
Google a désormais intégré l’intelligence artificielle à son cœur de métier, le search. RankBrain permet d’analyser la sémantique des mots, les relations entre les mots, en fonction du contexte pour finalement comprendre l’intention derrière la requête et ainsi encore améliorer la pertinence des résultats de recherche, avec pour finalité, l’amélioration de l’expérience utilisateur.

L’intention de recherche
Une des motivations premières de cette évolution de l’algorithme de recherche est bien évidemment due à la multiplication des recherches vocales qui créent des requêtes plus variées, vagues et complexes pour les moteurs de recherche.
RankBrain a été conçu pour y répondre dans la continuité de Hummingbird.
Cela vous semble obscur ? Un exemple va vous permettre de bien comprendre :
- L’intelligence artificielle de RankBrain pourrait (et peut déjà) apprendre dans un article en ligne qu’un certain Eddy de Pretto est l’auteur d’une chanson : La fête de trop. Il va alors comprendre que le chanteur est une entité et le titre de la chanson, une autre entité associée.
- Une autre page d’un site e-commerce propose des places de concert pour voir Eddy de Pretto à Paris au mois de juillet.
- Un internaute résidant à Paris fait la requête vocale suivante :
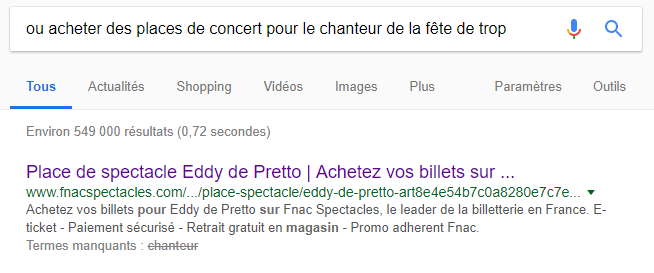
- “ou acheter des places de concert pour le chanteur de la fête de trop”
- Même si la requête ne contient aucune des entités Eddy de Pretto, Paris et la date du concert, Google peut lui présenter la page d’un site e-commerce proposant des places de concert pour voir Eddy de Pretto à Paris en juillet !
Comment est-ce que cela fonctionne ?
RankBrain utilise l’intelligence artificielle pour transformer le langage en entités mathématiques, appelées “vecteurs” que les algorithmes peuvent traiter. Quand RankBrain rencontre un mot ou une expression avec laquelle il n’est pas familier, il peut tenter de deviner quel mot ou phrase peut avoir un sens similaire et présenter des résultats en conséquence. Sur les quelques 7 milliards de recherche quotidiennes, 15 % n’avaient jamais été recherchées et RankBrain aide Google à gérer plus efficacement ces 15 % de requêtes jamais vues auparavant.
Cela peut inclure l’utilisation de “mots vides” (“stop word” en anglais) dans une requête de recherche (“le”, “et”, “sans”, etc.) – des mots historiquement ignorés par Google, mais qui ont parfois une importance majeure pour comprendre pleinement la signification ou l’intention derrière la requête. Il est également capable d’établir des schémas de correspondance entre des recherches apparemment non liées, afin de comprendre dans quelle mesure ces recherches sont similaires les unes aux autres.
RankBrain fait partie des centaines de signaux entrés dans l’algorithme qui déterminent quels résultats apparaissent dans les SERP et comment ils sont classés. D’après Google, RankBrain serait devenu le 3e critère le plus important contribuant aux résultats de recherche, avec les liens entrants et le contenu. C’est le fruit d’une décennie d’efforts et d’investissements de la part de Google dans les technologies de l’intelligence artificielle.
Qu’est-ce que le “machine learning” ?
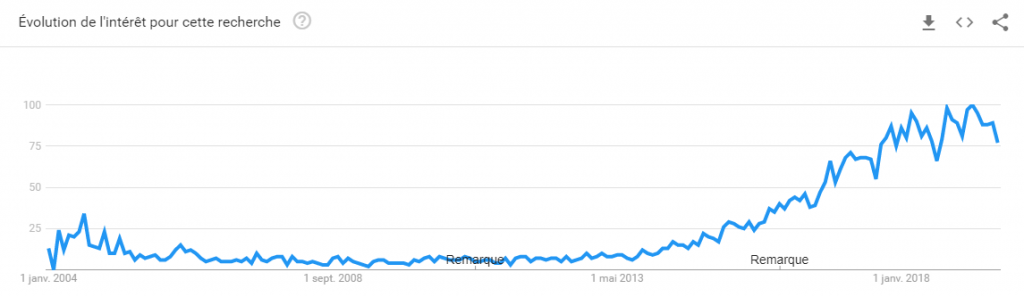
Le terme “machine learning” est devenu de plus en plus grand public ces 5 dernières années, pour preuve l’évolution de l’intérêt pour cette requête.
Il s’agit d’un ensemble de techniques et de technologies, qui ont entre autres deux objectifs :
– Classification automatique : Placer des individus dans des classes, c’est-à-dire des ensembles qui partagent des caractères statistiques communs.
– L’analyse prédictive : Analyser des données issues de comportements passés et en extraire un schéma commun afin d’imaginer des possibilités d’évolution des comportements. Les algorithmes évoluent alors pour se calquer sur les attentes et les comportements des internautes et adapter ses résultats.
Cet apprentissage peut se faire de deux façons :
Apprentissage automatique avec supervision
C’est-à-dire que l’on fournit à la machine, en entrée, les différentes associations d’individus et de caractéristiques, puis la machine construit un modèle prédictif à partir de ces informations. La principale limite est qu’elle n’est capable de reconnaître que ce que les humains peuvent lui apprendre. C’est le cas des algorithmes Panda, Pingouin ou encore les filtres de spam des boites mail. C’est une approche très efficace mais qui a un coût humain et en temps très important.
Apprentissage automatique sans supervision
On laisse la machine chercher des structures cachées dans les données pour différencier les classes d’individus. C’est ce que l’on nommera le “deep learning”, on verra plus loin quel impact cela pourrait avoir sur le SEO. Le gros avantage de ce mode d’apprentissage est que la machine recherche des caractéristiques cachées. En termes de SEO, un bon exemple de caractéristique cachée est la balise meta-keyword ! En effet, on sait tous que cette balise n’a plus aucun intérêt pour le SEO, pourtant ce pourrait être une bonne caractéristique pour évaluer la qualité d’une page, car généralement quand elle est remplie avec du texte bien rédigé, c’est un signe que des gens qui ont pris le temps de renseigner ces informations. On peut supposer qu’ils ont aussi pris du temps pour proposer un contenu qualitatif.

Comment RankBrain utilise le deep learning ?
Qu’est-ce que le Deep Learning (ou réseau profond)
On peut dire trivialement qu’il s’agit d’un empilement de réseaux de neurones qui vont chacun s’attacher à étudier des critères différents. Un peu comme le fonctionnement d’un cerveau, différents blocs vont gérer et analyser différents niveaux de lecture de la donnée, on parle de couches de lecture.
Si on prend l’exemple de reconnaissance d’images, la machine va pouvoir analyser tous les pixels pour reconnaître des formes, faire correspondre ces formes avec des bases de données, des couleurs, premier plan et arrière-plan …
Modèles mathématiques et réseau de neurones artificiels
Pour savoir si un texte est pertinent pour une requête, le moteur de recherche va créer une représentation mathématique du texte décomposé en “vecteurs”.
Le modèle originel utilisé pour mesurer la pertinence d’un texte par rapport à une requête donnée, était la méthode TF-IDF (Term Frequency – Inverse Document Frequency), qui utilise la fréquence d’apparition des mots dans le texte et la fréquence d’apparition des mêmes mots dans l’index de Google, pour attribuer un score à chaque mot du texte.
Aujourd’hui, Word Embedding est un type de représentation des mots en vecteurs à l’aide d’un réseau de neurones artificiels et d’un modèle probabiliste. En résumé, il s’agit d’une modélisation du langage et d’une technique d’apprentissage de ses caractéristiques.
Les premiers modèles performants dans ce domaine ont été word2vec (Google), Glove (Stanford) et fastext (Facebook).
Cette dernière année a vu une accélération des progrès dans ce domaine, grâce à une augmentation considérable de la puissance de calcul (utilisation des TPU « Tensor Processing Unit ») et l’apparition de nouveaux modèles de Word Embedding encore plus performants. On peut citer Google Bert, ELMo (Allen Institute), GPT-2 (Open AI) ou encore ULM-FIT. Ces modèles permettent un apprentissage du sens des mots en fonction de leur contexte.
Les applications sont nombreuses : traduction automatique, analyse de sentiment, résumé de texte, génération automatique de texte, question/réponse, chatbot, etc…
Un apprentissage pas encore en temps réel
Toute la partie apprentissage de RankBrain se fait actuellement hors-ligne. Google lui donne à traiter des lots d’historiques de recherches et RankBrain fait des prédictions à partir de ceux-ci. Ces prédictions sont ensuite testées et, si elles s’avèrent pertinentes, elles sont déployées dans la dernière version.

L’IA au service du NLP
Ces dernières années, ces avancées importantes dans le domaine de l’IA permettent aux moteurs de recherche de mieux comprendre l’intention de recherche des internautes. Ceci est d’autant plus important que la recherche vocale change énormément la façon dont les internautes formulent leurs recherches.
De la détection de synonymes à la désambiguïsation de requêtes inédites à l’aide de la reconnaissance d’entités nommées, en passant par l’analyse des sentiments, le traitement du langage naturel joue un rôle central dans la manière dont les moteurs de recherche comme Google et Bing, ainsi que les assistants numériques personnels, traitent nos demandes, indexent les sites web et trouvent un contenu pertinent sur le Web.
Regardons d’un peu plus près comment fonctionne le NLP (Natural Langage Processing)
1. Tokenization : La tokenization est le processus qui consiste à scinder une phrase en ses termes distincts
![]()
2. Qualification des mots (Part-of-speech tagging) : Consiste à définir le rôle grammatical du mot dans la phrase.

3. Lemmatization : transformation des verbes à l’infinitif, les noms et les adjectifs au singulier et au masculin.

4. Dépendance entre les mots (Word Dependency) : crée des relations entre les mots, basées sur les règles de grammaire.

5. Classification des dépendances entre les mots (Parse label) : Définit le type de relation en deux mots reliés par une dépendance.

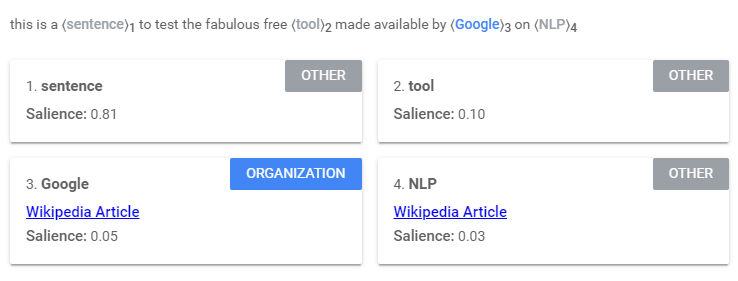
6. Extraction des entités nommées : Il s’agit d’identifier les mots ayant un sens connu. Cela peut être des personnes, des lieux ou des choses (noms). Ici des mots comme « sentence » et « tool » sont des entités, tout comme « Google » et « NLP ».
7. La thématisation du texte : Détermine la quantité de texte qu’il y a à propos d’un sujet. La pertinence d’un texte par rapport à un mot ou un sujet est déterminé en NLP à partir de ce que nous appelons des mots indicateurs.
8. Sentiment : il s’agit d’un score négatif ou positif du sentiment exprimé à l’égard des entités dans un article.

9. Catégorisation des sujets : D’un point de vue macro, la NLP permet également de classer le texte dans une catégorie de sujets.

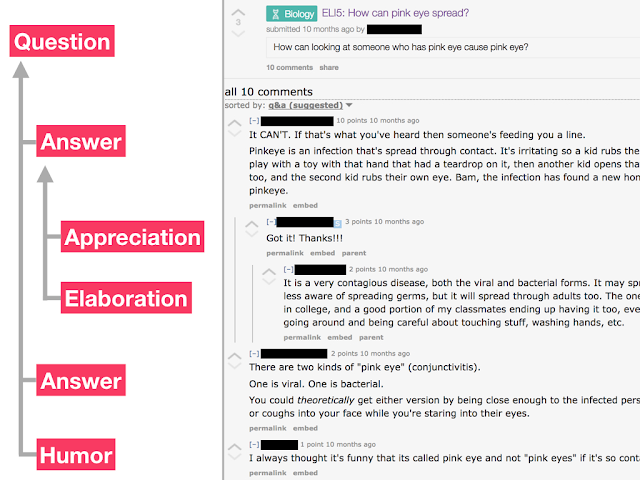
10. Classification de la fonction du texte : La NLP peut permettre d’aller plus loin et de classifier la fonction d’un contenu dans une catégorie, comme les compliments, l’humour, les questions, et les réponses (Google AI Blog).
11. Extraction par type de contenu : Google peut utiliser des schémas dans la structure du contenu pour déterminer le type de texte (sans données structurées). Ce processus permet à Google de déterminer si le texte est un événement, une recette, un produit ou un autre type de contenu sans utiliser de balisage particulier.
12. Signification implicite de la structure : Le formatage d’un corps de texte peut changer son sens implicite. Les titres, les sauts de ligne, les listes sont également porteurs d’une information pour le sens du texte. Par exemple, si du texte apparaît dans une liste HTML ordonnée ou une série d’en-têtes avec des chiffres devant eux, c’est probablement un processus ou un classement. La structure n’est pas seulement définie par des balises HTML, mais aussi par la taille et le poids des polices de caractère.
Alors que des outils comme Google NLP peuvent nous permettre d’examiner ce processus une phrase à la fois, Google construit ces relations avec de plus gros volumes de texte. On peut dire que le sens est déterminé par phrase, par paragraphe, par section et par page !
Comment Google RankBrain affecte-t-il le SEO
Comme son nom ne le laisse pas supposer, RankBrain n’est pas un algorithme de classement à proprement parler comme peuvent l’être Penguin ou Panda, mais il a néanmoins un effet sur les résultats de recherche.
La difficulté pour le SEO, c’est déjà l’impossibilité de savoir quels sont les critères utilisés par le deep learning. On ne saura pas exactement quels sont les critères qui fonctionnent, ni le poids associé aux différents critères. En cas d’apparition “d’erreurs” ou de baisse du SEO, on ne saura pas forcément quelle action correctrice mettre en place.
Si on ne donne pas de limites à l’algorithme, il apprend à partir de tout ce qu’il voit et ce qu’il peut analyser, il fera de la personnalisation à outrance.
Le moteur de recherche ne saura pas forcément lui-même comment il va classer les résultats ! Amit Singhal a d’ailleurs quitté son poste chez Google en partie à cause de son désaccord avec cette approche.

Les règles du jeu ne seront plus établies et gravées dans le marbre, même si c’était déjà un petit peu le cas avec les différentes mises à jour auxquelles Google nous avait habitué. Maintenant, l’apprentissage étant permanent, les changements peuvent survenir, positivement ou négativement, spécifiquement, requête par requête.
Alors que dans le passé les moteurs de recherche comme Google travaillaient avec des modèles statistiques construits autour de mots-clés et de liens, nous voyons maintenant les algorithmes de « machine learning » influencer profondément la qualité des résultats ainsi que la façon dont ces résultats sont présentés à l’utilisateur final : des réponses vocales aux « featured snippet », des widgets interactifs comme le carrousel de « news » ou aux PAA (People Also Ask), ou encore aux positions zéro dans les SERP.
Le SEO face à ces changements
Les règles du jeu vont être fondamentalement changées par l’arrivée du machine learning et du deep learning, car elles ne sont plus définies uniquement par les ingénieurs de Google mais par la machine elle-même.
Votre stratégie SEO doit être encore davantage tournée vers l’utilisateur pour répondre aux changements du fonctionnement des moteurs de recherche.
Google veut fournir aux utilisateurs des résultats qui sauront répondre à leurs intentions de recherche. Ce sont les règles en usage aujourd’hui et la façon dont les internautes y adhèrent qui vont permettre de créer de futures règles de classement.
Si vous mettez l’accent sur du contenu de qualité et des services pertinents, votre positionnement dans les résultats de recherche devrait s’améliorer.
– Il faudra donc abandonner l’approche actuelle, qui est d’optimiser une page pour un mot-clé ou une requête précise, pour proposer des contenus utiles sur une thématique. Il ne faut plus se concentrer sur la requête de l’internaute, mais plutôt sur son besoin.
– Il faudra mettre encore plus l’accent sur la recherche de mots-clés afin de couvrir les thématiques complémentaires à celle centrale que l’on voulait optimiser, et établir des connexions entre les requêtes comme peut le faire RankBrain lui-même. La volonté de cette technologie est de répondre au mieux à des requêtes spécifiques en “longue-traîne”.
– La qualité du contenu étant vraiment centrale, on ne pourra plus se contenter de travailler x fois le mot-clé principal, et les mots-clés secondaires mais plutôt essayer de répondre à un ensemble de questions que peuvent se poser les internautes autour d’une thématique, et éventuellement proposer des sous-thématiques.
– De la même façon que Google a évolué pour privilégier les backlinks de qualité par rapport à la quantité, on peut penser que l’évolution va dans le même sens pour le contenu. Plutôt que de publier du contenu frais à faible valeur ajoutée régulièrement sur un site, il faudra plutôt évaluer quel contenu est apprécié des internautes. Pour ce faire, on peut utiliser tous les indicateurs à notre disposition, comme le taux de rebond, le temps passé sur la page, les partages sur les réseaux sociaux
– Il semble que le principe d’un mot-clé par page” soit mort. RankBrain privilégie le contenu qui va plus en profondeur et qui s’adresse à de vraies personnes. Cibler des mots-clés spécifiques à votre audience et rendre votre texte captivant, vous aidera à améliorer vos positions dans les SERPs. Il s’agit donc de faire de votre texte une mine d’information, y compris en proposant des ressources externes. Ne soyez donc pas avare de liens sortants !
– Ne privilégiez pas une approche unique, certaines requêtes nécessitent des réponses courtes et concises, là où d’autre attendent une analyse approfondie.
Les SEO se devront désormais d’utiliser les mêmes outils que les moteurs de recherche, par exemple analyser la bonne surface sémantique d’un site grâce aux API de machine learning de traitement du langage du marché. Cela permettra par exemple d’orienter correctement le maillage interne d’un site, ou encore de détecter et d’utiliser les expressions/entités qui plairont à Google dans les contenus.

Conclusion
La technologie RankBrain ne remplacera en rien les autres critères de classement, elle permettra simplement de récompenser les contenus utiles à l’internaute. Rien de nouveau donc pour le SEO.
Cependant, on peut quand même apporter des éléments de réponse sur ce que Google considère comme un contenu de qualité.
Cette évolution signifie que les marketeurs doivent se concentrer sur ce qui est le mieux pour l’audience de leurs sites Web, plutôt que sur ce que Google préfèrerait. RankBrain est clairement une incitation pour les rédacteurs web et les marketeurs, à mieux connaître leur cible et à affiner le contenu créé, pour répondre au plus près de son attente.
Au fur et à mesure que cet algorithme se développe, on s’attend à ce qu’il impose de nombreux changements pour le référencement et la création de contenu. RankBrain va croître continuellement et les SEOs doivent être préparés aux défis que cela va apporter.
Chaque fois que Google fait une mise à jour majeure, certains annoncent la mort du SEO. Cette fois-ci, ce pourrait bien être une réalité, le SEO pourrait bel et bien disparaître mais seulement pour laisser la place au SXO (Search eXperience Optimization).

