
A quelle fréquence Googlebot vient-il visiter les pages d’un site ? Sur quelles pages revient-il le plus souvent ? Quels codes de statut HTTP lui sont renvoyés ? Quelles sont les pages orphelines ? Quelles sont les pages actives ? Quels sont les bots les plus les plus friands d’un site ? Est-ce que mon budget de crawl est optimisé ? Voici le type de questions auxquelles les logs serveur peuvent répondre. Retour sur quelques exemples de réussites SEO liées à l’analyse de logs.

Par définition, un fichier de logs est un journal recensant tous les évènements produits sur un serveur web. Il contient l’ensemble des hits effectués sur un serveur. Selon son paramétrage, il peut contenir : hostname, URL appelée, timestamp, referrer, code reponse, user-agent, etc.
Mais d’où viennent ces pages crawlées ?
Au cours de l’audit d’un de nos clients – un retailer leader dans le secteur du meuble – nous avons identifié un crawl erratique de Google depuis la Search Console. Se posait alors la question de savoir quelle en était l’origine et quelles étaient les URL concernées par ce crawl en dents de scie.
Le rapport d’activité de Googlebot sur les 90 derniers jours est très pratique pour avoir une idée générale du volume journalier de pages explorées par le robot, mais reste trop léger pour avoir plus de détail quant aux pages et types de contenus concernés.
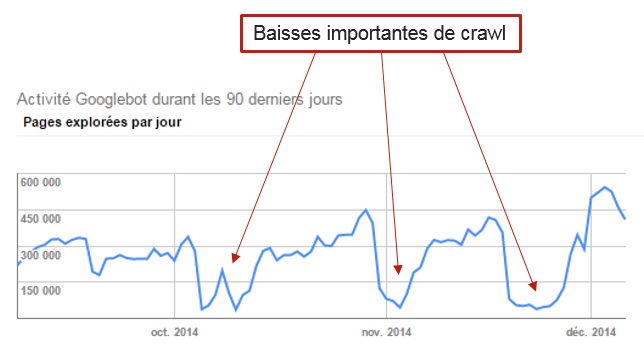
Google Search Console indique une fréquence de crawl par GoogleBot qui est « en dents de scie »
Il a donc été nécessaire de se plonger dans les logs pour mieux comprendre ce qu’il se passait afin d’en tirer des conclusions.
Les premières étapes ont surtout permis d’écarter certaines hypothèses comme le fait que Google soit régulièrement confronté à des redirections internes, ce qui est souvent le cas pour un site marchand.
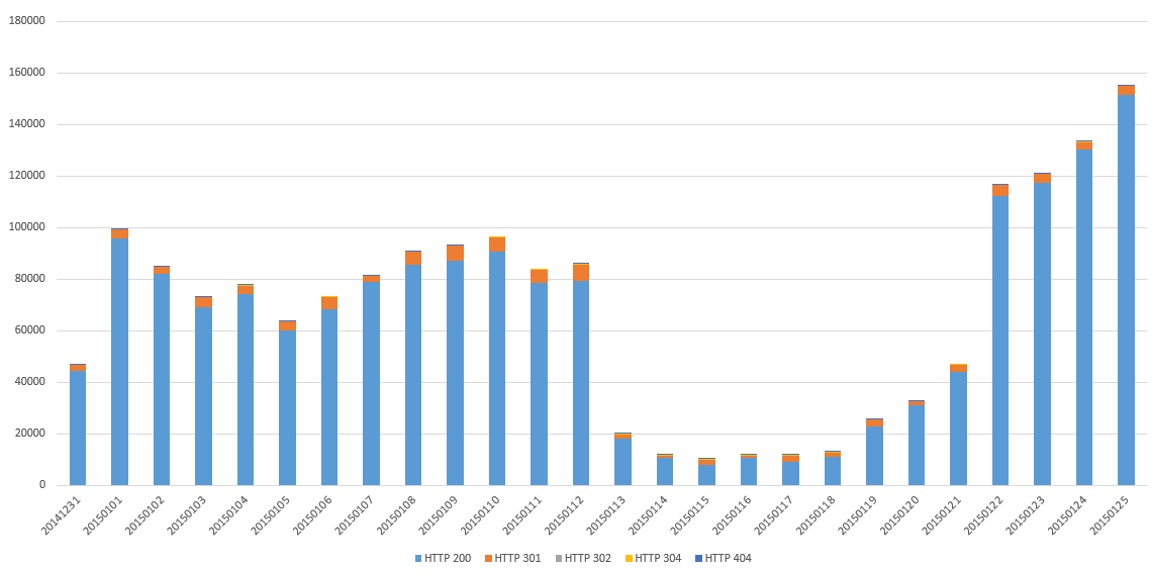
Le % de pages en 200 étant important, ce n’était pas à ce niveau que se situait le problème
C’est le découpage par type de pages qui nous a permis de découvrir que GoogleBot crawlait de façon abusive un type de pages qui était notamment concerné par l’utilisation d’un moteur à facettes. Cela s’apparentait à un spider trap, puisque rien n’avait été mis en place jusqu’ici pour contrôler leur accès à Google. Les robots avaient accès à toutes les combinaisons possibles. Le graphique montrant les pages concernées en bleu est assez révélateur.
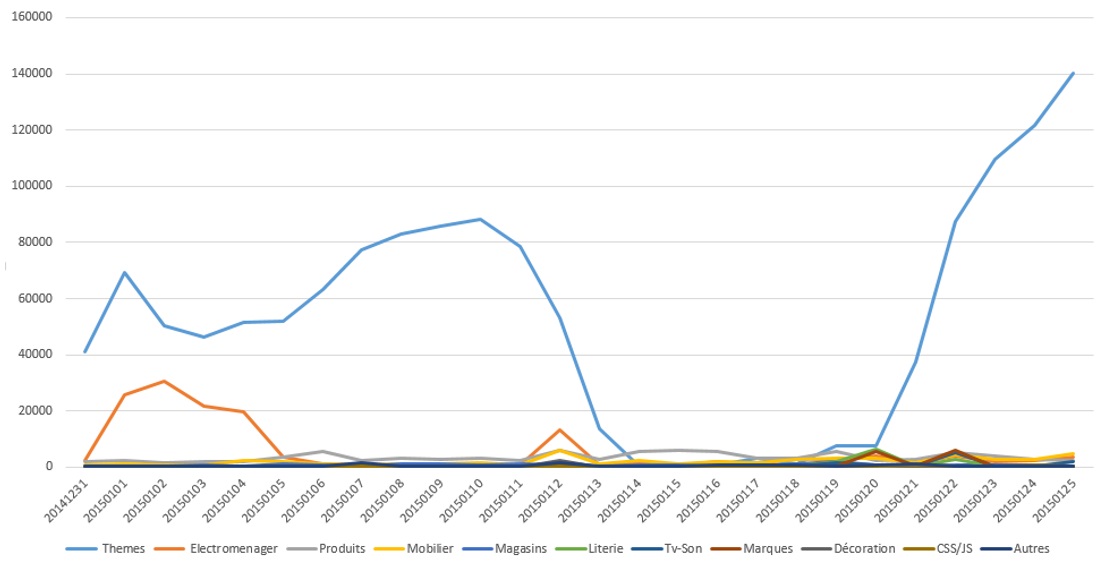
La courbe bleue montre la fréquence de hits Googlebot sur un type de page bien précis
Ces pages représentant un pourcentage marginal du trafic SEO, il a donc été décidé de bloquer radicalement le crawl de ces pages, pour que Google puisse se concentrer sur les pages plus stratégiques.
Une fois la consigne Disallow mise en place dans le fichier robots.txt, le crawl de Google est redevenu bien plus stable.
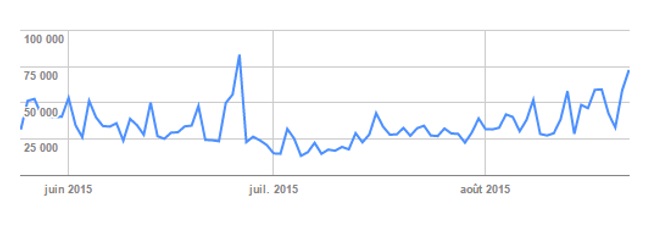
Un retour à la normale constaté 6 mois après
Cela a eu pour conséquence directe une amélioration de la rapidité d’indexation des nouvelles pages mises en ligne ainsi qu’une amélioration des positions et du trafic lié au référencement naturel.
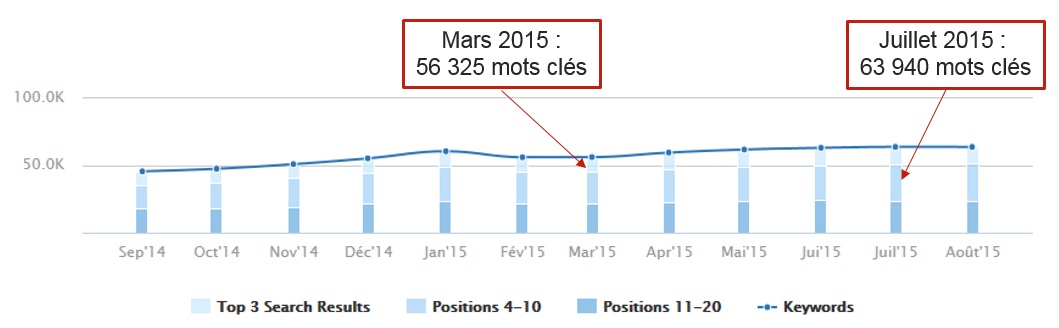
+ 7 615 kw gagnés sur 4 mois et accroissement (+ 3 914 kw) du nombre de requêtes en positions 4 à 10.
A la découverte d’un monde parallèle
Nous avons entrepris une analyse des logs serveur sur un site de biographies composé d’environ 40 000 URL. Nous cherchions à identifier les causes d’une baisse de positions suite au lancement d’une nouvelle version du site.
Une analyse croisée d’un crawl du site avec les logs a permis de valider que Google parcourait le site dans sa quasi intégralité.
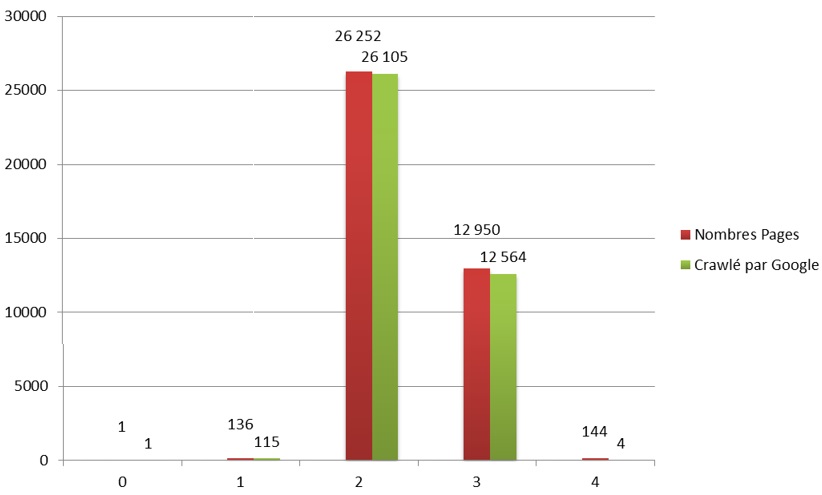
Une simulation de crawl VS l’analyse des pages crawlées par Googlebot
En s’attardant sur les pages actives – c’est à dire les pages ayant obtenu au moins une visite depuis les résultats organiques – nous avons constaté que 64 % des pages de niveau 2 n’étaient pas actives.
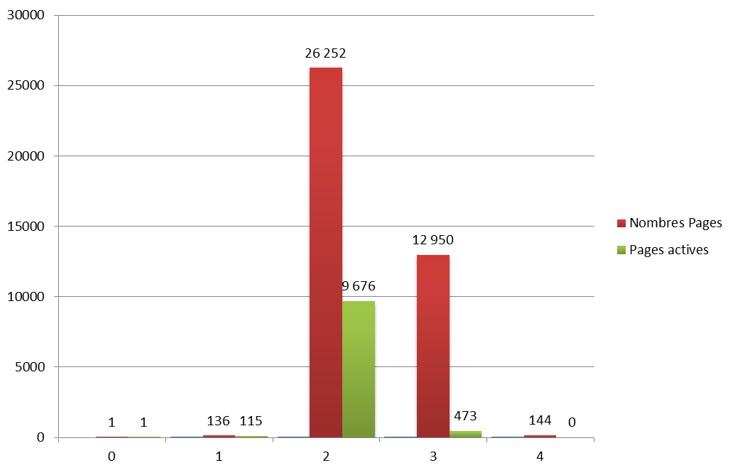
L’analyse des pages actives pour détecter les pages avec peu de valeur SEO
Dans le cas présent, ces URL inactives correspondaient à une mauvaise gestion de leur fonctionnement. Certaines pages dupliquées jusqu’à 8 fois étaient la cause de la perte de position du site dans les résultats naturels.
Les pages concernées par de la duplication de contenu étaient principalement :
- Anciennes URL, liées à l’ancienne version du site, qui répondaient toujours en 200
- Mauvaise gestion de la réécriture d’URL
- Dossier /en/ avec contenu en français
- Biographies en doublons (inversion nom prénom)
L’étude des logs a donc permis de lever le voile sur l’ensemble des sources de duplication de page et ainsi endiguer rapidement le problème.
Quand Googlebot s’acharne sur une seule page
Sur un site d’événement caritatif, nous avons constaté que le nombre de pages explorées chaque jour était extrêmement élevé, comparativement au volume de page total indexées (environ 4 690 résultats). Nous avons analysé le détail des URL crawlées afin de détecter une éventuelle fuite de crawl (exemple : spider-trap, chaine de paramètres, etc).
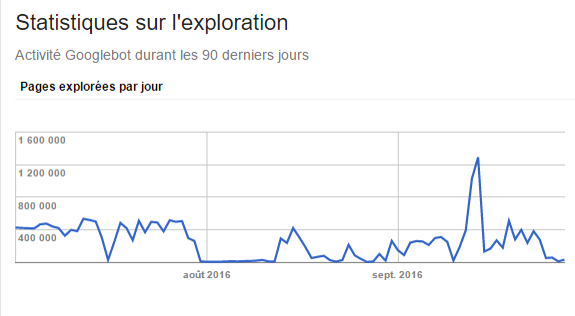
Un nombre astronomique de pages vues par Google quotidiennement !
En isolant les URL les plus visitées par Google, nous avons eu la surprise de découvrir qu’une seule page captait plus de 92% du crawl de Googlebot ! Ce comportement posait plusieurs problématiques :
- Des nouveaux contenus indexés plus lentement
- Des pages pertinentes moins fraîches dans l’index
- Une prise en compte plus lente du maillage interne
- Une limite des performances serveur : plus de 1.200.000 requêtes en provenance de Googlebot sur une même journée !
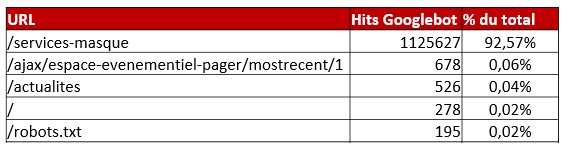
Le temps consacré à cette URL empêche les autres URL d’être crawlées régulièrement, ce qui peut nuire à un positionnement optimal
Dans la réalité, cette URL était crawlée avec une chaine de paramètres prenant cette forme :
- /services-masque?filter_%5B176%5D=176&filter_%5B113%5D=113&form_id=specifics_map_form
- /services-masque?filter_%5B176%5D=176&filter_%5B113%5D=113&form_build_id=form-WpxZ9kZ1We7mn3jL9UojSbcOsYCh2CFEfWVqutYH4Ho&form_id=specifics_map_form
Ce qui correspondait aux valeurs d’un formulaire envoyé en GET accessible à Googlebot :
Googlebot visite ces URL via le système de filtre de la page
Nous avons donc recommandé de bloquer l’accès à Googlebot aux paramètres via la consigne suivante dans le fichier robots.txt :
Disallow: /services-masque
Allow: /services-masque$
Quelques mois plus tard, suite à la mise en place de cette recommandations, nous avons constaté un retour à la normale du crawl de Google, une nette amélioration des performances en termes de temps de chargement et une hausse globale des performances SEO.
Un retour à la normale constaté rapidement
Les bots, des consommateurs de ressources serveur
Si tous les documents utiles doivent être parcourus pour pouvoir être présentés aux internautes, attention à la gourmandise parfois excessive de certains crawlers.

Il existe des centaines de bots, certains peuvent être très gourmands en ressources
Leur consommation de votre site peut directement impacter les performances techniques de celui-ci puisqu’ils sollicitent vos serveurs (de plus en plus) à la manière des internautes. Il n’est pas rare de constater que la majorité du trafic d’un site est en réalité composée de robots dont l’action n’est aucunement positive ! Une étude menée par Imperva Incapsula en 2015 indiquait que les « mauvais bots » représentaient cette année là 29% du trafic des sites, contre 19,5% pour les « bons bots ».
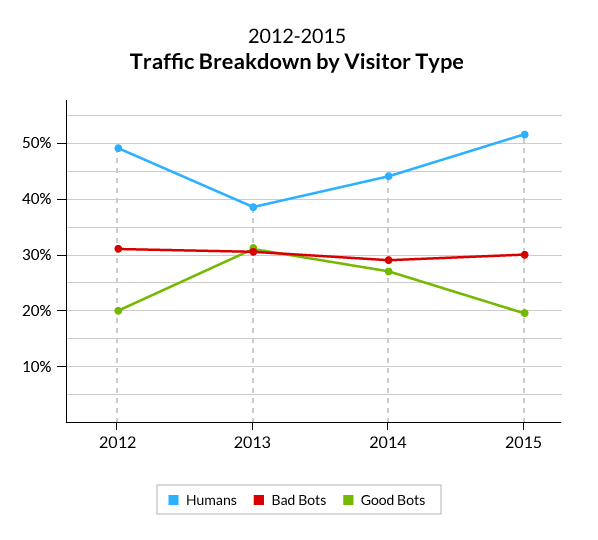
La progression entre 2012 et 2015 des types de visiteurs (humains ou robots)
Plutôt que de gaspiller des ressources serveur, coûteuses, des techniques peuvent être mises en place pour endiguer cette perte.
Au-delà du coût important que peut engendrer une sur-sollicitation de vos serveurs par des robots mal orientés, n’oublions pas que l’utilisateur final doit avoir accès à vos pages le plus rapidement possible. La bande passante de votre site doit être préservée pour un public qui vous est utile : internautes et robots bienveillants parcourant des pages à potentiel.
Lors de l’analyse des logs du site geneanet.org nous avons pu mettre en exergue que l’utilisation de techniques load balancing générait une dilution majeure du crawl de Google. Bien que les sous-domaine utilisés étaient redirigés en 301, Google les crawlait de façon assez agressive.
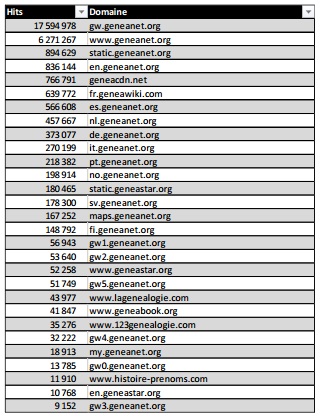
La série de sous-domaines gw0, gw1, etc… utilisée pour faire du Load Balancing entrainait une dilution du budget de crawl à la défaveur du www
Les logs peuvent en dire long sur la façon dont les moteurs et les internautes perçoivent votre site. L’analyse de logs constitue un complément essentiel aux études de structure et d’analyse d’audience. Sans les logs impossible par exemple de connaitre le nombre de hits sur les fichiers media (images, PDF, JS, CSS…) ou sur certaines pages d’erreur serveur généralement non trackées par les outils de mesure d’audience…
Si vous avez un projet d’analyse de logs, ou constatez des anomalies dans les rapports de crawl de la Search Console n’hésitez pas à nous solliciter !
Et vous, avez-vous déjà observé des choses insolites en décortiquant les hits de Googlebot ?

