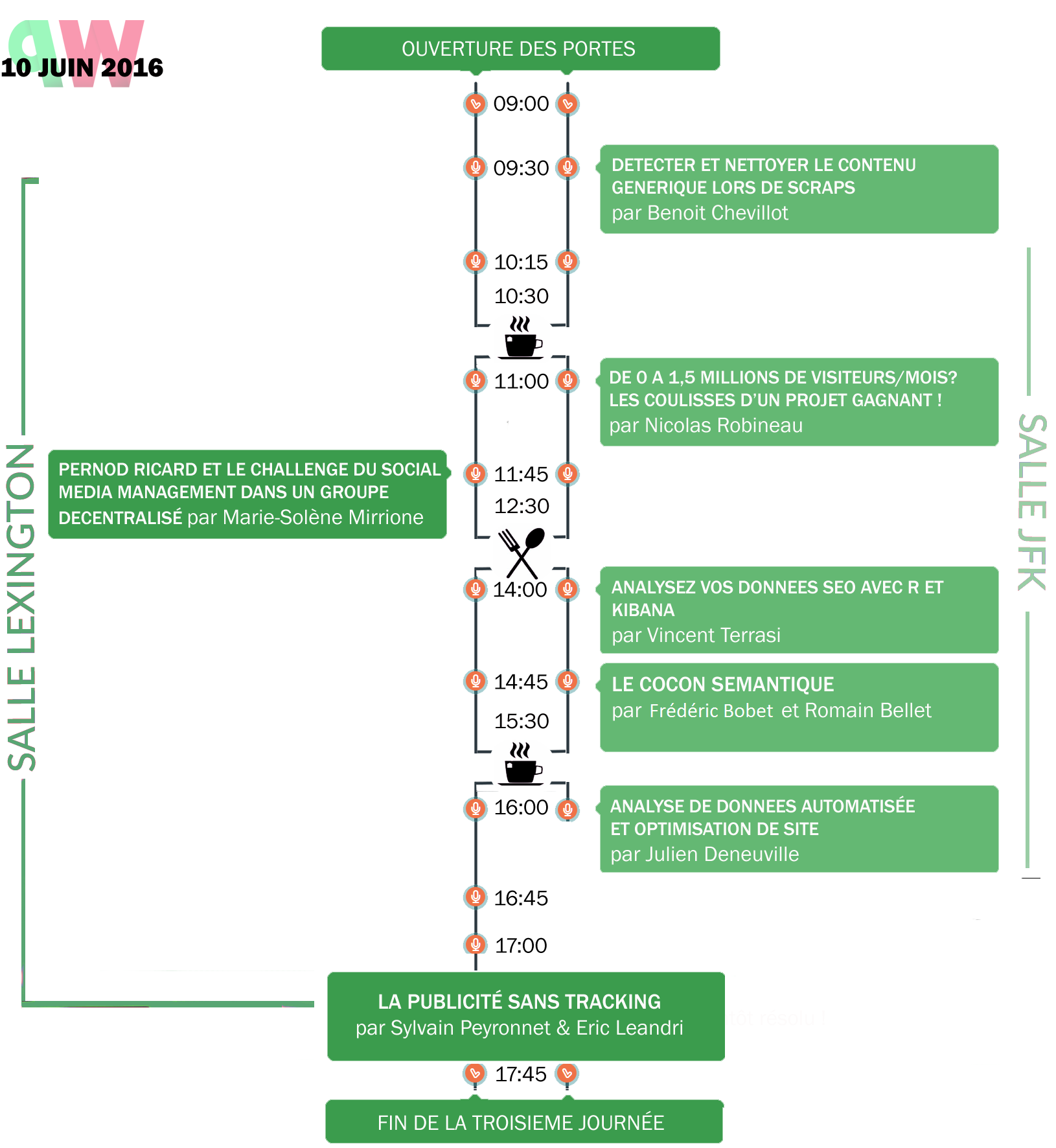
Détecter et nettoyer le contenu générique lors de scraps
Pour cette 1ère conférence de la journée de vendredi, Benoit Chevillot nous a présenté une méthodologie et des outils pour obtenir ce qui nous intéresse lors des scraps (Pour rappel, scraper consiste à récupérer des données à la volée depuis une ou plusieurs sources, typiquement un site web) en enlevant les éléments non pertinents.

Conférence sur le nettoyage de scraps
Pour cela, il nous a expliqué le concept de « Boilerplate » dont voici la définition : « se dit pour un texte (boilerplate text), une fonctionnalité d’un programme informatique dont le code source est quasiment le même quel que soit le programme (boilerplate code) ». Le boilerplate est donc un modèle (HTML) permettant d’obtenir un prototype de pages web.
Une fois que le scrap est effectué, il faut donc nettoyer le code source. La question se pose alors de le faire pendant le crawl ou après. Le conseil de Benoit est de faire les 2 en même temps. Il existe différentes technos pour cela comme les expressions régulières et le DOM (Document Object Model), et au niveau des outils Benoit conseille d’utiliser Boilerpipe qui est un framework de nettoyage du code.
Pour résumé, voici ce qu’il faut retenir :

Conseils de Benoit sur le nettoyage de vos scraps
Source : https://twitter.com/smonnier/status/741178337347932160
Dernière astuce de la part de Benoit : pensez à enregistrer vos exports Screaming Frog au format Excel et non au format CSV pour éviter les dysfonctionnements liés aux caractères spéciaux.
Et n’oubliez pas d’être vigilant lors de vos scraps :
Un seul PC est capable de faire tomber 1 site d’un grand groupe avec Screaming Frog : config serveur non robuste #queduweb
— Resoneo (@resoneo) 10 juin 2016
Voici les slides de présentation de la conférence :
De 0 à 1,5 millions de visiteurs/mois ? Les coulisses d’un projet gagnant
Pour cette conférence sous la forme retour d’expérience, Nicolas Robineau a expliqué étape par étape l’évolution de Tirage Gagnant, un portail sur les jeux de hasard et de tirage, en effectuant un focus sur les échecs et les réussites de ce projet.

Conférence retour d’expérience Tirage Gagnant
Ce qui est important de noter, c’est qu’il a été nécessaire à Nicolas de se remettre en question, notamment suite au lancement de Google Pingouin, et d’aller chercher des techniques sentant moins le SEO. Exit les annuaires et les commentaires de blogs, la stratégie de liens s’est orientée vers les RP (Relations Presse) passant comme l’explique Nicolas du Netlinking au Biolinking.
Autre point et non des moindres, le choix technologique de passer le site mobile a clairement été un facteur de réussite sans oublier la visibilité acquise grâce à Google AMP compte tenu du peu de concurrence actuelle et la position du carrousel en top position.
Enfin, s’il y a bien un élément qu’a voulu faire passer Nicolas au sein de sa conférence, c’est le lien humain. Utiliser les RP a tendance à faire travailler le contact humain et le réseau non pas virtuel mais de sa vraie vie. Cela a pour conséquence de créer de la notoriété sur le long terme qui ne risque pas de s’effondrer au moindre soubresaut de Google. A partir de ce constat, il n’y a aucun problème à être dépendant du SEO car l’autorité ou le branding préserve des mauvaises surprises.
En résumé, voici l’état d’esprit à avoir. #queduweb pic.twitter.com/54RAicAPRI
— Resoneo (@resoneo) 10 juin 2016
Pernod Ricard et le challenge du Social Media Management dans un groupe
Alors que nous avions privilégié les conférences de la salle JFK jusqu’à maintenant, nous avons opté pour la conférence en salle Lexington. Nous avons eu l’honneur de voir Marie-Solène Mirrione du groupe Pernod Ricard intervenir et nous parler Social Média Management.
Quand Marie-Solène nous montre les chiffres de ce qu’il se passe quotidiennement en interne, à savoir 600 pages Facebook / 200 comptes Instagram / 170 comptes Twitter / 80 chaines Youtube / 15 pages LinkedIn et tout ça pour 60 millions de followers, nous comprenons assez vite que les enjeux et les problématiques sont gigantesques.
Ensuite, Marie-Solène explique qu’il est plus avantageux de partir du consommateur pour comprendre ses besoins et non l’inverse car l’objectif est d’avoir le plus d’interactions et d’impacts au niveau social.
Nous apprenons par la suite que Marie-Solène utilise une solution pour piloter ses campagnes Social Média s’appelant Sprinklr.
Ce projet Sprinklr au sein du groupe Pernod Ricard lui a permis de retenir 10 leçons :
- 1. Maitriser l’outil
- 2. Connaitre ses limites
- 3. S’inspirer de l’existant
- 4. Recueillir les avis des utilisateurs
- 5. Implémenter des règles
- 6. Avancer étape par étape
- 7. Travailler en équipe
- 8. Former les formateurs
- 9. Communiquer
- 10. Mesurer la performance
La dernière notion importante à retenir de la conférence réside dans le fait qu’il faut s’attendre à une gestion de projet compliquée afin d’anticiper les dysfonctionnements au maximum.
Analysez vos données en SEO avec R et Kibana
Une conférence pointue présentée par Vincent Terrasi sur les outils disponibles pour analyser facilement les logs et les données qui en découlent.

Conférence analyse de données avec R et Kibana
Vincent a tout d’abord expliqué les notions de Crawler et de Logs mais également l’importance d’avoir un outil pour analyser en temps réel ses données. Il a ensuite présenté R, un outil peu connu au sein de notre profession. Voici la définition que nous pouvons trouver sur Wikipédia : R est un logiciel libre de traitement des données et d’analyse statistiques mettant en oeuvre le langage de programmation S.
Mais avant d’utiliser R, il faut collecter les données et c’est là qu’intervient un crawler tel que Screaming Frog avec sa fonction d’export. Une fois ce travail effectué, R va nous servir à consolider les données pour le but que nous nous sommes fixé comme utiliser les fonctions de R pour obtenir des éléments plus visuels comme des graphiques, des diagrammes, des camemberts ou plus simplement pouvoir injecter toutes les variables qui manquent dans les logs (compliant, depth, active, …).
Une fois le fichier CSV généré depuis R et pour obtenir une visualisation plus flexible et automatisée, Vincent conseille d’utiliser Logstash, outil de collecte, analyse et stockage de logs, couplé à Kibana qui est une plateforme de visualisation de données OpenSource.
Autre solution présentée par Vincent en exclusivité : PaasLogs (Platform as a service), de la société OVH, qui est une solution clef-en-main pour effectuer tout le travail d’analyse des logs en quelques clics. Ainsi, de la collecte des logs et sa manipulation par Logstash à la visualisation par Kibana, tout est configurable et administrable au sein de cette solution.
Pour en savoir plus sur comment fonctionne PaasLogs, voici un tutoriel proposé par Vincent : tutoriel pour créer un analyseur de logs.
Voici les slides de présentation de la conférence :
Le cocon sémantique
Vaste sujet pour cette conférence animée par Fred Bobet et Romain Bellet qui ont eu l’idée de s’appuyer sur l’outil Yooda Insight.

Conférence cocon sémantique
Ainsi, la première étape à l’élaboration d’un cocon réside dans la collecte des mots clés et pour cela Fred et Romain se sont appuyés sur Yooda Insight.
Nous apprenons ensuite diverses choses comme le fait que les requêtes sont en moyenne composées de 3 mots.
Fred et Romain en ont profité pour s’attarder sur le concept de structure macroscopique, de l’informationnel à l’intentionnel ou transactionnel, et plus précisément sur la typologie de mots clés selon l’intention de recherche. Il est également question de l’influence du cocon sur le pagerank, à cet effet il existe des outils pour améliorer et/ou visualiser les cocons comme http://cocon.se/, de la notion de clusterisation et du glissement sémantique.
Enfin, Fred et Romain ont expliqué l’importance de bien considérer l’intention en fonction des personas dans le but d’être présent à chaque étape de la démarche d’achat et donc d’optimiser la fidélisation.
Analyse de données automatisée et optimisation de site
L’avant-dernière conférence que nous avons pu suivre du côté de la salle JFK portait sur les notions d’automatisation au service de la prise de décision et fût présenté par Julien Deneuville et Nicolas Chollet.
Plusieurs éléments et notions nous ont été présentés comme le Deep Learning ou comment apprendre à une machine à reconnaitre. Autre point, les conférenciers insistent sur le fait de ne pas passer plus de 5 minutes par jour sur les KPI de chaque client et sur le fait d’être critique avec les données affichées en évitant de prendre des décisions dans la précipitation.
Ensuite, de manière plus concrète, les conférenciers ont exprimé l’importance de la segmentation dans les analyses de Data en vérifiant la véracité de la Data et le fait que le seul élément fiable c’est ce qui est marqué dans les Logs : les Logs ne mentent pas.
L’accent a également été mis sur les algorithmes d’apprentissage supervisés et sur le concept de Test & Learn.
En résumé :
- 1. La quantité de données augmentent et leur complexité aussi
- 2. Il est donc primordial de s’outiller pour visualiser et rendre intelligible toutes ces données
- 3. La machine est un super outil pour mettre en lumière la data pertinente
- 4. Il est donc nécessaire de s’appuyer sur des algos et des actions assistées par ordinateur tout en effectuant des contrôles
- 5. Compte tenu de l’évolution technologique actuelle, le futur réside dans la compréhension de l’intention et sa contextualisation en fonction des différents appareils.
Voici les slides de présentation de la conférence :
La publicité sans tracking
Pour clôturer cette journée, nous avons eu une démonstration de Sylvain Peyronnet et Eric Léandri que la publicité sans tracking est possible et bien réelle.
Sans surprise, Sylvain et Eric nous explique que le retargeting est contre-productif si c’est trop répété, la stat étant qu’une pub affichée 10 fois pour une même cible a tendance à énerver 30% des clients. Ensuite, Sylvain et Eric argumentent sur le fait que le contexte et le référer (en sachant d’où vient la cible il est possible de connaitre ses intentions) suffisent à afficher une pub ciblée en évitant d’être trop intrusif.
Autre élément important : il est anormal d’être tracké alors qu’il n’y a eu aucun acte d’achat au préalable. Le consentement tacite n’est appliqué que dans le cas où le client a réellement passé commande et a donc accepté d’apparaître au sein de la base de données du site.
Enfin, dernier point notable : adblock n’est pas censé pouvoir filtrer les publicités sans tracking et comme le dit si justement Eric Léandri, je cite : « Si AdBlock bloque même la publicité sans tracking, c’est qu’ils sont uniquement là pour vous racketter ». Ainsi après vérification sur des sites tests, les analyses montrent que le CTR des pubs sans tracking a tendance à être supérieur à celui des pubs avec tracking.
Pour finir et concernant Qwant, Eric nous a montré que l’insertion de pub sponsorisée est prévue au sein du moteur comme le montre le tweet ci-dessous :
Utiliser le visuel dans la SERP pour protéger sa marque @speyronnet @QueDuWeb #queduweb pic.twitter.com/x0tLomTuTH
— SEMrush France (@semrush_fr) 10 juin 2016

